教主黄仁勋亮相GTC China:英伟达已售出15亿块GPU!重磅发布TensorRT 7

新智元报道
新智元编辑部
又到了一年一度的英伟达GTC China大会,NVIDIA 创始人兼首席执行官黄仁勋又是一身黑色皮衣亮相苏州,为大家分享了英伟达取得的成绩:NVIDIA已经售出15亿块GPU。

据悉,这是有史以来参会人数最多的一次,现场有超过6100人参会,比三年前增长了250%。
黄教主一口气讲了两个多小时,先奉上黄仁勋这次的演讲重点:
NVIDIA加速计算,持续加速着图形,HPC及AI领域的计算任务。
在过去的一年中,又有三大类应用成功运行在了 NVIDIA 的平台上:光线追踪(RTX),5G(Aerial),以及最新的基因组处理(Parabricks)。
NVIDIA 与腾讯 Start 团队携手将游戏带到了云端。
NVIDIA与 ARM平台现在可以结合进行高性能计算。
在人工智能领域,推荐系统是驱动互联网的引擎,现在通过深度推荐网络,这类最重要的应用可以获益于 GPU 的加速。
TensorRT 7 现在可以加速所有种类模型的线上推理-CNN,Transformer & RNN网络
运用 TRT7,对话式AI现在可以变得有互动性和更加自然。
Orin 是NVIDIA最新的机器人平台芯片——更快,可以处理更高精度的传感器感知数据,以及拥有世界级的安全和防范能力。
在创建下一代人工智能——智能机器人——的征途上,NVIDIA的 Isaac SDK 提供了模拟仿真和训练的平台,开放了计算能力,多种预训练模型,及多种参考应用样例。
重磅发布TensorRT 7,支持超千种计算变换
今天黄仁勋也正式发布了TensorRT 7,并称其是“我们实现的最大飞跃”。
TensorRT是一种计算图优化编译器,以如TensorFlow等深度学习框架训练得到的模型作为输入,为CUDA GPU生成优化了的模型运行时。
TensorRT 通过寻找计算图中可以融合的节点和边,从而减少计算和内存访问。
去年在GTC China大会上,英伟达发布了TensorRT 5,支持自动低精度推理,将FP32模型转换成FP16或INT8模型,而不损失准确率。
但TensorRT 5仅支持CNN,这是一个不足,因为大多数语音模型需要RNN的支持,而语音推理需要大量的工作负载。
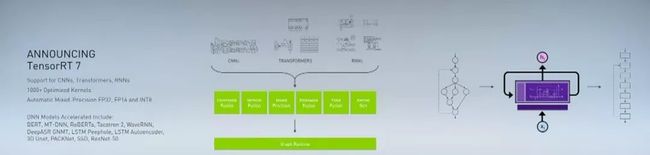
今天发布的TensorRT 7解决了这一不足,它支持各种类型的RNN,Transformer 和 CNN。相比TRT5 只支持30种模型,TRT 7能够支持多达1000种不同的计算变换和优化,包括最新的BERT、RoBERTa等。
TensorRT 7能够融合水平和垂直方向的运算,可以为开发者设计的大量RNN配置自动生成代码,逐点融合LSTM单元,甚至可跨多个时间步长进行融合。并且尽可能做自动低精度推理。
那么,TensorRT 7能做什么?
TensorRT 7强大功能的典型代表是支持交互式会话AI。作为NVIDIA第七代推理软件开发套件,它为实现更加智能的AI人机交互打开了新大门,从而能够实现与语音代理、聊天机器人和推荐引擎等应用进行实时互动。
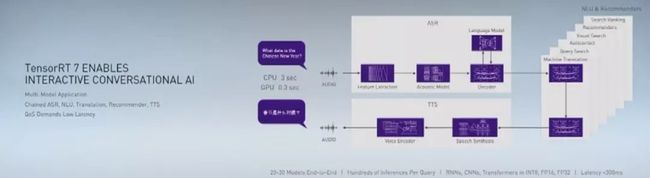
AI在语音和自然语言理解方面的突破使会话AI成为可能,但会话是交互式、应答式的,因此低延迟至关重要。
一套端到端的流程可能由二三十种模型组成,用到不同的模型结构,包括CNN、RNN、transformer、自编码器、MLP等。
TensorRT 7内置新型深度学习编译器,该编译器能够自动优化和加速递归神经网络与基于Transformer的神经网络。
使用CPU推理,这样一套流程的延迟是3秒。现在,使用TensorRT 7,我们可以对所有模型进行编译,使其在NVIDIA GPU上运行。T4 GPU上推理会话AI只需要0.3秒。与在CPU上运行时相比,会话式AI组件速度提高了10倍以上,从而将延迟降低到实时交互所需的300毫秒阈值以下。
黄仁勋在主题演讲中表示:“我们已进入了一个机器可以实时理解人类语言的AI新时代。TensorRT 7使这成为可能,为世界各地的开发者提供工具,使他们能够构建和部署更快、更智能的会话式AI服务,从而实现更自然的AI人机交互。”
自主机器平台DRIVE AGX Orin,全面助力L2-L5自动驾驶
本次发布平台名为NVIDIA DRIVE AGX Orin。内置全新Orin系统级芯片,晶体管数量达到170亿个,集成NVIDIA新一代GPU架构和Arm Hercules CPU内核以及全新深度学习和计算机视觉加速器,每秒可运行200万亿次计算,几乎是NVIDIA上一代Xavier系统级芯片性能的7倍。

Orin可处理在自动驾驶汽车和机器人中同时运行的大量应用和深度神经网络,能够支持从L2级到L5级完全自动驾驶汽车开发的兼容架构平台,助力OEM开发大型复杂的软件产品系列。由于Orin和Xavier均可通过开放的CUDA、TensorRT API及各类库进行编程,因此开发者能够在一次性投资后使用跨多代的产品。
NVIDIA创始人兼首席执行官黄仁勋表示:“打造安全的自动驾驶汽车,也许是当今社会所面临的最大计算挑战。实现自动驾驶汽车所需的投入呈指数级增长,面对复杂的开发任务,像Orin这样的可扩展、可编程、软件定义的AI平台不可或缺。”
Navigant Research首席研究分析师Sam Abuelsamid表示:“ NVIDIA对交通运输行业的长期承诺,以及其创新的端对端平台和工具,已经构成了一个广阔的生态系统。几乎每家自动驾驶汽车领域的企业,都在其计算堆栈中使用NVIDIA的解决方案。Orin可以看作是整个行业向前迈出的重要一步,它将帮助我们在这个技术不断发展的行业中书写新的篇章。”
NVIDIA DRIVE AGX Orin系列将包含一系列基于单一架构的配置,并将于2022年开始投产。
新版Isaac软件开发套件,为构建自主机器统一平台树立里程
NVIDIA发布全新版本Isaac软件开发套件(SDK),为机器人提供更新的AI感知和仿真功能。
Isaac SDK包括Isaac Robotics Engine(提供应用程序框架),Isaac GEM(预先构建的深度神经网络模型、算法、库、驱动程序和API),用于室内物流的参考应用程序以及Isaac Sim的第一个版本(提供导航功能)。

为了加快AI机器人的开发速度,全新Isaac SDK包括各种基于摄像头的感知深度神经网络。其中:
对象检测——识别用于导航、交互或操控的对象
自由空间分割——检测和分割外部世界,例如确定人行道在哪里,以及机器人可以在哪里行驶
3D姿态估计——了解目标的位置和方向,从而实现诸如机械臂拾取物体的任务
2D人体姿态估计——将姿态估计应用于人,这对于与人互动的机器人(例如配送机器人)和协作机器人(专门设计用于与人合作)非常重要
推出Isaac Sim
新版本引入了一项重要功能——使用Isaac Sim训练机器人,并将所生成的软件部署到在现实世界中运行的真实机器人中。这有望大大加快机器人的开发速度,从而实现综合数据的训练。
多机器人Sim来了
全新SDK也提供了多机器人仿真。这使开发人员可以将多个机器人放入仿真环境中进行测试,以便它们学会彼此相关的工作。各个机器人可以在共享的虚拟环境中移动时,运行独立版本的Isaac导航软件堆栈。
Isaac与DeepStream集成
全新SDK还集成了对NVIDIA DeepStream软件的支持,该软件广泛用于处理分析功能。开发人员可以在支持机器人应用程序的边缘AI部署DeepStream和NVIDIA GPU,以实现对视频流的处理。
使用Isaac SDK进行编程
对于已经开发了自己代码的机器人开发人员,全新SDK也能集成他们的工作,并添加了基于C编程语言的新API。这使开发人员可以将自己的软件堆栈连接到Isaac SDK,并最大程度地减少编程语言转换——为用户提供通过C API访问路由的Isaac功能。
全新Isaac SDK可以大大加快研究人员、开发人员、初创企业和制造商开发和测试机器人的速度。它使机器人能够通过仿真获得由人工智能技术驱动的感知和训练功能,从而可以在各种环境和情况下对机器人进行测试和验证。这样一来,可以节省成本。可以说,在建立统一的机器人开发平台以实现AI、仿真和操控功能方面,Isaac SDK迈出了重要的里程碑。
从游戏,到出行:与腾讯、滴滴共建云上新世界

NVIDIA的GPU技术将为腾讯游戏的START云游戏服务赋力,让玩家可以随时随地,即使是在配置不足的设备上也能玩3A大作。
NVIDIA个人电脑业务高级副总裁Jeff Fisher表示:“作为全球领先的游戏开发、发行和运营平台之一,腾讯游戏将会推出出色的云游戏。将腾讯平台与NVIDIA的GPU技术相结合,将为全球各地的游戏玩家提供世界级的体验。”
腾讯游戏高级副总裁马晓轶表示:“NVIDIA打造了全球最强大的GPU,是GPU领域的领导者,又具有云解决方案方面的经验,这两大优势能够帮助我们将START平台扩展到数百万玩家。今天对于我们公司来说是一个新的契机,我们将进一步扩大我们在游戏市场的疆域。”
NVIDIA和腾讯游戏还宣布成立一个游戏联合创新实验室。双方将共同探索AI在游戏、游戏引擎优化和新光照技术(包括光线追踪和光线烘焙)中的新应用。

另外,NVIDIA和滴滴今日宣布,滴滴将使用NVIDIA GPU和其他技术开发自动驾驶和云计算解决方案,双方在L4自动驾驶合作。
滴滴将在数据中心使用NVIDIA GPU训练机器学习算法,并采用NVIDIA DRIVE为其L4级自动驾驶汽车提供推理能力。滴滴在8月将其自动驾驶部门升级为独立公司,并与产业链合作伙伴开展广泛合作。
作为滴滴自动驾驶AI处理的一部分,NVIDIA DRIVE借助多个深度神经网络融合来自各类传感器(摄像头、激光雷达、雷达等)的数据,从而实现对汽车周围环境360度全方位的理解,并规划出安全的行驶路径。
NVIDIA自动驾驶汽车副总裁Rishi Dhall表示:“不论是在云端还是汽车中,开发安全的自动驾驶技术,端到端的AI都不可或缺。借助NVIDIA的AI技术,滴滴将能够开发更安全高效的交通运输系统,并提供丰富的云服务。”
为了训练这些深度神经网络,滴滴将采用NVIDIA GPU数据中心服务器。在云计算方面,滴滴还将构建领先的AI基础架构,并推出计算型、渲染型和游戏型vGPU云服务器。
* 凡来源非注明“机器学习算法与Python学习原创”的所有作品均为转载稿件,其目的在于促进信息交流,并不代表本公众号赞同其观点或对其内容真实性负责。
推荐阅读
新预训练模型CodeBERT出世,编程语言和自然语言都不在话下,哈工大、中山大学、MSRA出品
资源 | 新书400页PDF《TensorFlow深度学习》免费下载!
手把手教你用 Transformers 和 Tokenizers 从头训练新语言模型
太突然!北大方正破产了!负债3029亿元!
用 Python 手写十大经典排序算法
639页《Deep Learning》硬核教程!
