Python开发爬虫完整代码解析
Python开发爬虫完整代码解析
 移除python
移除python
三天时间,总算开发完了。说道爬虫,我觉得有几个东西需要特别注意,一个是队列,告诉程序,有哪些url要爬,第二个就是爬页面,肯定有元素缺失的,这个究其原因我并不理解,为什么爬源代码还会爬下来页面缺元素闭合标签。但是概率特别小。第三个就是,报错重跑机制,经常会出现页面urlerror10004报错,其实就是网页打不开,打不开的原因也许是网络,也许是服务器切断服务,所以,我们还是需要重新爬这个url,一般呢在爬一次就行了,但是,有时候,需要爬两次,这点,遇到过一次场景。
但是有了报错重跑机制,无论多少次,都一样可以跑下来的。而且可以记录下来是哪一个url重新跑了。
那行,我们来看看所有完整代码,600,爬虫,额,在这里,我感觉哈,爬哪一个网站的事情,不能过多的说。
再者,我们爬网页数据下来之后,据说是要做用户画像,给客户打标签。
其实这篇文档的 产生是在开发完之后,我们周一写的,时效性已经差了两天,当时遇到的困难,以及代码的攻克、bug的印象已经忘记一些了,所以还是强调,攻城拔寨需要加班,攻城拔寨需要文档。(说在开发中写文档显然不太现实,当时是频繁调试,遇到太多问题,写文档会浪费大量时间)
闲话不多了,开始吧。第一步骤的python爬虫,我们爬的是网页的两个主页面。这中间也许有我没有解释的代码,也都会在后文给出解释,因为从无到有是一步一步实现,可能再后来再说可配置的事情比较好。
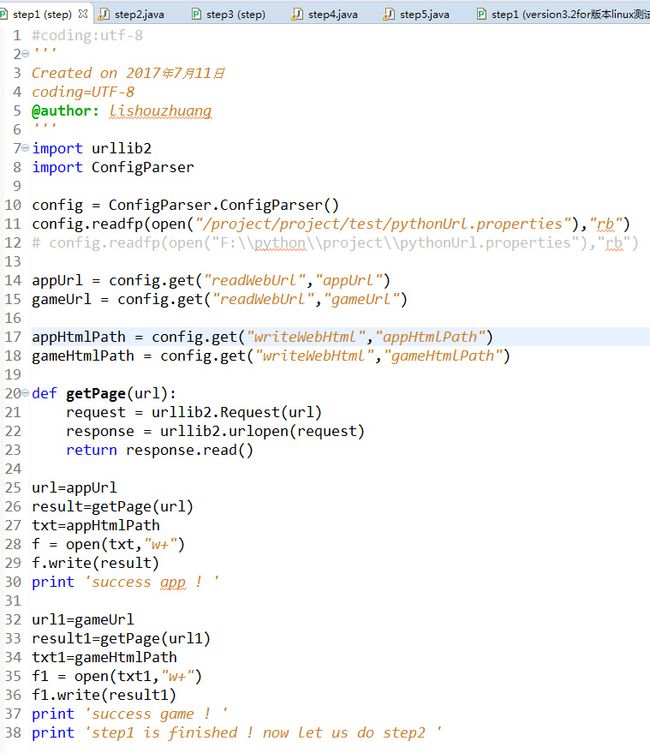 移除第一部分代码
移除第一部分代码
import urllib2
import ConfigParser
导入url类库和python读取配置文件库,读取配置文件位置后,读取具体url位置,并且读取将来把生成的队列的文件也一并从配置文件中读取出来。那么python的配置文件,我们粘贴一下。
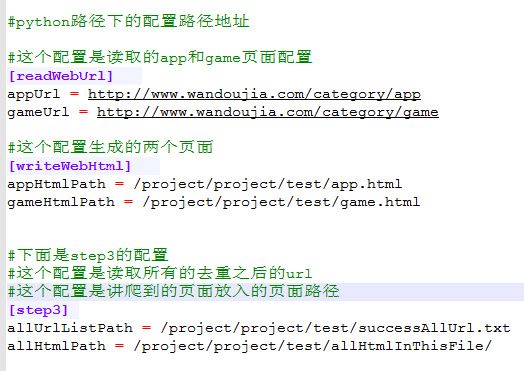 移除python配置文件
移除python配置文件
先不要看step3的,否则会不理解。
url=appUrl
result=getPage(url)
txt=appHtmlPath
f = open(txt,"w+")
f.write(result)
print 'success app ! '
我们调用了
def getPage(url):
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read()
使用urllib2的request方法发送url请求,并且得到响应response。然后,python声明变量得到的将会被自动装箱(我用Java的名词来解释这种特性,但是显然,python要更加人性化)当然,我并非说Java或者python哪一个好,要知道,这并不是我们关心的。
接着看代码,我们
txt=appHtmlPath
f = open(txt,"w+")
f.write(result)
print 'success app ! '
这四句,读取生成文件位置,将这个首页全部读取,然后写到文件中。当然,首页是有两个,一个手机应用软件,一个是手机游戏软件。好,我们去看看页面,和生成的页面。
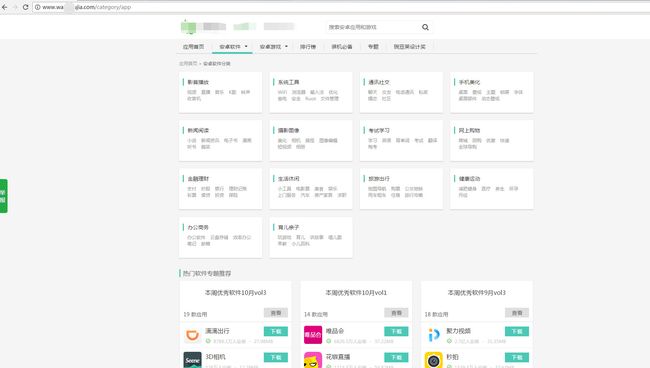 移除源网页
移除源网页
上面是源网页,然后我们看看爬下来的html文件
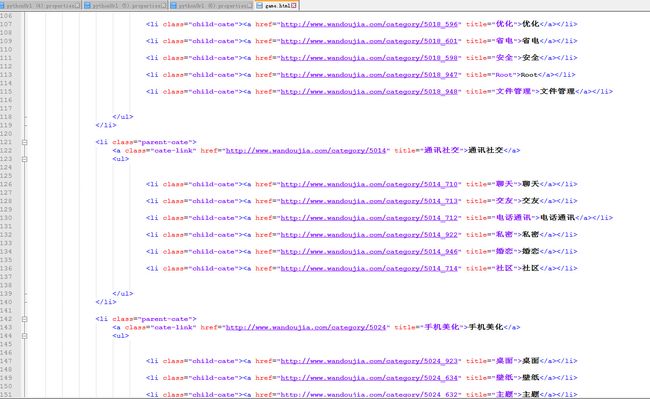 移除html文件
移除html文件
然后第一部分,结束,是不是很简单呢?那就开始第二步,从这些所有的html中获取到href和title两个元素,咱们要用的。
第二部分代码粘贴:
package step;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* 该类用于将爬虫爬下来的app和game两个url拼接到一个txt文件里面,并且,去重
* @author lishouzhuang
*
*/
public class step2 {
public static void doStep2(Map propertisPathmap) throws IOException{
// 首先设置app的url
String app_url = (String) propertisPathmap.get("app_url");
// 首先设置app的url
String game_url = (String) propertisPathmap.get("game_url");
// 在设置url.txt生成位置
String successUrl = (String) propertisPathmap.get("successUrl");
ifFileHave(successUrl, 1);//检查url.txt是否存在
//提前在第三步之前创建他要用的文件
String allHtmlPath = (String) propertisPathmap.get("allHtmlPath");
// //设置生成文件路径名称位置,需要去解析路径
ifFileHave(allHtmlPath, 2);//检查url.txt是否存在
List listApp = readHtmlToTxt(app_url);
List listGame = readHtmlToTxt(game_url);
//将game的list循环依次添加到app的list里面,后面用以去重
for(int i=0;i
listApp.add(listGame.get(i));
}
//调用removeDuplicateObj方法,以去除listApp中包括listGame中大量重复的元素
List newList = removeDuplicateObj(listApp);
System.out.println("no repeat url number :"+newList.size());
//将list传给write()方法,并且将元素写到txt文件中,并且带入生成文件目录
write(successUrl,newList);
System.out.println("Done!");
}
/**
* 公共方法,获取app和game的html里面所有的url
* 返回list
* @param url
* @throws IOException
*/
public static List readHtmlToTxt(String url) throws IOException{
//获取html的文件,转成Jsoup对象
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
//得到所有应用分类的所有div里的访问地址集合
Elements eleApp = doc.getElementsByClass("parent-cate");
List list = new ArrayList();
// 取得a标签
Elements eleA = eleApp.select("a");
for (int j = 0; j < eleA.size(); j++) {
// 循环得到所有的a标签
String href = eleA.get(j).attr("href");//访问地址
// 带_线的,是首页全部,我们并不需要
Boolean flag = href.contains("_");
if (flag) {
//在这里将字符串处理,并且添加到list中
String result = href + "\n";
list.add(result);
}
}
System.out.println("this list number:"+list.size());
return list;
}
/**
* 去除list集合中重复的元素,这个比较关键,如果这里不优化,那么到分析的时候,会有很多的url,太浪费时间了。
* @param list
*/
public static List removeDuplicateObj(List list) {
Set someSet = new HashSet(list);
// 将Set中的集合,放到一个临时的链表中(tempList)
Iterator iterator = someSet.iterator();
List tempList = new ArrayList();
int i = 0;
while (iterator.hasNext()) {
tempList.add(iterator.next().toString());
i++;
}
return tempList;
}
public static void write(String outPath,List list){
FileWriter writer;
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
writer = new FileWriter(outPath, true);
for(int i=0;i
//将list中的元素依次写入
writer.write(list.get(i).toString());
}
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 该方法用来检测文件和文件夹是否已经存在,
* 如果是文件,不存在即创建,存在即删除;如果是文件夹,不存在创建
* @param filepath
* @param type
*/
public static void ifFileHave(String filepath,int type){
//File file=new File("F:\\python\\6.txt");
File file=new File(filepath);
if(type==1){//如果type为1说明是文件
if(!file.exists()){
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}else{//如果文件已经存在,我们需要删除
System.out.println(file+" is already exist,We should delete it and mkdir.");
file.delete();
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
}else{//如果type为2说明是文件夹
//如果文件夹不存在则创建
if (!file .exists() && !file .isDirectory()){
System.out.println(file+": directory is not exist , now create this dir .");
file .mkdir();
} else{
System.out.println(file+": directory is already exist , We do not create this dir . ");
}
}
}
//测试主类
public static void main(String[] args) throws IOException, InterruptedException {
//doStep2(Map);
}
/**
* 该类用来判断文件是否存在,如果存在我们删除,如果不存在,我们创建
* @param filepath
*/
}
第二部分为java代码。
其实每个类和方法我都写了大量的注释,以及关键代码。那这里我大致说一下第二部分的思路吧。首先我们观察html文件之后,发现
 移除观察元素
移除观察元素
我们首先获取class为parent-cate的li,从li中取出其他的li元素里面的href、title。
好的,我们就可以取到所有href和title的map对象了。然后看,
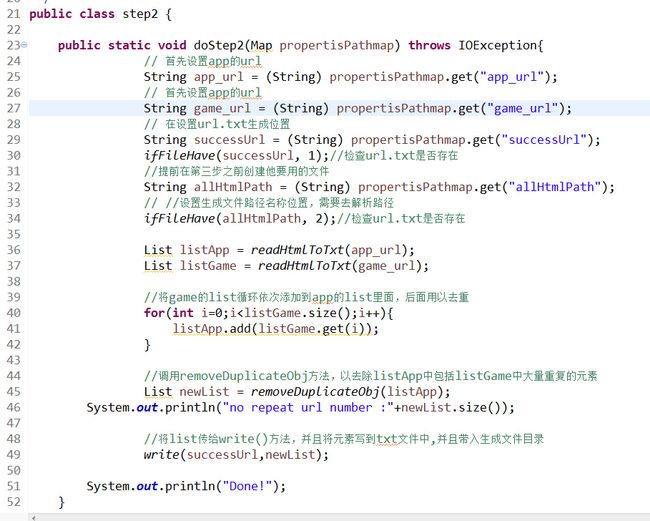 移除step2方法
移除step2方法
每一步都有注释,无非就是读取配置文件,然后
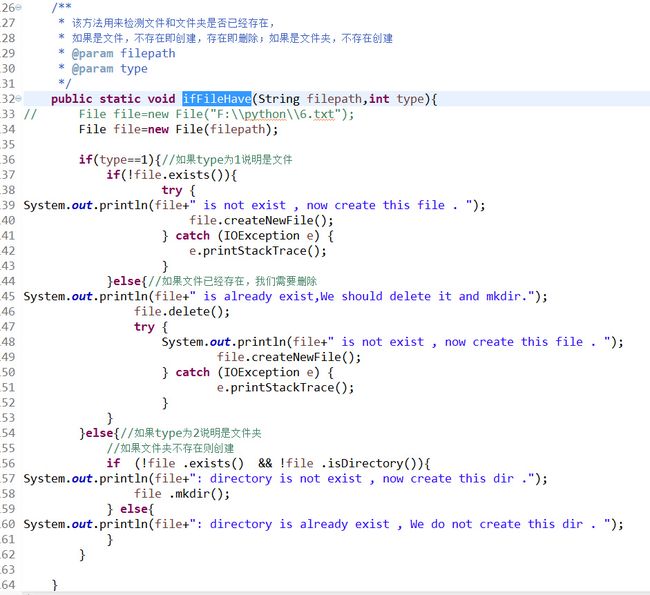 移除文件以及文件夹存在情况处理
移除文件以及文件夹存在情况处理
如果有重复元素,我们使用hashset来迭代去重,当然方法很多,这只是一种,还有追加写文件的方法,将list中文件写入配置好的文件中。
 移除html对象处理
移除html对象处理
这个就是html对象处理了,都有注释,可以看到处理的方式。是讲html中所有的a标签下面的href获取到,当然我们不要大分类的url,只要带“_”的,说明是一个小分类的url,然后我们要加\n换行。“\r\n”经过测试在windows下不会导致空行,但是linux下会导致空行。
第二部分完成,其实第二部分为什么没有继续用python写下去,是因为,我用python被卡了2-3个小时,用beautysoup类库,但是不是报python的版本就是类库不存在,卡了太久不如用java来的快。
再来说这个第一第二部分的意义,其实就是获取队列,来去重重复的队列,如果没有这两部,会导致有500个url,当然大量是重复的,这两部后,会仅剩145个去重的小分类url需要爬。
爬好之后,这个就是我们需要的队列文本文件,为了给第三部分python代码去依次爬取所有的url做准备。
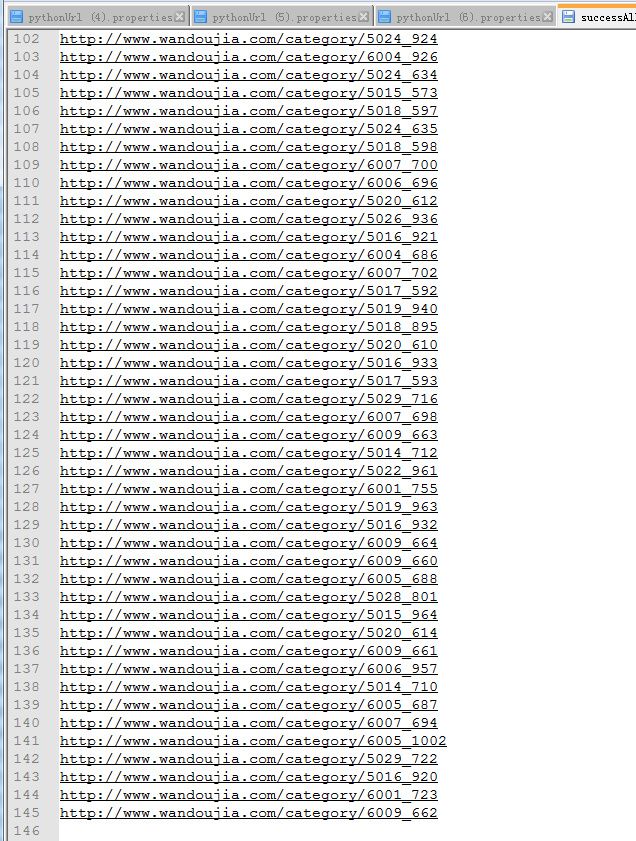 移除爬取到的url队列
移除爬取到的url队列
进入第三部分,代码全粘贴:
#coding:utf-8
'''
Created on 2017年7月11日
coding=UTF-8
@author: lishouzhuang
'''
import urllib2
import ConfigParser
config = ConfigParser.ConfigParser()
config.readfp(open("/project/project/test/pythonUrl.properties"),"rb")
# config.readfp(open("F:\\python\\project\\pythonUrl.properties"),"rb")
allUrlListPath = config.get("step3","allUrlListPath")
allHtmlPath = config.get("step3","allHtmlPath")
def getPage(url):
try:
headers = {'User-Agent':'Chrome 17.0 – MACUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
return response.read()
#递归复制页面
except urllib2.URLError,e:
print 'you have an error : ',str(e)
print '---------------------------------------------------'
print 'error !','you need to rerun!! ' ,url
#因为经常出现you have an error :
#这里我们在跑一次,这次如果还失败,那就循环跑他
rerun = getPage(url)#在跑一次
print 'now is rerun ', url
rerunLength = rerun.__len__()
print 'rerun is ok , no continue!!!'
print rerunLength
#
# while rerunLength != 0:
# print '又错了,再跑最后一次吧'
# return = getPage(url)
return rerun
# 这个配置是读取所有的去重之后的url
# filename = "F:\\python\\project\\successAllUrl.txt"
filename =allUrlListPath
def readfile(filename):
with open(filename,'r') as f:
list=[]
for line in f.readlines():
linestr = line.strip()
# print linestr
linestrlist = linestr.split("\n")
list.append(linestrlist[0])
# print(list)
print list.__len__()
# sorts = ['http://www.wandoujia.com/category/5029_716', 'http://www.wandoujia.com/category/5029_1006', 'http://www.wandoujia.com/category/5029_722', 'http://www.wandoujia.com/
#就在此处循环
for item in list:
#接下来,我们要做的是,将每个分类创建一个文件夹,并且在文件夹中,将分页的42个文件放入其中
#首先创建第一个文件
p=1
while p<=42:
# 如果是首页,直接这样,例如 http://www.wandoujia.com/category/5029_716
#视频的第一页
if p==1:
#处理字符串
strResult = item.split("/")[-1]
print 'now copy this url : ',strResult
result=getPage(item+'/'+str(p))
# 在此处取得网站源码
# txt=r'F:\\python\\project\\allHtmlInThisFile\\'+strResult+'_'+str(p)+'.html'
txt=allHtmlPath+strResult+'_'+str(p)+'.html'
f = open(txt,"w")
f.write(result)
p=p+1
#如果是第二页的话,要加这个东西了
else:
result=getPage(item+'/'+str(p))
# 在此处取得网站源码
txt=allHtmlPath+strResult+'_'+str(p)+'.html'
f = open(txt,"w")
f.write(result)
if p==42:
# 做这件事是准备报错重跑队列的准备的。将剩下没跑的,自己循环,调用自己,看看是否到时候用得到吧。
print 'this url is finished : ' ,item
# list.remove(item)
# print p
p=p+1
f.close()
readfile(filename)
print 'end'
代码解读一下,首先依次是上来声明类库获取配置文件信息以及元素,然后我们直接看readfile方法,传递参数filename文件,声明list[]可变数组,按行读取文件,并且按照“\n”来切割,将获取的元素追加到list中,这个就是我们接下来要循环的队列了。
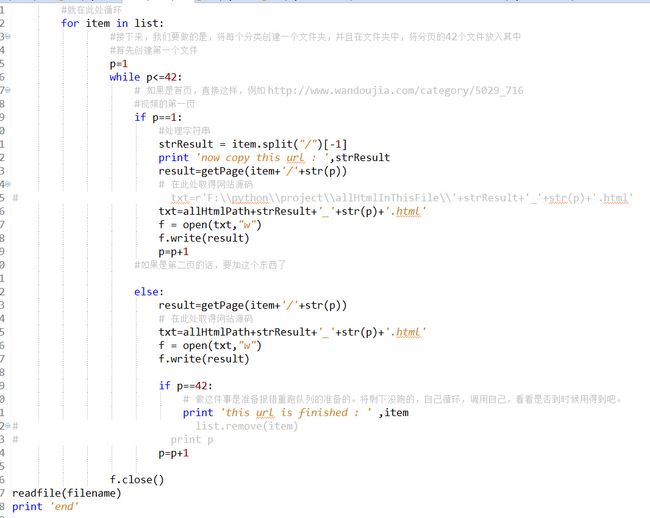 移除循环代码
移除循环代码
上面是循环代码,下面是获取页面的代码:
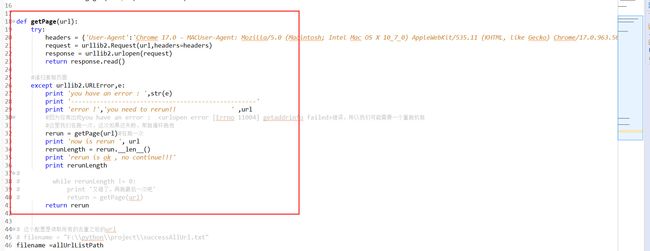 移除获取html爬虫页面
移除获取html爬虫页面
首先看循环代码,因为豌豆荚的总分页,看了一下,最大42页,而且是全部分类,显然我们用不到全部分类的,每个大分类下面差不多6个小分类,小分类吗,总共是42页,6个小分类,我就算极端一下,一个小分类全部囊括了,也就42页的罢了。所以,我们生命循环次数是42次,然后第一页的话,我们分析了是没有'/1'这种序号的,可以看一下截图例子。
 移除第一页
移除第一页
第一页
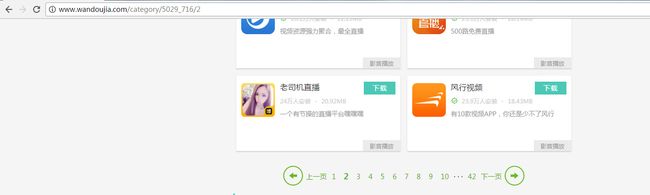 移除第二页
移除第二页
第二页
 移除第三页
移除第三页
第三页,所以第一页,不需要拼接/1,然后我们读取文件后写入配置好的路径。其他的随意。
好,接下来,看这个,爬取网页代码,try、except代码,获取url就去爬取了,try部分还可以理解的,到了except代码,那就是递归了,一般地两次就出来了。
报错重跑机制,还不完善,但是完全够解决现阶段的错误了。可以摆脱urlerror:10004报错
这里后期我们优化可能要加一个全局变量,限制递归次数,这个小优化,我后期加上,如果超过了5次,我们直接把这个response返回一个空字符串出来就行了,让第四步分析的时候不分析算了。
第三部分结果
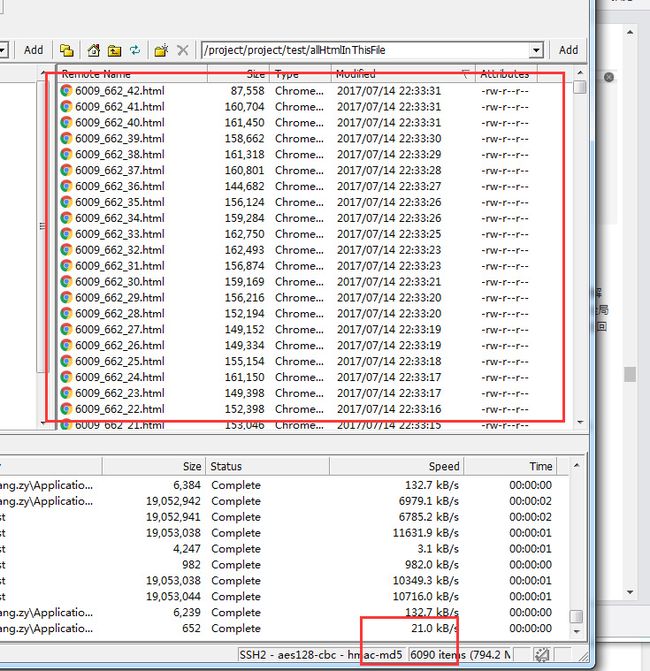 移除6090张html页面
移除6090张html页面
精髓就在这个递归,就是报错重跑url了。第二步加第三部,合起来组成了队列的思想。
第四部分代码依然是java代码,就是说,程序爬取页面用的是python的类库, 分析解析用的是java,第四部分代码全粘贴:
package step;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 该类用来解析所有html文件
*
* @author lishouzhuang
*
*/
public class step4 {
//所有数据map用作,数据去重
static Map map =new HashMap();
public static void doStep4(Map propertisPathmap) throws IOException {
// 设置生成文件路径以及文件名
String finalResultfilePath = (String) propertisPathmap.get("finalResultfilePath");
// 设置路径:所有html位置
//String url = "F:\\python\\file_backups\\";
String allHtmlPath = (String) propertisPathmap.get("allHtmlPath");
// //设置生成文件路径名称位置,需要去解析路径
ifFileHave(allHtmlPath, 2);//检查url.txt是否存在
System.out.println("------------start-------------------");
showName(allHtmlPath, finalResultfilePath);
System.out.println("-------------end----------------");
}
public static void clean(String url, String fileUrl) throws IOException {
// File input =new File("F:\\python\\file\\result_716_1.html");
// 循环拿到url
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
// 以下方法为了获得“影音播放”,操作dom
Elements movieAndMusic = doc.getElementsByClass("third");
/**
* * itemtype="http://data-vocabulary.org/Breadcrumb"> * 影音播放
*/
// 将div的class为third的元素中的分类名称取出
Elements aEle= movieAndMusic.select("a");
String Mname = aEle.html();
if(Mname==null && "".equals(Mname)){
Mname = "null";
}
// 以下方法为了获得分类名称
// 查找第一个h1元素//视频下载
Element link = doc.select("h1").first();
String TypeString = "";
//这里是为了有时候页面出现h1没有的情况,要做特殊处理
if(link == null){
//调错,找到错误原因
System.out.println("link is null! ");
System.out.println("you have no link file :"+url);
TypeString="null";
// 使用方法1,分割:“下载”
String preString1 = TypeString;
// 操作dom,获取所有class为card的,他们都是应用的div,即可获取应用所有的html对象
Elements link2 = doc.getElementsByClass("card");
String result = "";
for (int i = 0; i < link2.size(); i++) {
// 依次创建Element对象,封装所有的div
Element ele = link2.get(i);
// 将带有a标签的对象带出来,a标签中,有href、title等等元素,可以提取
Element h2 = ele.select("h2").select("a").first();
// 获取href引用字符串
String str_href_all = h2.attr("href");
// 这里调用changeString的第二个方法
String str_href = changeString(str_href_all, 2);
// 获取title应用名称
String str_title = h2.attr("title");
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
//System.out.println(result);
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
}
}else{
try{
// 拿到分类名称 例如 视频下载
TypeString = link.html();
}catch(Exception e){
e.printStackTrace();
}
// 使用方法1,分割:“下载”
String preString1 = changeString(TypeString, 1);
// 操作dom,获取所有class为card的,他们都是应用的div,即可获取应用所有的html对象
Elements link2 = doc.getElementsByClass("card");
String result = "";
for (int i = 0; i < link2.size(); i++) {
// 依次创建Element对象,封装所有的div
Element ele = link2.get(i);
// 将带有a标签的对象带出来,a标签中,有href、title等等元素,可以提取
Element h2 = ele.select("h2").select("a").first();
// 获取href引用字符串
String str_href_all = h2.attr("href");
// 这里调用changeString的第二个方法
String str_href = changeString(str_href_all, 2);
// 获取title应用名称
String str_title = h2.attr("title");
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
}
//// 写入文件,传入参数,结果字符串,以及文件路径
//writeTxt(result, fileUrl);
}
}
// 字符串处理
public static String changeString(String str, int type) {
String resolve = "";
// 方法变换
if (type == 1) {
// 方法一
// 如果type等于1,将下载去除
// 拿到应用名下载 变成 拿到应用名
resolve = str.substring(0, str.length() - 2);// 这里截取的信息就是e,倒数第二个字符
} else {
// 方法二
// 切割得到包名
// http://www.wandoujia.com/apps/com.synprez.fm 变成 com.synprez.fm
String[] strArr = str.split("/");
resolve = strArr[strArr.length - 1];
}
return resolve;
}
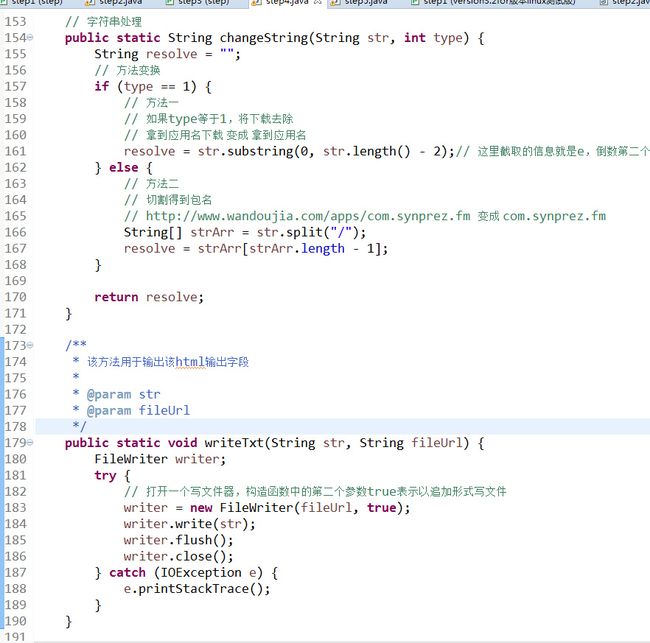
/**
* 该方法用于输出该html输出字段
*
* @param str
* @param fileUrl
*/
public static void writeTxt(String str, String fileUrl) {
FileWriter writer;
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
writer = new FileWriter(fileUrl, true);
writer.write(str);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
*
* @param HtmlsPath
* @return
*/
public static List getFileName(String HtmlsPath) {
// String path = "F:/python/file2"; // 路径F:\python\file2
String path = HtmlsPath;
File f = new File(path);
if (!f.exists()) {
System.out.println(path + " not exists");
return null;
}
List list = new ArrayList();
File fa[] = f.listFiles();
for (int i = 0; i < fa.length; i++) {
File fs = fa[i];
// if (fs.isDirectory()) {
// System.out.println(fs.getName() + " [目录]");
// } else {
// System.out.println(fs.getName());
// System.out.println(fs.getPath());
// }
list.add(fs.getPath());
}
System.out.println(list.size());
return list;
}
/**
* 获取该url下所有的文件 假设url为 F:\\python\\file\\
*
* @param url
* @param fileUrl
* @throws IOException
*/
public static void showName(String url, String fileUrl) throws IOException {
List list = getFileName(url);
for (int i = 0; i < list.size(); i++) {
// 循环执行清洗数据
String uri = (String) list.get(i);
clean(uri, fileUrl);
}
}
/**
* 该方法用来检测文件和文件夹是否已经存在,
* 如果是文件,不存在即创建,存在即删除;如果是文件夹,不存在创建
* @param filepath
* @param type
*/
public static void ifFileHave(String filepath,int type){
//File file=new File("F:\\python\\6.txt");
File file=new File(filepath);
if(type==1){//如果type为1说明是文件
if(!file.exists()){
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}else{//如果文件已经存在,我们需要删除
System.out.println(file+" is already exist,We should delete it and mkdir.");
file.delete();
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
}else{//如果type为2说明是文件夹
//如果文件夹不存在则创建
if (!file .exists() && !file .isDirectory()){
System.out.println(file+": directory is not exist , now create this dir . ");
file .mkdir();
} else{
System.out.println(file+": directory is already exist , We do not create this dir . ");
}
}
}
//测试main
public static void main(String[] args) throws IOException {
//doStep4(Map);
}
}
可以看到注释写的很详细。
老样子读取配置文件位置以及内容配置,将第三步骤中爬取的所有html页面全部解析。获取文件的方法咱们也就不多说了,以及读取文件夹下所有html的url,
 移除获取文件夹下所有的html页面的文件名称和urlpath
移除获取文件夹下所有的html页面的文件名称和urlpath
获取文件夹下所有的html页面的文件名称和urlpath
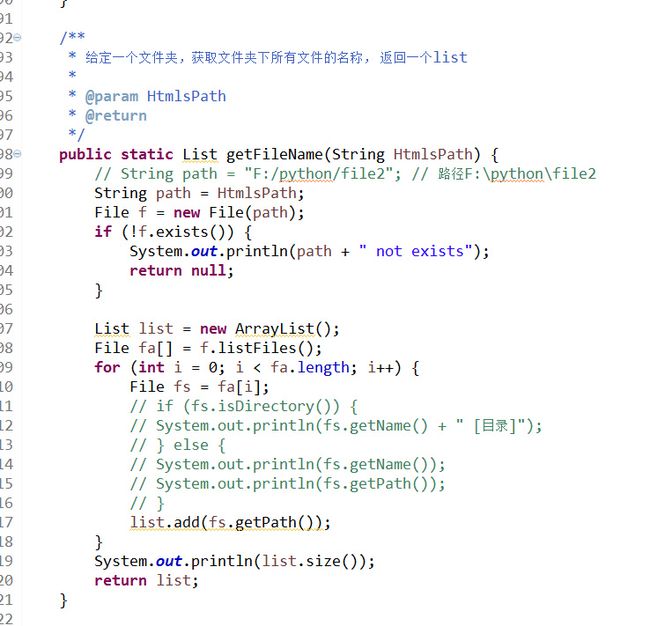 移除给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
移除给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
写入结果文件的公共方法:
 移除点击此处添加图片说明文字
移除点击此处添加图片说明文字
好的,接下来我们去看clean方法,这是个代码解析了。
先看看这个。
 移除源html页面
移除源html页面
这两个红框框的部分是我们要获取的页面内容,两个,记住了,这就是分类了。
 移除获取包名和url
移除获取包名和url
获取包名,包名就是具体的应用了,和用户的实用软件可以关联了。
所以代码操作dom树也就不难解释了。
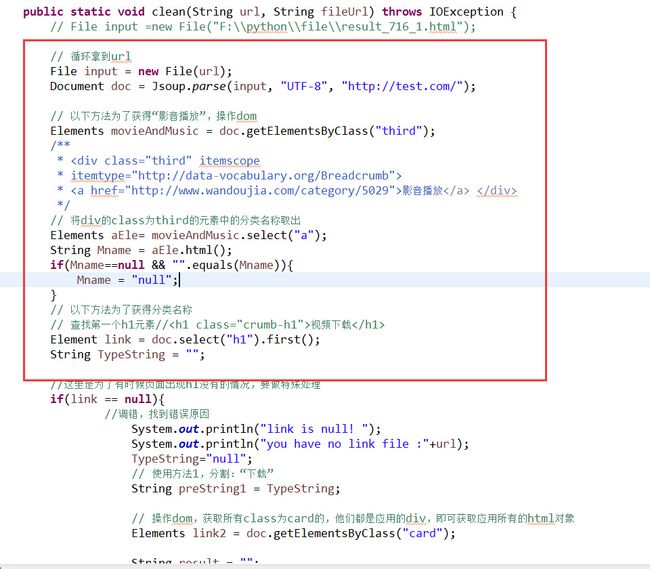 移除操作dom树
移除操作dom树
注释很清楚,
// 循环拿到url
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
操作dom,拿到Elements movieAndMusic = doc.getElementsByClass("third");
// 将div的class为third的元素中的分类名称取出
Elements aEle= movieAndMusic.select("a");
String Mname = aEle.html();
if(Mname==null && "".equals(Mname)){
Mname = "null";
}
// 以下方法为了获得分类名称
// 查找第一个h1元素//
视频下载
Element link = doc.select("h1").first();
这里是为了有时候页面出现h1没有的情况,要做特殊处理,有时候确实会没有这个h1,别奇怪
if(link == null){
然后这个是主要代码逻辑:
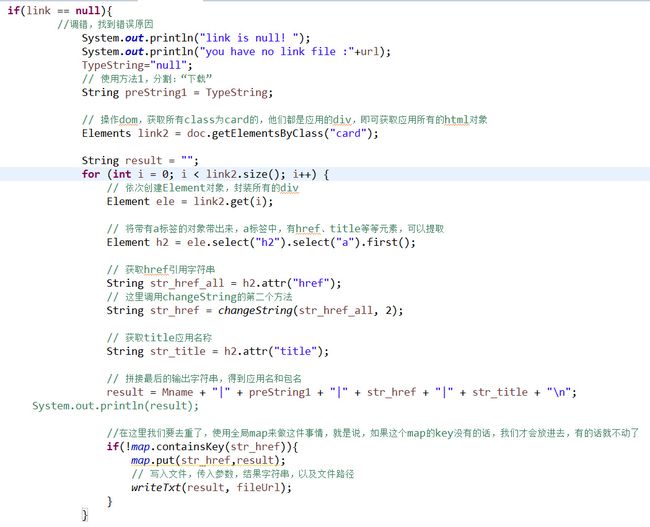 移除获取元素代码部分
移除获取元素代码部分
得到的card元素是一个集合,我们从集合中将每个元素取出,每个div里面有h2的a标签里面就是包的href和title,然后我们拼接。
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
注意这里还不能写,没有结束。
hive导入时我们发现:
影音播放K歌cn.kuwo.player酷我音乐20170712
影音播放铃声cn.kuwo.player酷我音乐20170712
影音播放音乐cn.kuwo.player酷我音乐20170712
就是一个应用会出现三个分类,这给我们后面做用户画像时的表关联带来了困难。所以,现阶段,我们只去第一个包分类。
所以,我们筛选去除后面两个分类,用hashmap的key去重,
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
到了这里,我们就可以看一下输出结果了,基本上大功告成了:
 移除结果文件
移除结果文件
最后的最后,我们需要一个调度方法,也就是step5的java类。
这个类要满足,可以读取配置文件,并且执行python脚本代码。
代码粘贴再分析:
package step;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Properties;
public class step5 {
public static void main(String[] args) throws IOException {
//主函数
//四步走战略
//读取properties文件位置
String propertisPath = "/project/project/test/main.properties";
//String propertisPath = "F:\\python\\project\\main.properties";
Map propertisPathmap = doProperties(propertisPath);
//先声明两个python脚本的位置
String python1 = (String) propertisPathmap.get("pythonPathStep1");
String python2 = (String) propertisPathmap.get("pythonPathStep3");
//step1
doPythonCmd(python1);//执行第一步,爬app和game两个网页
//step2
System.out.println("create step2 and run step2----------");
step2 step2 = new step2();
step2.doStep2(propertisPathmap);
//step3
doPythonCmd(python2);//执行爬虫程序,爬所有网页下来
//step4
System.out.println("create step4 and run step4----------");
step4 step4 = new step4();
step4.doStep4(propertisPathmap);
}
/**
* 该类用来读取python脚本文件
* @param cmd_ython
*/
public static void doPythonCmd(String cmd_ython){
//java运行python脚本
try{
System.out.println("start step:"+cmd_ython);
Process pr = Runtime.getRuntime().exec(cmd_ython);
BufferedReader in = new BufferedReader(new
InputStreamReader(pr.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
in.close();
pr.waitFor();
System.out.println("end step:"+cmd_ython);
} catch (Exception e){
e.printStackTrace();
}
}
/**
* 给方法用来读取配置文件
* @param propertisUrl
* @return
*/
public static Map doProperties(String propertisUrl){
Properties prop = new Properties();
Map map= new HashMap();
try{
//读取属性文件a.properties
// InputStream in = new BufferedInputStream (new FileInputStream("F:\\python\\pachong.properties"));
InputStream in = new BufferedInputStream (new FileInputStream(propertisUrl));
prop.load(in); ///加载属性列表
Iterator
while(it.hasNext()){
String key=it.next();
System.out.println(key+":"+prop.getProperty(key));
map.put(key, prop.getProperty(key));
}
in.close();
// ///保存属性到b.properties文件
// FileOutputStream oFile = new FileOutputStream("F:\\python\\pachong.properties", true);//true表示追加打开
// prop.setProperty("phone", "10086");
// prop.store(oFile, "The New properties file");
// oFile.close();
}
catch(Exception e){
System.out.println(e);
}
return map;
}
}
先看两个公共方法,
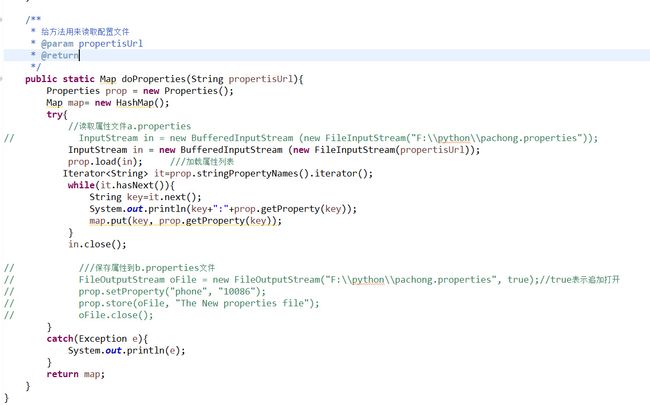 移除读取配置文件,并且得到参数方法
移除读取配置文件,并且得到参数方法
注释很详细,就不过多解释了,读取之后,map形式传出去。
 移除执行python脚本的公共方法
移除执行python脚本的公共方法
执行python脚本的公共方法,给入python脚本,然后start step :python脚本,采用runtime的方式。最后,调度类:
 移除所有调度方法依次执行。
移除所有调度方法依次执行。
很清晰吧。然后,所有的中间过程和jar包都在这里了。
 移除所有的中间过程和jar包
移除所有的中间过程和jar包
现在目前使用起来,经过测试是很稳定的,遇到一些不稳定因素已经被处理了,遇到了很多的坑,也都一一解决了。最恶心的是那个重跑url内所有的42个分页的方法,想了比较久,甚至想过写个list实现的txt从中间拿一个爬一个,后来想到了递归。
其实坑不止这些,还有很多很多细节去做了处理,版本打了很多:
 移除各个版本
移除各个版本
后期优化,如果需要还要继续,我记得多线程也得去做一下,等后期有空了,空闲了,要继续研究一下了,目前1个半小时之内,绝对可以搞定,每周爬一次,完全够用了。
好了,python开发的基本思路和代码分析就到这里了。
移除python
三天时间,总算开发完了。说道爬虫,我觉得有几个东西需要特别注意,一个是队列,告诉程序,有哪些url要爬,第二个就是爬页面,肯定有元素缺失的,这个究其原因我并不理解,为什么爬源代码还会爬下来页面缺元素闭合标签。但是概率特别小。第三个就是,报错重跑机制,经常会出现页面urlerror10004报错,其实就是网页打不开,打不开的原因也许是网络,也许是服务器切断服务,所以,我们还是需要重新爬这个url,一般呢在爬一次就行了,但是,有时候,需要爬两次,这点,遇到过一次场景。
但是有了报错重跑机制,无论多少次,都一样可以跑下来的。而且可以记录下来是哪一个url重新跑了。
那行,我们来看看所有完整代码,600,爬虫,额,在这里,我感觉哈,爬哪一个网站的事情,不能过多的说。
再者,我们爬网页数据下来之后,据说是要做用户画像,给客户打标签。
其实这篇文档的 产生是在开发完之后,我们周一写的,时效性已经差了两天,当时遇到的困难,以及代码的攻克、bug的印象已经忘记一些了,所以还是强调,攻城拔寨需要加班,攻城拔寨需要文档。(说在开发中写文档显然不太现实,当时是频繁调试,遇到太多问题,写文档会浪费大量时间)
闲话不多了,开始吧。第一步骤的python爬虫,我们爬的是网页的两个主页面。这中间也许有我没有解释的代码,也都会在后文给出解释,因为从无到有是一步一步实现,可能再后来再说可配置的事情比较好。
移除第一部分代码
import urllib2
import ConfigParser
导入url类库和python读取配置文件库,读取配置文件位置后,读取具体url位置,并且读取将来把生成的队列的文件也一并从配置文件中读取出来。那么python的配置文件,我们粘贴一下。
移除python配置文件
先不要看step3的,否则会不理解。
url=appUrl
result=getPage(url)
txt=appHtmlPath
f = open(txt,"w+")
f.write(result)
print 'success app ! '
我们调用了
def getPage(url):
request = urllib2.Request(url)
response = urllib2.urlopen(request)
return response.read()
使用urllib2的request方法发送url请求,并且得到响应response。然后,python声明变量得到的将会被自动装箱(我用Java的名词来解释这种特性,但是显然,python要更加人性化)当然,我并非说Java或者python哪一个好,要知道,这并不是我们关心的。
接着看代码,我们
txt=appHtmlPath
f = open(txt,"w+")
f.write(result)
print 'success app ! '
这四句,读取生成文件位置,将这个首页全部读取,然后写到文件中。当然,首页是有两个,一个手机应用软件,一个是手机游戏软件。好,我们去看看页面,和生成的页面。
移除源网页
上面是源网页,然后我们看看爬下来的html文件
移除html文件
然后第一部分,结束,是不是很简单呢?那就开始第二步,从这些所有的html中获取到href和title两个元素,咱们要用的。
第二部分代码粘贴:
package step;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
/**
* 该类用于将爬虫爬下来的app和game两个url拼接到一个txt文件里面,并且,去重
* @author lishouzhuang
*
*/
public class step2 {
public static void doStep2(Map propertisPathmap) throws IOException{
// 首先设置app的url
String app_url = (String) propertisPathmap.get("app_url");
// 首先设置app的url
String game_url = (String) propertisPathmap.get("game_url");
// 在设置url.txt生成位置
String successUrl = (String) propertisPathmap.get("successUrl");
ifFileHave(successUrl, 1);//检查url.txt是否存在
//提前在第三步之前创建他要用的文件
String allHtmlPath = (String) propertisPathmap.get("allHtmlPath");
// //设置生成文件路径名称位置,需要去解析路径
ifFileHave(allHtmlPath, 2);//检查url.txt是否存在
List listApp = readHtmlToTxt(app_url);
List listGame = readHtmlToTxt(game_url);
//将game的list循环依次添加到app的list里面,后面用以去重
for(int i=0;i
listApp.add(listGame.get(i));
}
//调用removeDuplicateObj方法,以去除listApp中包括listGame中大量重复的元素
List newList = removeDuplicateObj(listApp);
System.out.println("no repeat url number :"+newList.size());
//将list传给write()方法,并且将元素写到txt文件中,并且带入生成文件目录
write(successUrl,newList);
System.out.println("Done!");
}
/**
* 公共方法,获取app和game的html里面所有的url
* 返回list
* @param url
* @throws IOException
*/
public static List readHtmlToTxt(String url) throws IOException{
//获取html的文件,转成Jsoup对象
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
//得到所有应用分类的所有div里的访问地址集合
Elements eleApp = doc.getElementsByClass("parent-cate");
List list = new ArrayList();
// 取得a标签
Elements eleA = eleApp.select("a");
for (int j = 0; j < eleA.size(); j++) {
// 循环得到所有的a标签
String href = eleA.get(j).attr("href");//访问地址
// 带_线的,是首页全部,我们并不需要
Boolean flag = href.contains("_");
if (flag) {
//在这里将字符串处理,并且添加到list中
String result = href + "\n";
list.add(result);
}
}
System.out.println("this list number:"+list.size());
return list;
}
/**
* 去除list集合中重复的元素,这个比较关键,如果这里不优化,那么到分析的时候,会有很多的url,太浪费时间了。
* @param list
*/
public static List removeDuplicateObj(List list) {
Set someSet = new HashSet(list);
// 将Set中的集合,放到一个临时的链表中(tempList)
Iterator iterator = someSet.iterator();
List tempList = new ArrayList();
int i = 0;
while (iterator.hasNext()) {
tempList.add(iterator.next().toString());
i++;
}
return tempList;
}
public static void write(String outPath,List list){
FileWriter writer;
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
writer = new FileWriter(outPath, true);
for(int i=0;i
//将list中的元素依次写入
writer.write(list.get(i).toString());
}
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 该方法用来检测文件和文件夹是否已经存在,
* 如果是文件,不存在即创建,存在即删除;如果是文件夹,不存在创建
* @param filepath
* @param type
*/
public static void ifFileHave(String filepath,int type){
//File file=new File("F:\\python\\6.txt");
File file=new File(filepath);
if(type==1){//如果type为1说明是文件
if(!file.exists()){
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}else{//如果文件已经存在,我们需要删除
System.out.println(file+" is already exist,We should delete it and mkdir.");
file.delete();
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
}else{//如果type为2说明是文件夹
//如果文件夹不存在则创建
if (!file .exists() && !file .isDirectory()){
System.out.println(file+": directory is not exist , now create this dir .");
file .mkdir();
} else{
System.out.println(file+": directory is already exist , We do not create this dir . ");
}
}
}
//测试主类
public static void main(String[] args) throws IOException, InterruptedException {
//doStep2(Map);
}
/**
* 该类用来判断文件是否存在,如果存在我们删除,如果不存在,我们创建
* @param filepath
*/
}
第二部分为java代码。
其实每个类和方法我都写了大量的注释,以及关键代码。那这里我大致说一下第二部分的思路吧。首先我们观察html文件之后,发现
移除观察元素
我们首先获取class为parent-cate的li,从li中取出其他的li元素里面的href、title。
好的,我们就可以取到所有href和title的map对象了。然后看,
移除step2方法
每一步都有注释,无非就是读取配置文件,然后
移除文件以及文件夹存在情况处理
如果有重复元素,我们使用hashset来迭代去重,当然方法很多,这只是一种,还有追加写文件的方法,将list中文件写入配置好的文件中。
移除html对象处理
这个就是html对象处理了,都有注释,可以看到处理的方式。是讲html中所有的a标签下面的href获取到,当然我们不要大分类的url,只要带“_”的,说明是一个小分类的url,然后我们要加\n换行。“\r\n”经过测试在windows下不会导致空行,但是linux下会导致空行。
第二部分完成,其实第二部分为什么没有继续用python写下去,是因为,我用python被卡了2-3个小时,用beautysoup类库,但是不是报python的版本就是类库不存在,卡了太久不如用java来的快。
再来说这个第一第二部分的意义,其实就是获取队列,来去重重复的队列,如果没有这两部,会导致有500个url,当然大量是重复的,这两部后,会仅剩145个去重的小分类url需要爬。
爬好之后,这个就是我们需要的队列文本文件,为了给第三部分python代码去依次爬取所有的url做准备。
移除爬取到的url队列
进入第三部分,代码全粘贴:
#coding:utf-8
'''
Created on 2017年7月11日
coding=UTF-8
@author: lishouzhuang
'''
import urllib2
import ConfigParser
config = ConfigParser.ConfigParser()
config.readfp(open("/project/project/test/pythonUrl.properties"),"rb")
# config.readfp(open("F:\\python\\project\\pythonUrl.properties"),"rb")
allUrlListPath = config.get("step3","allUrlListPath")
allHtmlPath = config.get("step3","allHtmlPath")
def getPage(url):
try:
headers = {'User-Agent':'Chrome 17.0 – MACUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11'}
request = urllib2.Request(url,headers=headers)
response = urllib2.urlopen(request)
return response.read()
#递归复制页面
except urllib2.URLError,e:
print 'you have an error : ',str(e)
print '---------------------------------------------------'
print 'error !','you need to rerun!! ' ,url
#因为经常出现you have an error :
#这里我们在跑一次,这次如果还失败,那就循环跑他
rerun = getPage(url)#在跑一次
print 'now is rerun ', url
rerunLength = rerun.__len__()
print 'rerun is ok , no continue!!!'
print rerunLength
#
# while rerunLength != 0:
# print '又错了,再跑最后一次吧'
# return = getPage(url)
return rerun
# 这个配置是读取所有的去重之后的url
# filename = "F:\\python\\project\\successAllUrl.txt"
filename =allUrlListPath
def readfile(filename):
with open(filename,'r') as f:
list=[]
for line in f.readlines():
linestr = line.strip()
# print linestr
linestrlist = linestr.split("\n")
list.append(linestrlist[0])
# print(list)
print list.__len__()
# sorts = ['http://www.wandoujia.com/category/5029_716', 'http://www.wandoujia.com/category/5029_1006', 'http://www.wandoujia.com/category/5029_722', 'http://www.wandoujia.com/
#就在此处循环
for item in list:
#接下来,我们要做的是,将每个分类创建一个文件夹,并且在文件夹中,将分页的42个文件放入其中
#首先创建第一个文件
p=1
while p<=42:
# 如果是首页,直接这样,例如 http://www.wandoujia.com/category/5029_716
#视频的第一页
if p==1:
#处理字符串
strResult = item.split("/")[-1]
print 'now copy this url : ',strResult
result=getPage(item+'/'+str(p))
# 在此处取得网站源码
# txt=r'F:\\python\\project\\allHtmlInThisFile\\'+strResult+'_'+str(p)+'.html'
txt=allHtmlPath+strResult+'_'+str(p)+'.html'
f = open(txt,"w")
f.write(result)
p=p+1
#如果是第二页的话,要加这个东西了
else:
result=getPage(item+'/'+str(p))
# 在此处取得网站源码
txt=allHtmlPath+strResult+'_'+str(p)+'.html'
f = open(txt,"w")
f.write(result)
if p==42:
# 做这件事是准备报错重跑队列的准备的。将剩下没跑的,自己循环,调用自己,看看是否到时候用得到吧。
print 'this url is finished : ' ,item
# list.remove(item)
# print p
p=p+1
f.close()
readfile(filename)
print 'end'
代码解读一下,首先依次是上来声明类库获取配置文件信息以及元素,然后我们直接看readfile方法,传递参数filename文件,声明list[]可变数组,按行读取文件,并且按照“\n”来切割,将获取的元素追加到list中,这个就是我们接下来要循环的队列了。
移除循环代码
上面是循环代码,下面是获取页面的代码:
移除获取html爬虫页面
首先看循环代码,因为豌豆荚的总分页,看了一下,最大42页,而且是全部分类,显然我们用不到全部分类的,每个大分类下面差不多6个小分类,小分类吗,总共是42页,6个小分类,我就算极端一下,一个小分类全部囊括了,也就42页的罢了。所以,我们生命循环次数是42次,然后第一页的话,我们分析了是没有'/1'这种序号的,可以看一下截图例子。
移除第一页
第一页
移除第二页
第二页
移除第三页
第三页,所以第一页,不需要拼接/1,然后我们读取文件后写入配置好的路径。其他的随意。
好,接下来,看这个,爬取网页代码,try、except代码,获取url就去爬取了,try部分还可以理解的,到了except代码,那就是递归了,一般地两次就出来了。
报错重跑机制,还不完善,但是完全够解决现阶段的错误了。可以摆脱urlerror:10004报错
这里后期我们优化可能要加一个全局变量,限制递归次数,这个小优化,我后期加上,如果超过了5次,我们直接把这个response返回一个空字符串出来就行了,让第四步分析的时候不分析算了。
第三部分结果
移除6090张html页面
精髓就在这个递归,就是报错重跑url了。第二步加第三部,合起来组成了队列的思想。
第四部分代码依然是java代码,就是说,程序爬取页面用的是python的类库, 分析解析用的是java,第四部分代码全粘贴:
package step;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 该类用来解析所有html文件
*
* @author lishouzhuang
*
*/
public class step4 {
//所有数据map用作,数据去重
static Map map =new HashMap();
public static void doStep4(Map propertisPathmap) throws IOException {
// 设置生成文件路径以及文件名
String finalResultfilePath = (String) propertisPathmap.get("finalResultfilePath");
// 设置路径:所有html位置
//String url = "F:\\python\\file_backups\\";
String allHtmlPath = (String) propertisPathmap.get("allHtmlPath");
// //设置生成文件路径名称位置,需要去解析路径
ifFileHave(allHtmlPath, 2);//检查url.txt是否存在
System.out.println("------------start-------------------");
showName(allHtmlPath, finalResultfilePath);
System.out.println("-------------end----------------");
}
public static void clean(String url, String fileUrl) throws IOException {
// File input =new File("F:\\python\\file\\result_716_1.html");
// 循环拿到url
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
// 以下方法为了获得“影音播放”,操作dom
Elements movieAndMusic = doc.getElementsByClass("third");
/**
* * itemtype="http://data-vocabulary.org/Breadcrumb"> * 影音播放
*/
// 将div的class为third的元素中的分类名称取出
Elements aEle= movieAndMusic.select("a");
String Mname = aEle.html();
if(Mname==null && "".equals(Mname)){
Mname = "null";
}
// 以下方法为了获得分类名称
// 查找第一个h1元素//视频下载
Element link = doc.select("h1").first();
String TypeString = "";
//这里是为了有时候页面出现h1没有的情况,要做特殊处理
if(link == null){
//调错,找到错误原因
System.out.println("link is null! ");
System.out.println("you have no link file :"+url);
TypeString="null";
// 使用方法1,分割:“下载”
String preString1 = TypeString;
// 操作dom,获取所有class为card的,他们都是应用的div,即可获取应用所有的html对象
Elements link2 = doc.getElementsByClass("card");
String result = "";
for (int i = 0; i < link2.size(); i++) {
// 依次创建Element对象,封装所有的div
Element ele = link2.get(i);
// 将带有a标签的对象带出来,a标签中,有href、title等等元素,可以提取
Element h2 = ele.select("h2").select("a").first();
// 获取href引用字符串
String str_href_all = h2.attr("href");
// 这里调用changeString的第二个方法
String str_href = changeString(str_href_all, 2);
// 获取title应用名称
String str_title = h2.attr("title");
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
//System.out.println(result);
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
}
}else{
try{
// 拿到分类名称 例如 视频下载
TypeString = link.html();
}catch(Exception e){
e.printStackTrace();
}
// 使用方法1,分割:“下载”
String preString1 = changeString(TypeString, 1);
// 操作dom,获取所有class为card的,他们都是应用的div,即可获取应用所有的html对象
Elements link2 = doc.getElementsByClass("card");
String result = "";
for (int i = 0; i < link2.size(); i++) {
// 依次创建Element对象,封装所有的div
Element ele = link2.get(i);
// 将带有a标签的对象带出来,a标签中,有href、title等等元素,可以提取
Element h2 = ele.select("h2").select("a").first();
// 获取href引用字符串
String str_href_all = h2.attr("href");
// 这里调用changeString的第二个方法
String str_href = changeString(str_href_all, 2);
// 获取title应用名称
String str_title = h2.attr("title");
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
}
//// 写入文件,传入参数,结果字符串,以及文件路径
//writeTxt(result, fileUrl);
}
}
// 字符串处理
public static String changeString(String str, int type) {
String resolve = "";
// 方法变换
if (type == 1) {
// 方法一
// 如果type等于1,将下载去除
// 拿到应用名下载 变成 拿到应用名
resolve = str.substring(0, str.length() - 2);// 这里截取的信息就是e,倒数第二个字符
} else {
// 方法二
// 切割得到包名
// http://www.wandoujia.com/apps/com.synprez.fm 变成 com.synprez.fm
String[] strArr = str.split("/");
resolve = strArr[strArr.length - 1];
}
return resolve;
}
/**
* 该方法用于输出该html输出字段
*
* @param str
* @param fileUrl
*/
public static void writeTxt(String str, String fileUrl) {
FileWriter writer;
try {
// 打开一个写文件器,构造函数中的第二个参数true表示以追加形式写文件
writer = new FileWriter(fileUrl, true);
writer.write(str);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
*
* @param HtmlsPath
* @return
*/
public static List getFileName(String HtmlsPath) {
// String path = "F:/python/file2"; // 路径F:\python\file2
String path = HtmlsPath;
File f = new File(path);
if (!f.exists()) {
System.out.println(path + " not exists");
return null;
}
List list = new ArrayList();
File fa[] = f.listFiles();
for (int i = 0; i < fa.length; i++) {
File fs = fa[i];
// if (fs.isDirectory()) {
// System.out.println(fs.getName() + " [目录]");
// } else {
// System.out.println(fs.getName());
// System.out.println(fs.getPath());
// }
list.add(fs.getPath());
}
System.out.println(list.size());
return list;
}
/**
* 获取该url下所有的文件 假设url为 F:\\python\\file\\
*
* @param url
* @param fileUrl
* @throws IOException
*/
public static void showName(String url, String fileUrl) throws IOException {
List list = getFileName(url);
for (int i = 0; i < list.size(); i++) {
// 循环执行清洗数据
String uri = (String) list.get(i);
clean(uri, fileUrl);
}
}
/**
* 该方法用来检测文件和文件夹是否已经存在,
* 如果是文件,不存在即创建,存在即删除;如果是文件夹,不存在创建
* @param filepath
* @param type
*/
public static void ifFileHave(String filepath,int type){
//File file=new File("F:\\python\\6.txt");
File file=new File(filepath);
if(type==1){//如果type为1说明是文件
if(!file.exists()){
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}else{//如果文件已经存在,我们需要删除
System.out.println(file+" is already exist,We should delete it and mkdir.");
file.delete();
try {
System.out.println(file+" is not exist , now create this file . ");
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
}else{//如果type为2说明是文件夹
//如果文件夹不存在则创建
if (!file .exists() && !file .isDirectory()){
System.out.println(file+": directory is not exist , now create this dir . ");
file .mkdir();
} else{
System.out.println(file+": directory is already exist , We do not create this dir . ");
}
}
}
//测试main
public static void main(String[] args) throws IOException {
//doStep4(Map);
}
}
可以看到注释写的很详细。
老样子读取配置文件位置以及内容配置,将第三步骤中爬取的所有html页面全部解析。获取文件的方法咱们也就不多说了,以及读取文件夹下所有html的url,
移除获取文件夹下所有的html页面的文件名称和urlpath
获取文件夹下所有的html页面的文件名称和urlpath
移除给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
给定一个文件夹,获取文件夹下所有文件的名称, 返回一个list
写入结果文件的公共方法:
移除点击此处添加图片说明文字
好的,接下来我们去看clean方法,这是个代码解析了。
先看看这个。
移除源html页面
这两个红框框的部分是我们要获取的页面内容,两个,记住了,这就是分类了。
移除获取包名和url
获取包名,包名就是具体的应用了,和用户的实用软件可以关联了。
所以代码操作dom树也就不难解释了。
移除操作dom树
注释很清楚,
// 循环拿到url
File input = new File(url);
Document doc = Jsoup.parse(input, "UTF-8", "http://test.com/");
操作dom,拿到Elements movieAndMusic = doc.getElementsByClass("third");
// 将div的class为third的元素中的分类名称取出
Elements aEle= movieAndMusic.select("a");
String Mname = aEle.html();
if(Mname==null && "".equals(Mname)){
Mname = "null";
}
// 以下方法为了获得分类名称
// 查找第一个h1元素//
视频下载
Element link = doc.select("h1").first();
这里是为了有时候页面出现h1没有的情况,要做特殊处理,有时候确实会没有这个h1,别奇怪
if(link == null){
然后这个是主要代码逻辑:
移除获取元素代码部分
得到的card元素是一个集合,我们从集合中将每个元素取出,每个div里面有h2的a标签里面就是包的href和title,然后我们拼接。
// 拼接最后的输出字符串,得到应用名和包名
result = Mname + "|" + preString1 + "|" + str_href + "|" + str_title + "\n";
注意这里还不能写,没有结束。
hive导入时我们发现:
影音播放K歌cn.kuwo.player酷我音乐20170712
影音播放铃声cn.kuwo.player酷我音乐20170712
影音播放音乐cn.kuwo.player酷我音乐20170712
就是一个应用会出现三个分类,这给我们后面做用户画像时的表关联带来了困难。所以,现阶段,我们只去第一个包分类。
所以,我们筛选去除后面两个分类,用hashmap的key去重,
//在这里我们要去重了,使用全局map来做这件事情,就是说,如果这个map的key没有的话,我们才会放进去,有的话就不动了
if(!map.containsKey(str_href)){
map.put(str_href,result);
// 写入文件,传入参数,结果字符串,以及文件路径
writeTxt(result, fileUrl);
}
到了这里,我们就可以看一下输出结果了,基本上大功告成了:
移除结果文件
最后的最后,我们需要一个调度方法,也就是step5的java类。
这个类要满足,可以读取配置文件,并且执行python脚本代码。
代码粘贴再分析:
package step;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Properties;
public class step5 {
public static void main(String[] args) throws IOException {
//主函数
//四步走战略
//读取properties文件位置
String propertisPath = "/project/project/test/main.properties";
//String propertisPath = "F:\\python\\project\\main.properties";
Map propertisPathmap = doProperties(propertisPath);
//先声明两个python脚本的位置
String python1 = (String) propertisPathmap.get("pythonPathStep1");
String python2 = (String) propertisPathmap.get("pythonPathStep3");
//step1
doPythonCmd(python1);//执行第一步,爬app和game两个网页
//step2
System.out.println("create step2 and run step2----------");
step2 step2 = new step2();
step2.doStep2(propertisPathmap);
//step3
doPythonCmd(python2);//执行爬虫程序,爬所有网页下来
//step4
System.out.println("create step4 and run step4----------");
step4 step4 = new step4();
step4.doStep4(propertisPathmap);
}
/**
* 该类用来读取python脚本文件
* @param cmd_ython
*/
public static void doPythonCmd(String cmd_ython){
//java运行python脚本
try{
System.out.println("start step:"+cmd_ython);
Process pr = Runtime.getRuntime().exec(cmd_ython);
BufferedReader in = new BufferedReader(new
InputStreamReader(pr.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
System.out.println(line);
}
in.close();
pr.waitFor();
System.out.println("end step:"+cmd_ython);
} catch (Exception e){
e.printStackTrace();
}
}
/**
* 给方法用来读取配置文件
* @param propertisUrl
* @return
*/
public static Map doProperties(String propertisUrl){
Properties prop = new Properties();
Map map= new HashMap();
try{
//读取属性文件a.properties
// InputStream in = new BufferedInputStream (new FileInputStream("F:\\python\\pachong.properties"));
InputStream in = new BufferedInputStream (new FileInputStream(propertisUrl));
prop.load(in); ///加载属性列表
Iterator
while(it.hasNext()){
String key=it.next();
System.out.println(key+":"+prop.getProperty(key));
map.put(key, prop.getProperty(key));
}
in.close();
// ///保存属性到b.properties文件
// FileOutputStream oFile = new FileOutputStream("F:\\python\\pachong.properties", true);//true表示追加打开
// prop.setProperty("phone", "10086");
// prop.store(oFile, "The New properties file");
// oFile.close();
}
catch(Exception e){
System.out.println(e);
}
return map;
}
}
先看两个公共方法,
移除读取配置文件,并且得到参数方法
注释很详细,就不过多解释了,读取之后,map形式传出去。
移除执行python脚本的公共方法
执行python脚本的公共方法,给入python脚本,然后start step :python脚本,采用runtime的方式。最后,调度类:
移除所有调度方法依次执行。
很清晰吧。然后,所有的中间过程和jar包都在这里了。
移除所有的中间过程和jar包
现在目前使用起来,经过测试是很稳定的,遇到一些不稳定因素已经被处理了,遇到了很多的坑,也都一一解决了。最恶心的是那个重跑url内所有的42个分页的方法,想了比较久,甚至想过写个list实现的txt从中间拿一个爬一个,后来想到了递归。
其实坑不止这些,还有很多很多细节去做了处理,版本打了很多:
移除各个版本
后期优化,如果需要还要继续,我记得多线程也得去做一下,等后期有空了,空闲了,要继续研究一下了,目前1个半小时之内,绝对可以搞定,每周爬一次,完全够用了。
好了,python开发的基本思路和代码分析就到这里了。