语义分割算法Mask RCNN论文解读
论文名称:Mask R-CNN
论文地址:https://arxiv.org/abs/1703.06870
代码地址:https://github.com/matterport/Mask_RCNN
summary:
object detection + semantic segmentation = instance segmentation
masked rcnn achieves instance segmentation
faster rcnn + fcn = masked rcnn
roi align preserves spatial orientation of features with no loss of data
- 对于每个ROI,Faster RCNN都有两个输出,一个类标签和一个边界框偏移量,Mask RCNN以Faster RCNN原型,添加了第三个分支,即语义分割分支。
- 用RoiAlign代替了RoiPooling,利用双线性插值,进行像素级别的对齐。
- 实例分割。FCN是对每类物体进行分割,而Mask RCNN利用目标识别,对类别中每个实例进行分割。
- Mask RCNN相当于1个候选框做一个FCN。
- 损失函数定义是实例分割的关键。对于每个ROI,mask分支都有一个
 维的输出(每个像素的类别),分辨率为m×m,一共k类,在每个pixel上使用sigmoid,相当于在每个ROI上做FCN。并将Loss(mask)定义为二元交叉熵损失,允许网络为每个类生成Mask,而不会在类之间产生竞争,用分类分支来预测Mask的类标签,这将mask和类预测分离。
维的输出(每个像素的类别),分辨率为m×m,一共k类,在每个pixel上使用sigmoid,相当于在每个ROI上做FCN。并将Loss(mask)定义为二元交叉熵损失,允许网络为每个类生成Mask,而不会在类之间产生竞争,用分类分支来预测Mask的类标签,这将mask和类预测分离。 - 网络结构图如下:

一、论文解读
1、对Faster RCNN扩展
Mask RCNN以Faster RCNN原型,增加了一个分支用于分割任务,对于Faster RCNN的每个Proposal Box都要使用FCN进行语义分割。分割任务与定位、分类任务是同时进行的。
2、实例分割
FCN是对每类物体进行分割,而Mask RCNN利用目标识别,对类别中每个实例进行分割。实例分割不仅要正确的找到图像中的objects,还要对其精确的分割,所以实例分割可以看做物体检测和语义分割的结合。rcnn系列的分割是,先提出候选分割块,然后由Fast RCNN分类,分割优先于识别,这是缓慢和不准确的;另一个解决方案系列的实例分割是由语义分割的成功驱动的,从每像素分类结果(例如,FCN输出)开始,这些方法尝试将同一类别的像素分割为不同的实例;而本文的Mask RCNN基于实例优先策略。
3、RoiAlign
Faster RCNN的RoiPooling采用最近邻插法,将特征图池化成固定大小,这种量化会导致ROI和提取的特征之间的偏差,特征提取的比较粗糙,因为RoI Pooling并不是按照像素一一对齐的(pixel-to-pixel alignment),也许这对bbox的影响不是很大,但对于mask的精度却有很大影响。所以提出了用RoiAlign代替Faster RCNN中的RoI Pooling。RoiAlign使用了双线性插值,精确度更高。RoiAlign内容可参考:https://blog.csdn.net/qq_32172681/article/details/99734978
4、RCNN系列复习
(1)基于区域的RCNN对目标检测的方法是,产生一系列候选框,并对每个Roi独立评估。
(2)Fast RCNN只对图像进行一次卷积,避免候选框的重复计算,并且采用roipooling提高了预测精度。
(3)Faster RCNN用rpn代替selective search提取候选框,进一步提升了性能。faster R-CNN包括两个阶段,第一阶段,称为区域建议网络(RPN),提出了候选对象边界框。第二阶段,本质上是Fast R-CNN,使用RoiPooling从每个候选框中提取特性,并执行分类和边界框回归。
5、Mask RCNN
对于每个ROI,Faster RCNN都有两个输出,一个类标签和一个边界框偏移量,我们添加了第三个分支,即语义分割分支。但是语义分割输出不同于类和框输出,需要提取对象更精细的空间布局,由此引入了pixel-to-pixel的对齐--RoiAlign,这是Fast/Faster R-CNN所没有的部分。Mask R-CNN也采用两阶段算法,第一阶段(即RPN)相同。在第二阶段,除了预测类和box偏移量外,Mask RCNN还为每个ROI输出一个二进制mask。
6、Mask RCNN损失定义
在训练期间,将每个ROI上的损失定义为:
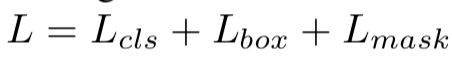
其中:分类损失L(cls)和框回归损失L(box)与fast rcnn中定义的相同。对于每个ROI,mask分支都有一个维的输出,分辨率为m×m,一共k类。在每个pixel上使用sigmoid,并将L(mask)定义为平均二元交叉熵损失。只对有真值的mask做损失,其他Mask输出不造成损失。对L(mask)的定义允许网络为每个类生成Mask,而不会在类之间产生竞争,我们依赖专用的分类分支来预测用于选择输出Mask的类标签,这将mask和类预测分离。与FCN不同,FCN通常使用每像素的Softmax和多重交叉熵损失,在这种情况下,跨类的mask会竞争;在我们的情况下,每像素的sigmoid和二元交叉熵损失不会竞争。实验表明,该方法是实现实例分割效果的关键。
共有5部分损失:rpn cls loss、rpn bbox loss、mrcnn cls loss、mrcnn bbox loss、mrcnn mask loss,其中只有positive example有bbox loss和mask loss
7、使用FCN预测每个ROI的m×m mask
使用FCN预测每个ROI的m×m mask,(与类标签或框偏移被全连接层输出相同长度的特征向量不同),它允许mask分支中的每个层保持m×m pixel的空间布局,而不会将其折叠成缺少空间维度的向量表示。这像素级别的预测,要求我们的ROI特征图能够很好地对齐,以正确的保持每像素的空间相关性,这促使我们开发了在mask预测中起关键作用的RoiAlign层。
8、网络结构(重点)
基于resnet101的FPN + RPN
(1)输入图片,获取Resnet特征图
取出图像,输入图像至resnet101,使用hook取出{C2,C3,C4,C5}层的feature maps,不选用C1层在FPN论文中提到是因为存在large memory footprint,而根据实践来看,本身RPN网络的计算不会消耗过多时间,但是feature maps中数据的存取会消耗很多时间(以至于我真的不想做FPN,尤其是第二阶段的mask判定会消耗更多训练时间)
假设输入原始图片大小为(H,W,3),经过resnet101后
C2的feature maps是(H/4,W/4,256)
C3为(H/8,W/8,512)
C4为(H/16,W/16,1024)
C5为(H/32,W/32,2048)
feature maps 的集合称为{C2,C3,C4,C5}
(2)特征图处理,生成P
对{C2,C3,C4,C5}每层分别使用卷积,生成特征图I,即
I2 = conv2d(input_dim = 256,output_dim = 256,kernel_size = (1,1))
I3 = conv2d(input_dim = 512,output_dim = 256,kernel_size = (1,1))
I4 = conv2d(input_dim = 1024,output_dim = 256,kernel_size = (1,1))
I5 = conv2d(input_dim = 2048,output_dim = 256,kernel_size = (1,1))
{I2,I3,I4,I5}转{M2,M3,M4,M5}
为了混合不同层次的特征,将高层进行上采样与低层结合
M5 = I5
M4 = I4 + X2I5
M3 = I3 + X2I4
M2 = I2 + X2I3
由于{M2,M3,M4,M5}是由I叠加得来的,为了消除抗混叠效应,对M做一次卷积,生成P
P = conv2d(input_dim = 256,output_dim = 256,kernel = (3,3))输入为M
额外地下采样(论文中使用maxpooling)生成P6
全过程如下
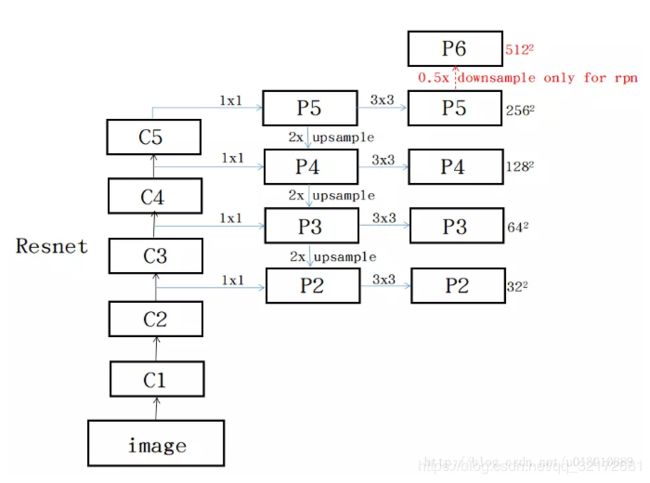
至此已经获得了[P2,P3,P4,P5,P6]
(3)RPN_head扫描[P2,P3,P4,P5,P6]
RPN_head是一个较为简单的层,为nn.Conv2d(256,256,3,padding=1),将P2P3P4P5P6依次通过后,结果将分别进入cls 和 reg两个子网络用于区域建议
(4)cls_layer与reg_layer分别读取刚才通过RPNhead的信息
cls是nn.Conv2d(256, 6, 1),输入是256维与RPNhead输出对齐,输出是6维,kernel为(1,1)简写为1,分别对应了3个形状的anchor对应的2种概率:形状:[1:1,1:2,2:1] 概率:[Pobj,Pnoobj]
reg是nn.Conv2d(256,12,1)输入同样与RPNhead对齐,输出是12维对应了3种形状的anchor与4个值[δx,δy,δh,δw]
δx δy是当前anchor中心xy坐标应当上下左右移动的修正量,在这里可以用δx * anchor_w来获得移动距离,当δx为0代表不需要移动
δh δw是伸缩的比例,可以用exp(δh)表示h需要放缩的倍率,δw同理
(5)生成建议区域
结合下文理论1,在P2层的anchor中心坐标对应原图中心坐标,面积对应,长宽比也对应,就能得到面积为322的概率与修正方向
同理,P3层也如此,直到能够获得各种大小各种形状的anchor的[Pobj,Pnoobj]
此时,将anchor的[x,y,h,w]与对应的reg层[δx,δy,δh,δw]计算获得网络修正后的区域
但是此时,我们是不知道修正后区域的confidence的,我们取与修正区域形状面积最相似的anchor,这个anchor的confidence就是修正区域的confidence,然后我们就有了,建议区域和对应的置信度
(6)选择合适的建议区域作为最终输出
在一张输入图片中,我们很有可能会获得很多建议区域,少则200多则10w+,由于在mask rcnn后阶段训练时,FPN只需要512个区域作为输入,测试时也只需要2k个建议区域,所以在此我们要剔除一些效果不怎么好的建议区域,筛选逻辑为
1.越过边界的区域
2.与其他区域重合过多,同时置信度不高的区域
1.由于最终建议区域是以anchor与δanchor计算生成的区域,会有一定数量的区域最终计算结果超越原图的边界,在此可以直接剔除,或者将稍微越过的部分修正而删除大部分越界的ROI
2.NMS算法筛选
NMS简单而言,对于预测种类相同的区域,取最高置信度区域,其他与其重合度较高的区域全部删除,如上图中,所有红色都被识别为人脸,取置信度最高的区域,删去其他区域
但是在RPN中,我们没有区域的分类信息,所以只需要取置信度最高的区域,重合度较高的区域都可以删去
至此,RPN的工作便全部完成,输出RoI用于mask Rcnn后半部分使用
(7)Pyramid ROI pooling层
mrcnn_feature_maps = [P2, P3, P4, P5](rpn_feature_maps = [P2, P3, P4, P5, P6])
对不同level的特征图进行Roi pooling,得到7*7的特征图
(8)mrcnn_head分别做cls_layer、reg_layer、mask_layer
mrcnn_head对roi pooling的结果进行卷积、全连接得到cls_layer、reg_layer分支的预测结果。
而mask分支需要输出原图大小的像素图,所以它对roi pooling的结果进行卷积+反卷积,得到mask_layer分支的预测结果。
9、思考:为什么Mask RCNN可以做到实例分割,而FCN不行?
(1)首先,Mask RCNN借用了Faster RCNN的框架,先将可能存在目标的候选框选择出来,再进行分割,相当于对每个roi做一次FCN(而FCN只对不同类别的物体加以区分)。
(2)其次,Mask RCNN分割分支输出为,K为类别数,也就是输出每个类别的分割图,类别输出是在另外的类别分支,消除了类别间的竞争(而FCN直接取1000张特征图中最大可能性的像素,引起了类别间的竞争)。
二、主要代码解读
1、网络结构

(1)FPN提取公共特征部分代码,根据输入图像得到[P2, P3, P4, P5, P6]:
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True,
train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE,
stage5=True, train_bn=config.TRAIN_BN)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)(2)用于提取候选框的RPN网络
def rpn_graph(feature_map, anchors_per_location, anchor_stride):
"""Builds the computation graph of Region Proposal Network.
feature_map: backbone features [batch, height, width, depth]
anchors_per_location: number of anchors per pixel in the feature map
anchor_stride: Controls the density of anchors. Typically 1 (anchors for
every pixel in the feature map), or 2 (every other pixel).
Returns:
rpn_class_logits: [batch, H * W * anchors_per_location, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, H * W * anchors_per_location, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H * W * anchors_per_location, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
"""
# TODO: check if stride of 2 causes alignment issues if the feature map
# is not even.
# Shared convolutional base of the RPN
shared = KL.Conv2D(512, (3, 3), padding='same', activation='relu',
strides=anchor_stride,
name='rpn_conv_shared')(feature_map)
# Anchor Score. [batch, height, width, anchors per location * 2].
x = KL.Conv2D(2 * anchors_per_location, (1, 1), padding='valid',
activation='linear', name='rpn_class_raw')(shared)
# Reshape to [batch, anchors, 2]
rpn_class_logits = KL.Lambda(
lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 2]))(x)
# Softmax on last dimension of BG/FG.
rpn_probs = KL.Activation(
"softmax", name="rpn_class_xxx")(rpn_class_logits)
# Bounding box refinement. [batch, H, W, anchors per location * depth]
# where depth is [x, y, log(w), log(h)]
x = KL.Conv2D(anchors_per_location * 4, (1, 1), padding="valid",
activation='linear', name='rpn_bbox_pred')(shared)
# Reshape to [batch, anchors, 4]
rpn_bbox = KL.Lambda(lambda t: tf.reshape(t, [tf.shape(t)[0], -1, 4]))(x)
return [rpn_class_logits, rpn_probs, rpn_bbox](3)筛选候选框的proposal layer部分代码:
class ProposalLayer(KE.Layer):
"""Receives anchor scores and selects a subset to pass as proposals
to the second stage. Filtering is done based on anchor scores and
non-max suppression to remove overlaps. It also applies bounding
box refinement deltas to anchors.
Inputs:
rpn_probs: [batch, num_anchors, (bg prob, fg prob)]
rpn_bbox: [batch, num_anchors, (dy, dx, log(dh), log(dw))]
anchors: [batch, num_anchors, (y1, x1, y2, x2)] anchors in normalized coordinates
Returns:
Proposals in normalized coordinates [batch, rois, (y1, x1, y2, x2)]
"""
def __init__(self, proposal_count, nms_threshold, config=None, **kwargs):
super(ProposalLayer, self).__init__(**kwargs)
self.config = config
self.proposal_count = proposal_count
self.nms_threshold = nms_threshold
def call(self, inputs):
# Box Scores. Use the foreground class confidence. [Batch, num_rois, 1]
scores = inputs[0][:, :, 1]
# Box deltas [batch, num_rois, 4]
deltas = inputs[1]
deltas = deltas * np.reshape(self.config.RPN_BBOX_STD_DEV, [1, 1, 4])
# Anchors
anchors = inputs[2]
# Improve performance by trimming to top anchors by score
# and doing the rest on the smaller subset.
pre_nms_limit = tf.minimum(self.config.PRE_NMS_LIMIT, tf.shape(anchors)[1])
ix = tf.nn.top_k(scores, pre_nms_limit, sorted=True,
name="top_anchors").indices
scores = utils.batch_slice([scores, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
deltas = utils.batch_slice([deltas, ix], lambda x, y: tf.gather(x, y),
self.config.IMAGES_PER_GPU)
pre_nms_anchors = utils.batch_slice([anchors, ix], lambda a, x: tf.gather(a, x),
self.config.IMAGES_PER_GPU,
names=["pre_nms_anchors"])
# Apply deltas to anchors to get refined anchors.
# [batch, N, (y1, x1, y2, x2)]
boxes = utils.batch_slice([pre_nms_anchors, deltas],
lambda x, y: apply_box_deltas_graph(x, y),
self.config.IMAGES_PER_GPU,
names=["refined_anchors"])
# Clip to image boundaries. Since we're in normalized coordinates,
# clip to 0..1 range. [batch, N, (y1, x1, y2, x2)]
window = np.array([0, 0, 1, 1], dtype=np.float32)
boxes = utils.batch_slice(boxes,
lambda x: clip_boxes_graph(x, window),
self.config.IMAGES_PER_GPU,
names=["refined_anchors_clipped"])
# Filter out small boxes
# According to Xinlei Chen's paper, this reduces detection accuracy
# for small objects, so we're skipping it.
# Non-max suppression
def nms(boxes, scores):
indices = tf.image.non_max_suppression(
boxes, scores, self.proposal_count,
self.nms_threshold, name="rpn_non_max_suppression")
proposals = tf.gather(boxes, indices)
# Pad if needed
padding = tf.maximum(self.proposal_count - tf.shape(proposals)[0], 0)
proposals = tf.pad(proposals, [(0, padding), (0, 0)])
return proposals
proposals = utils.batch_slice([boxes, scores], nms,
self.config.IMAGES_PER_GPU)
return proposals(4)Pyramid ROI Pooling层,不同level的feature map做ROI pooling
class PyramidROIAlign(KE.Layer):
"""Implements ROI Pooling on multiple levels of the feature pyramid.
Params:
- pool_shape: [pool_height, pool_width] of the output pooled regions. Usually [7, 7]
Inputs:
- boxes: [batch, num_boxes, (y1, x1, y2, x2)] in normalized
coordinates. Possibly padded with zeros if not enough
boxes to fill the array.
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
- feature_maps: List of feature maps from different levels of the pyramid.
Each is [batch, height, width, channels]
Output:
Pooled regions in the shape: [batch, num_boxes, pool_height, pool_width, channels].
The width and height are those specific in the pool_shape in the layer
constructor.
"""
def __init__(self, pool_shape, **kwargs):
super(PyramidROIAlign, self).__init__(**kwargs)
self.pool_shape = tuple(pool_shape)
def call(self, inputs):
# Crop boxes [batch, num_boxes, (y1, x1, y2, x2)] in normalized coords
boxes = inputs[0]
# Image meta
# Holds details about the image. See compose_image_meta()
image_meta = inputs[1]
# Feature Maps. List of feature maps from different level of the
# feature pyramid. Each is [batch, height, width, channels]
feature_maps = inputs[2:]
# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Use shape of first image. Images in a batch must have the same size.
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
roi_level = tf.squeeze(roi_level, 2)
# Loop through levels and apply ROI pooling to each. P2 to P5.
pooled = []
box_to_level = []
for i, level in enumerate(range(2, 6)):
ix = tf.where(tf.equal(roi_level, level))
level_boxes = tf.gather_nd(boxes, ix)
# Box indices for crop_and_resize.
box_indices = tf.cast(ix[:, 0], tf.int32)
# Keep track of which box is mapped to which level
box_to_level.append(ix)
# Stop gradient propogation to ROI proposals
level_boxes = tf.stop_gradient(level_boxes)
box_indices = tf.stop_gradient(box_indices)
# Crop and Resize
# From Mask R-CNN paper: "We sample four regular locations, so
# that we can evaluate either max or average pooling. In fact,
# interpolating only a single value at each bin center (without
# pooling) is nearly as effective."
#
# Here we use the simplified approach of a single value per bin,
# which is how it's done in tf.crop_and_resize()
# Result: [batch * num_boxes, pool_height, pool_width, channels]
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
# Pack pooled features into one tensor
pooled = tf.concat(pooled, axis=0)
# Pack box_to_level mapping into one array and add another
# column representing the order of pooled boxes
box_to_level = tf.concat(box_to_level, axis=0)
box_range = tf.expand_dims(tf.range(tf.shape(box_to_level)[0]), 1)
box_to_level = tf.concat([tf.cast(box_to_level, tf.int32), box_range],
axis=1)
# Rearrange pooled features to match the order of the original boxes
# Sort box_to_level by batch then box index
# TF doesn't have a way to sort by two columns, so merge them and sort.
sorting_tensor = box_to_level[:, 0] * 100000 + box_to_level[:, 1]
ix = tf.nn.top_k(sorting_tensor, k=tf.shape(
box_to_level)[0]).indices[::-1]
ix = tf.gather(box_to_level[:, 2], ix)
pooled = tf.gather(pooled, ix)
# Re-add the batch dimension
shape = tf.concat([tf.shape(boxes)[:2], tf.shape(pooled)[1:]], axis=0)
pooled = tf.reshape(pooled, shape)
return pooled
def compute_output_shape(self, input_shape):
return input_shape[0][:2] + self.pool_shape + (input_shape[2][-1], )(5)mrcnn 目标检测分支代码,输出类别、框位置
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
"""Builds the computation graph of the feature pyramid network classifier
and regressor heads.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
fc_layers_size: Size of the 2 FC layers
Returns:
logits: [batch, num_rois, NUM_CLASSES] classifier logits (before softmax)
probs: [batch, num_rois, NUM_CLASSES] classifier probabilities
bbox_deltas: [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
"""
# ROI Pooling
# Shape: [batch, num_rois, POOL_SIZE, POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Two 1024 FC layers (implemented with Conv2D for consistency)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x)
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# [batch, num_rois, NUM_CLASSES * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, num_rois, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox(6)mrcnn 分割分支代码,输出mask(实例分割,有多少个实例,就输出多少个mask)
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True):
"""Builds the computation graph of the mask head of Feature Pyramid Network.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
Returns: Masks [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, NUM_CLASSES]
"""
""" pyramid ROI Pooling """
# Shape: [batch, num_rois, MASK_POOL_SIZE, MASK_POOL_SIZE, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_mask")([rois, image_meta] + feature_maps)
# Conv layers
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv1")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv2")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv3")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn3')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv4")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn4')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2DTranspose(256, (2, 2), strides=2, activation="relu"),
name="mrcnn_mask_deconv")(x)
x = KL.TimeDistributed(KL.Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid"),
name="mrcnn_mask")(x)
return x
2、target定义
(1)计算detection targets,共有TRAIN_ROIS_PER_IMAGE个预测值
(其中class_ids为类别、deltas为bbox的回归目标、masks为分割任务的回归目标)
def build_detection_targets(rpn_rois, gt_class_ids, gt_boxes, gt_masks, config):
"""Generate targets for training Stage 2 classifier and mask heads.
This is not used in normal training. It's useful for debugging or to train
the Mask RCNN heads without using the RPN head.
Inputs:
rpn_rois: [N, (y1, x1, y2, x2)] proposal boxes.
gt_class_ids: [instance count] Integer class IDs
gt_boxes: [instance count, (y1, x1, y2, x2)]
gt_masks: [height, width, instance count] Ground truth masks. Can be full
size or mini-masks.
Returns:
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)]
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs.
bboxes: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (y, x, log(h), log(w))]. Class-specific
bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width, NUM_CLASSES). Class specific masks cropped
to bbox boundaries and resized to neural network output size.
"""
assert rpn_rois.shape[0] > 0
assert gt_class_ids.dtype == np.int32, "Expected int but got {}".format(
gt_class_ids.dtype)
assert gt_boxes.dtype == np.int32, "Expected int but got {}".format(
gt_boxes.dtype)
assert gt_masks.dtype == np.bool_, "Expected bool but got {}".format(
gt_masks.dtype)
# It's common to add GT Boxes to ROIs but we don't do that here because
# according to XinLei Chen's paper, it doesn't help.
# Trim empty padding in gt_boxes and gt_masks parts
instance_ids = np.where(gt_class_ids > 0)[0]
assert instance_ids.shape[0] > 0, "Image must contain instances."
gt_class_ids = gt_class_ids[instance_ids]
gt_boxes = gt_boxes[instance_ids]
gt_masks = gt_masks[:, :, instance_ids]
# Compute areas of ROIs and ground truth boxes.
rpn_roi_area = (rpn_rois[:, 2] - rpn_rois[:, 0]) * \
(rpn_rois[:, 3] - rpn_rois[:, 1])
gt_box_area = (gt_boxes[:, 2] - gt_boxes[:, 0]) * \
(gt_boxes[:, 3] - gt_boxes[:, 1])
# Compute overlaps [rpn_rois, gt_boxes]
overlaps = np.zeros((rpn_rois.shape[0], gt_boxes.shape[0]))
for i in range(overlaps.shape[1]):
gt = gt_boxes[i]
overlaps[:, i] = utils.compute_iou(
gt, rpn_rois, gt_box_area[i], rpn_roi_area)
# Assign ROIs to GT boxes
rpn_roi_iou_argmax = np.argmax(overlaps, axis=1)
rpn_roi_iou_max = overlaps[np.arange(
overlaps.shape[0]), rpn_roi_iou_argmax]
# GT box assigned to each ROI
rpn_roi_gt_boxes = gt_boxes[rpn_roi_iou_argmax]
rpn_roi_gt_class_ids = gt_class_ids[rpn_roi_iou_argmax]
# Positive ROIs are those with >= 0.5 IoU with a GT box.
fg_ids = np.where(rpn_roi_iou_max > 0.5)[0]
# Negative ROIs are those with max IoU 0.1-0.5 (hard example mining)
# TODO: To hard example mine or not to hard example mine, that's the question
# bg_ids = np.where((rpn_roi_iou_max >= 0.1) & (rpn_roi_iou_max < 0.5))[0]
bg_ids = np.where(rpn_roi_iou_max < 0.5)[0]
# Subsample ROIs. Aim for 33% foreground.
# FG
fg_roi_count = int(config.TRAIN_ROIS_PER_IMAGE * config.ROI_POSITIVE_RATIO)
if fg_ids.shape[0] > fg_roi_count:
keep_fg_ids = np.random.choice(fg_ids, fg_roi_count, replace=False)
else:
keep_fg_ids = fg_ids
# BG
remaining = config.TRAIN_ROIS_PER_IMAGE - keep_fg_ids.shape[0]
if bg_ids.shape[0] > remaining:
keep_bg_ids = np.random.choice(bg_ids, remaining, replace=False)
else:
keep_bg_ids = bg_ids
# Combine indices of ROIs to keep
keep = np.concatenate([keep_fg_ids, keep_bg_ids])
# Need more?
remaining = config.TRAIN_ROIS_PER_IMAGE - keep.shape[0]
if remaining > 0:
# Looks like we don't have enough samples to maintain the desired
# balance. Reduce requirements and fill in the rest. This is
# likely different from the Mask RCNN paper.
# There is a small chance we have neither fg nor bg samples.
if keep.shape[0] == 0:
# Pick bg regions with easier IoU threshold
bg_ids = np.where(rpn_roi_iou_max < 0.5)[0]
assert bg_ids.shape[0] >= remaining
keep_bg_ids = np.random.choice(bg_ids, remaining, replace=False)
assert keep_bg_ids.shape[0] == remaining
keep = np.concatenate([keep, keep_bg_ids])
else:
# Fill the rest with repeated bg rois.
keep_extra_ids = np.random.choice(
keep_bg_ids, remaining, replace=True)
keep = np.concatenate([keep, keep_extra_ids])
assert keep.shape[0] == config.TRAIN_ROIS_PER_IMAGE, \
"keep doesn't match ROI batch size {}, {}".format(
keep.shape[0], config.TRAIN_ROIS_PER_IMAGE)
# Reset the gt boxes assigned to BG ROIs.
rpn_roi_gt_boxes[keep_bg_ids, :] = 0
rpn_roi_gt_class_ids[keep_bg_ids] = 0
# For each kept ROI, assign a class_id, and for FG ROIs also add bbox refinement.
rois = rpn_rois[keep]
roi_gt_boxes = rpn_roi_gt_boxes[keep]
roi_gt_class_ids = rpn_roi_gt_class_ids[keep]
roi_gt_assignment = rpn_roi_iou_argmax[keep]
# Class-aware bbox deltas. [y, x, log(h), log(w)]
bboxes = np.zeros((config.TRAIN_ROIS_PER_IMAGE,
config.NUM_CLASSES, 4), dtype=np.float32)
pos_ids = np.where(roi_gt_class_ids > 0)[0]
bboxes[pos_ids, roi_gt_class_ids[pos_ids]] = utils.box_refinement(
rois[pos_ids], roi_gt_boxes[pos_ids, :4])
# Normalize bbox refinements
bboxes /= config.BBOX_STD_DEV
# Generate class-specific target masks
masks = np.zeros((config.TRAIN_ROIS_PER_IMAGE, config.MASK_SHAPE[0], config.MASK_SHAPE[1], config.NUM_CLASSES),
dtype=np.float32)
for i in pos_ids:
class_id = roi_gt_class_ids[i]
assert class_id > 0, "class id must be greater than 0"
gt_id = roi_gt_assignment[i]
class_mask = gt_masks[:, :, gt_id]
if config.USE_MINI_MASK:
# Create a mask placeholder, the size of the image
placeholder = np.zeros(config.IMAGE_SHAPE[:2], dtype=bool)
# GT box
gt_y1, gt_x1, gt_y2, gt_x2 = gt_boxes[gt_id]
gt_w = gt_x2 - gt_x1
gt_h = gt_y2 - gt_y1
# Resize mini mask to size of GT box
placeholder[gt_y1:gt_y2, gt_x1:gt_x2] = \
np.round(utils.resize(class_mask, (gt_h, gt_w))).astype(bool)
# Place the mini batch in the placeholder
class_mask = placeholder
# Pick part of the mask and resize it
y1, x1, y2, x2 = rois[i].astype(np.int32)
m = class_mask[y1:y2, x1:x2]
mask = utils.resize(m, config.MASK_SHAPE)
masks[i, :, :, class_id] = mask
return rois, roi_gt_class_ids, bboxes, masksdef detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
"""Generates detection targets for one image. Subsamples proposals and
generates target class IDs, bounding box deltas, and masks for each.
Inputs:
proposals: [POST_NMS_ROIS_TRAINING, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [MAX_GT_INSTANCES] int class IDs
gt_boxes: [MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized coordinates.
gt_masks: [height, width, MAX_GT_INSTANCES] of boolean type.
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, (dy, dx, log(dh), log(dw))]
masks: [TRAIN_ROIS_PER_IMAGE, height, width]. Masks cropped to bbox
boundaries and resized to neural network output size.
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
# Assertions
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
# Remove zero padding
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros,
name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2,
name="trim_gt_masks")
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
"""计算proposals和gt_boxes的IoU矩阵"""
overlaps = overlaps_graph(proposals, gt_boxes)
# Compute overlaps with crowd boxes [proposals, crowd_boxes]
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
"""IoU大于0.5为positive,小于0.5为negative"""
roi_iou_max = tf.reduce_max(overlaps, axis=1)
# 1. Positive ROIs are those with >= 0.5 IoU with a GT box
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
# 2. Negative ROIs are those with < 0.5 with every GT box. Skip crowds.
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
"""以33%的比例对rois进行下采样"""
# Positive ROIs
positive_count = int(config.TRAIN_ROIS_PER_IMAGE *
config.ROI_POSITIVE_RATIO)
positive_indices = tf.random_shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
# Negative ROIs. Add enough to maintain positive:negative ratio.
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random_shuffle(negative_indices)[:negative_count]
# Gather selected ROIs
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
"""为每个positive box指定一个ground_truth box"""
positive_overlaps = tf.gather(overlaps, positive_indices)
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
"""计算bbox回归目标deltas = [dy, dx, dh, dw]"""
deltas = utils.box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
"""为每个positive box指定一个ground_truth mask"""
# Permute masks to [N, height, width, 1]
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
# Pick the right mask for each ROI
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
"""计算mask回归目标"""
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
# Remove the extra dimension from masks.
masks = tf.squeeze(masks, axis=3)
# Threshold mask pixels at 0.5 to have GT masks be 0 or 1 to use with
# binary cross entropy loss.
masks = tf.round(masks)
# Append negative ROIs and pad bbox deltas and masks that
# are not used for negative ROIs with zeros.
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks(2)计算RPN网络的target,给定anchor和gt_boxes,计算IoU,辨别positive anchors和他们偏离gt_boxes的偏移
def build_rpn_targets(image_shape, anchors, gt_class_ids, gt_boxes, config):
"""Given the anchors and GT boxes, compute overlaps and identify positive
anchors and deltas to refine them to match their corresponding GT boxes.
anchors: [num_anchors, (y1, x1, y2, x2)]
gt_class_ids: [num_gt_boxes] Integer class IDs.
gt_boxes: [num_gt_boxes, (y1, x1, y2, x2)]
Returns:
rpn_match: [N] (int32) matches between anchors and GT boxes.
1 = positive anchor, -1 = negative anchor, 0 = neutral
rpn_bbox: [N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
"""
# RPN Match: 1 = positive anchor, -1 = negative anchor, 0 = neutral
rpn_match = np.zeros([anchors.shape[0]], dtype=np.int32)
# RPN bounding boxes: [max anchors per image, (dy, dx, log(dh), log(dw))]
rpn_bbox = np.zeros((config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4))
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
crowd_ix = np.where(gt_class_ids < 0)[0]
if crowd_ix.shape[0] > 0:
# Filter out crowds from ground truth class IDs and boxes
non_crowd_ix = np.where(gt_class_ids > 0)[0]
crowd_boxes = gt_boxes[crowd_ix]
gt_class_ids = gt_class_ids[non_crowd_ix]
gt_boxes = gt_boxes[non_crowd_ix]
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = utils.compute_overlaps(anchors, crowd_boxes)
crowd_iou_max = np.amax(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
else:
# All anchors don't intersect a crowd
no_crowd_bool = np.ones([anchors.shape[0]], dtype=bool)
# Compute overlaps [num_anchors, num_gt_boxes]
overlaps = utils.compute_overlaps(anchors, gt_boxes)
# Match anchors to GT Boxes
# If an anchor overlaps a GT box with IoU >= 0.7 then it's positive.
# If an anchor overlaps a GT box with IoU < 0.3 then it's negative.
# Neutral anchors are those that don't match the conditions above,
# and they don't influence the loss function.
# However, don't keep any GT box unmatched (rare, but happens). Instead,
# match it to the closest anchor (even if its max IoU is < 0.3).
#
# 1. Set negative anchors first. They get overwritten below if a GT box is
# matched to them. Skip boxes in crowd areas.
anchor_iou_argmax = np.argmax(overlaps, axis=1)
anchor_iou_max = overlaps[np.arange(overlaps.shape[0]), anchor_iou_argmax]
rpn_match[(anchor_iou_max < 0.3) & (no_crowd_bool)] = -1
# 2. Set an anchor for each GT box (regardless of IoU value).
# If multiple anchors have the same IoU match all of them
gt_iou_argmax = np.argwhere(overlaps == np.max(overlaps, axis=0))[:,0]
rpn_match[gt_iou_argmax] = 1
# 3. Set anchors with high overlap as positive.
rpn_match[anchor_iou_max >= 0.7] = 1
# Subsample to balance positive and negative anchors
# Don't let positives be more than half the anchors
ids = np.where(rpn_match == 1)[0]
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE // 2)
if extra > 0:
# Reset the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
# Same for negative proposals
ids = np.where(rpn_match == -1)[0]
extra = len(ids) - (config.RPN_TRAIN_ANCHORS_PER_IMAGE -
np.sum(rpn_match == 1))
if extra > 0:
# Rest the extra ones to neutral
ids = np.random.choice(ids, extra, replace=False)
rpn_match[ids] = 0
# For positive anchors, compute shift and scale needed to transform them
# to match the corresponding GT boxes.
ids = np.where(rpn_match == 1)[0]
ix = 0 # index into rpn_bbox
# TODO: use box_refinement() rather than duplicating the code here
for i, a in zip(ids, anchors[ids]):
# Closest gt box (it might have IoU < 0.7)
gt = gt_boxes[anchor_iou_argmax[i]]
# Convert coordinates to center plus width/height.
# GT Box
gt_h = gt[2] - gt[0]
gt_w = gt[3] - gt[1]
gt_center_y = gt[0] + 0.5 * gt_h
gt_center_x = gt[1] + 0.5 * gt_w
# Anchor
a_h = a[2] - a[0]
a_w = a[3] - a[1]
a_center_y = a[0] + 0.5 * a_h
a_center_x = a[1] + 0.5 * a_w
# Compute the bbox refinement that the RPN should predict.
rpn_bbox[ix] = [
(gt_center_y - a_center_y) / a_h,
(gt_center_x - a_center_x) / a_w,
np.log(gt_h / a_h),
np.log(gt_w / a_w),
]
# Normalize
rpn_bbox[ix] /= config.RPN_BBOX_STD_DEV
ix += 1
return rpn_match, rpn_bbox
3、损失定义
(1)RPN分类loss,交叉熵损失
def rpn_class_loss_graph(rpn_match, rpn_class_logits):
"""RPN anchor classifier loss.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_class_logits: [batch, anchors, 2]. RPN classifier logits for BG/FG.
"""
# Squeeze last dim to simplify
rpn_match = tf.squeeze(rpn_match, -1)
# Get anchor classes. Convert the -1/+1 match to 0/1 values.
anchor_class = K.cast(K.equal(rpn_match, 1), tf.int32)
# Positive and Negative anchors contribute to the loss,
# but neutral anchors (match value = 0) don't.
indices = tf.where(K.not_equal(rpn_match, 0))
# Pick rows that contribute to the loss and filter out the rest.
rpn_class_logits = tf.gather_nd(rpn_class_logits, indices)
anchor_class = tf.gather_nd(anchor_class, indices)
# Cross entropy loss
loss = K.sparse_categorical_crossentropy(target=anchor_class,
output=rpn_class_logits,
from_logits=True)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0))
return loss(2)RPN框回归loss,Smooth L1损失
def rpn_bbox_loss_graph(config, target_bbox, rpn_match, rpn_bbox):
"""Return the RPN bounding box loss graph.
config: the model config object.
target_bbox: [batch, max positive anchors, (dy, dx, log(dh), log(dw))].
Uses 0 padding to fill in unsed bbox deltas.
rpn_match: [batch, anchors, 1]. Anchor match type. 1=positive,
-1=negative, 0=neutral anchor.
rpn_bbox: [batch, anchors, (dy, dx, log(dh), log(dw))]
"""
# Positive anchors contribute to the loss, but negative and
# neutral anchors (match value of 0 or -1) don't.
rpn_match = K.squeeze(rpn_match, -1)
indices = tf.where(K.equal(rpn_match, 1))
# Pick bbox deltas that contribute to the loss
rpn_bbox = tf.gather_nd(rpn_bbox, indices)
# Trim target bounding box deltas to the same length as rpn_bbox.
batch_counts = K.sum(K.cast(K.equal(rpn_match, 1), tf.int32), axis=1)
target_bbox = batch_pack_graph(target_bbox, batch_counts,
config.IMAGES_PER_GPU)
loss = smooth_l1_loss(target_bbox, rpn_bbox)
loss = K.switch(tf.size(loss) > 0, K.mean(loss), tf.constant(0.0))
return lossdef smooth_l1_loss(y_true, y_pred):
"""Implements Smooth-L1 loss.
y_true and y_pred are typically: [N, 4], but could be any shape.
"""
diff = K.abs(y_true - y_pred)
less_than_one = K.cast(K.less(diff, 1.0), "float32")
loss = (less_than_one * 0.5 * diff**2) + (1 - less_than_one) * (diff - 0.5)
return loss(3)MRCNN分类loss,交叉熵损失
def mrcnn_class_loss_graph(target_class_ids, pred_class_logits,
active_class_ids):
"""Loss for the classifier head of Mask RCNN.
target_class_ids: [batch, num_rois]. Integer class IDs. Uses zero
padding to fill in the array.
pred_class_logits: [batch, num_rois, num_classes]
active_class_ids: [batch, num_classes]. Has a value of 1 for
classes that are in the dataset of the image, and 0
for classes that are not in the dataset.
"""
# During model building, Keras calls this function with
# target_class_ids of type float32. Unclear why. Cast it
# to int to get around it.
target_class_ids = tf.cast(target_class_ids, 'int64')
# Find predictions of classes that are not in the dataset.
pred_class_ids = tf.argmax(pred_class_logits, axis=2)
# TODO: Update this line to work with batch > 1. Right now it assumes all
# images in a batch have the same active_class_ids
pred_active = tf.gather(active_class_ids[0], pred_class_ids)
# Loss
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=target_class_ids, logits=pred_class_logits)
# Erase losses of predictions of classes that are not in the active
# classes of the image.
loss = loss * pred_active
# Computer loss mean. Use only predictions that contribute
# to the loss to get a correct mean.
loss = tf.reduce_sum(loss) / tf.reduce_sum(pred_active)
return loss(4)MRCNN框回归loss,Smooth L1损失
def mrcnn_bbox_loss_graph(target_bbox, target_class_ids, pred_bbox):
"""Loss for Mask R-CNN bounding box refinement.
target_bbox: [batch, num_rois, (dy, dx, log(dh), log(dw))]
target_class_ids: [batch, num_rois]. Integer class IDs.
pred_bbox: [batch, num_rois, num_classes, (dy, dx, log(dh), log(dw))]
"""
# Reshape to merge batch and roi dimensions for simplicity.
target_class_ids = K.reshape(target_class_ids, (-1,))
target_bbox = K.reshape(target_bbox, (-1, 4))
pred_bbox = K.reshape(pred_bbox, (-1, K.int_shape(pred_bbox)[2], 4))
# Only positive ROIs contribute to the loss. And only
# the right class_id of each ROI. Get their indices.
positive_roi_ix = tf.where(target_class_ids > 0)[:, 0]
positive_roi_class_ids = tf.cast(
tf.gather(target_class_ids, positive_roi_ix), tf.int64)
indices = tf.stack([positive_roi_ix, positive_roi_class_ids], axis=1)
# Gather the deltas (predicted and true) that contribute to loss
target_bbox = tf.gather(target_bbox, positive_roi_ix)
pred_bbox = tf.gather_nd(pred_bbox, indices)
# Smooth-L1 Loss
loss = K.switch(tf.size(target_bbox) > 0,
smooth_l1_loss(y_true=target_bbox, y_pred=pred_bbox),
tf.constant(0.0))
loss = K.mean(loss)
return loss
(5)MRCNN分割maskloss,Smooth L1损失
def mrcnn_mask_loss_graph(target_masks, target_class_ids, pred_masks):
"""Mask binary cross-entropy loss for the masks head.
target_masks: [batch, num_rois, height, width].
A float32 tensor of values 0 or 1. Uses zero padding to fill array.
target_class_ids: [batch, num_rois]. Integer class IDs. Zero padded.
pred_masks: [batch, proposals, height, width, num_classes] float32 tensor
with values from 0 to 1.
"""
# Reshape for simplicity. Merge first two dimensions into one.
target_class_ids = K.reshape(target_class_ids, (-1,))
mask_shape = tf.shape(target_masks)
target_masks = K.reshape(target_masks, (-1, mask_shape[2], mask_shape[3]))
pred_shape = tf.shape(pred_masks)
pred_masks = K.reshape(pred_masks,
(-1, pred_shape[2], pred_shape[3], pred_shape[4]))
# Permute predicted masks to [N, num_classes, height, width]
pred_masks = tf.transpose(pred_masks, [0, 3, 1, 2])
# Only positive ROIs contribute to the loss. And only
# the class specific mask of each ROI.
positive_ix = tf.where(target_class_ids > 0)[:, 0]
positive_class_ids = tf.cast(
tf.gather(target_class_ids, positive_ix), tf.int64)
indices = tf.stack([positive_ix, positive_class_ids], axis=1)
# Gather the masks (predicted and true) that contribute to loss
y_true = tf.gather(target_masks, positive_ix)
y_pred = tf.gather_nd(pred_masks, indices)
# Compute binary cross entropy. If no positive ROIs, then return 0.
# shape: [batch, roi, num_classes]
loss = K.switch(tf.size(y_true) > 0,
K.binary_crossentropy(target=y_true, output=y_pred),
tf.constant(0.0))
loss = K.mean(loss)
return loss
参考文章:
https://www.jianshu.com/p/29fb23a847b9
https://blog.csdn.net/horizonheart/article/details/81188161