mongodb分页,ObjectId顺序,雪花算法生成高精度时间戳
公司硬件产品与netty服务器用长连接通信,通信消息使用mogodb来保存提供日志功能,按照月份创建mgDB集合。周末两天因为一台异常设备不停重启然后从服务器要数据,造成单个集合文档一下增加到400w条,查询的时候内存溢出。测试阶段仅仅一台异常设备就把mgDB塞这么多,除了netty服务端增加消息限流之外,修改mongodb日志分页搜索取消skip这种查询方式。
- 1.skip分页方式
skip和limit实现分页,就是很慢。
public List> queryPageByCondition(DB mydb,DBCollection collection,Integer page,Integer size,BasicDBObject conditions,BasicDBObject sort){
DBCursor dbCursor =null;
mydb.requestStart();
if(size==0){//不分页
if(conditions!=null&&!conditions.isEmpty()){
dbCursor = collection.find(conditions).sort(sort);
}else {
dbCursor = collection.find().sort(sort);
}
}else {
if(conditions!=null&&!conditions.isEmpty()){
dbCursor = collection.find(conditions).skip((page - 1) * size).sort(new BasicDBObject()).limit(size).sort(sort);
}else {
dbCursor = collection.find().skip((page - 1) * size).sort(new BasicDBObject()).limit(size).sort(sort);
}
}
mydb.requestDone();
List> retMaps = new ArrayList>();
while(dbCursor.hasNext()){
Map map = parseRet(dbCursor.next());
retMaps.add(map);
}
return retMaps;
} - 2.非skip分页方式
首先按照大排序前提(我这里是时间戳),当前页(size=20)第一条数据和最后一条数据,从第一条数据向前找size条就是上一页,从最后一条数据向后size条就是下一页。所以这里把这一条特殊数据的时间戳当成查询条件来查询就不需要用skip来跳过数据。只是需要分降序和升序而已。
//下一页
//mydb:库
//collection:集合
//size:条数
//conditions:高级查询条件
//sortKey:总排序字段
//sortType:总排序方式,1升序,-1降序
//limitValue:总排序字段的limit起始值
//(升序的话,按照conditions查集合之后,从起始值开始向后取size条)
//(降序的话,按照conditions查集合之后,从起始值开始向后取size条)
public List> nextPageByCondition(DB mydb,DBCollection collection,Integer size,BasicDBObject conditions,String sortKey,Integer sortType,Long limitValue){
DBCursor dbCursor =null;
mydb.requestStart();
if(conditions==null){
conditions = new BasicDBObject();
}
//如果传入了起始值
if(limitValue>0){
//降序
if(sortType==-1){
//小于起始值
BasicDBObject lt = new BasicDBObject();
lt.put("$lt",limitValue);
conditions.put(sortKey,lt);
}
//升序
else if(sortType==1){
//大于起始值
BasicDBObject gt = new BasicDBObject();
gt.put("$gt",limitValue);
conditions.put(sortKey,gt );
}
}
//排序字段
BasicDBObject sort = new BasicDBObject();
sort.put(sortKey,sortType);
dbCursor = collection.find(conditions).sort(sort).limit(size);
mydb.requestDone();
//按照原顺序插入map,返回
List> retMaps = new ArrayList>();
while(dbCursor.hasNext()){
Map map = parseRet(dbCursor.next());
retMaps.add(map);
}
return retMaps;
}
//上一页
//mydb:库
//collection:集合
//size:条数
//conditions:高级查询条件
//sortKey:总排序字段
//sortType:总排序方式,1升序,-1降序
//limitValue:总排序字段的起始值
//(升序的话,按照conditions查集合之后,从起始值开始向前取size条)
//(降序的话,按照conditions查集合之后,从起始值开始向前取size条)
public List> prevPageByCondition(DB mydb,DBCollection collection,Integer size,BasicDBObject conditions,String sortKey,Integer sortType,Long limitValue){
DBCursor dbCursor =null;
mydb.requestStart();
if(conditions==null){
conditions = new BasicDBObject();
}
//如果传入了起始值
if(limitValue>0){
//降序
if(sortType==-1){
//大于起始值
BasicDBObject gt = new BasicDBObject();
gt.put("$gt",limitValue);
conditions.put(sortKey,gt);
}
//升序
else if(sortType==1){
//小于起始值
BasicDBObject lt = new BasicDBObject();
lt.put("$lt",limitValue);
conditions.put(sortKey,lt);
}
}
//排序字段
BasicDBObject sort = new BasicDBObject();
sort.put(sortKey,sortType);
//倒序字段
BasicDBObject _sort = new BasicDBObject();
_sort.put(sortKey,-sortType);
dbCursor = collection.find(conditions).sort(_sort).limit(size);
mydb.requestDone();
//按照倒序插入map
List> retMaps = new ArrayList>();
while(dbCursor.hasNext()){
Map map = parseRet(dbCursor.next());
retMaps.add(map);
}
//因为limit取的时候按照原顺序倒序取得size条,返回的时候奖结果集倒回去
//用collection.find(conditions).sort(_sort).limit(size).sort(sort)方式不行
Collections.reverse(retMaps);
return retMaps;
} 但是这种方式分页方式有问题,我这里因为时间戳毫秒级别不能保证唯一,那么将skip变成“大于起始值(升序下一页/降序上一页)或者小于起始值(升序上一页/降序下一页)”条件的时候,在一段连续数据中时间戳都等于起始值的话会被排除到下一次分页之外漏掉一部分数据 ,如果gt变成gte的话会查询出重复的数据,当pageSize=20时而且连续30条数据时间戳和起始值一样那么分页失效始终查询的同一批数据段。
- 3.ObjectId顺序问题
mongodb的ObjectId由:时间戳+机器号+PID+计数器组成,可以保证唯一性,可以通过getTimestamp()获取客户端生成记录的时间戳,另一方面一个集合中实际的存储是无顺序的。
取一条记录,用getTimestamp获取的时间戳精度只到秒级。要求不高只需要到秒级且客户端可能是集群的时候,文档未保存时间戳又需要使用个客户端时间戳来排序的时候可以直接取这个时间戳来排序:
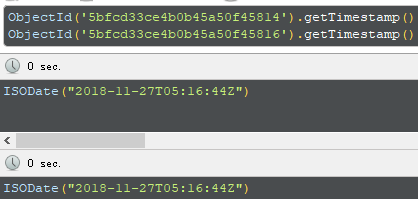
ObjectId默认情况下由客户端生成(java是这样),如果客户端是同一进程的话只有最后的计数器不一致,所以这种情况下集合中文档可以保证按照ObjectId大小全局有序(但不是按照插入时间,因为多个线程按照顺序生成了ObjectId但是最后提交到mgdb中是谁先提交成功谁先插入,可以说大致按照时间排序),下面按照ObjectId降序排序,投影选择业务时间戳,可以看出顺序和我保存的业务时间戳大致一样,如果非要排序而且文档中没有保存时间戳的时候,同时客户端是单进程的时候可以按照ObjectId来排序分页:
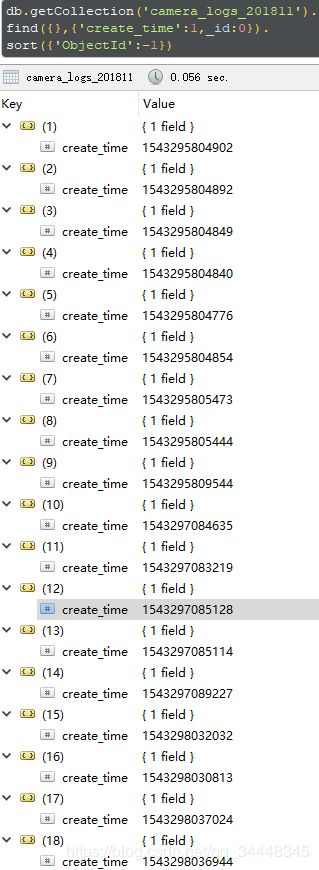
- 4._id自增
如果客户端是集群那么ObjectId顺序连“大致按照时间排序”都说不上,完全是乱序的,且对排序精度要求高(秒级都不够)的话都不能取最前面的时间戳来排序,只能对ObjectId进行排序,一种方式是用findAndModify实现_id自增。
//获取自增id
public static long getNext( DBCollection collection){
long incId = 0;
try {
DBObject ret = collection.findAndModify(
new BasicDBObject("_id", "index"), null, null, false,
new BasicDBObject("$inc", new BasicDBObject("index", 1)),
true, true);
incId = Long.valueOf(ret.get("index").toString());
} catch (Exception e) {
e.printStackTrace();
}
return incId;
}
//插入并自增
public static void insertCollectionAndIncrement(String collectionName,BasicDBObject obj){
mydb.requestStart();
DBCollection collection = mydb.getCollection(collectionName);
obj.put("_id",getNext(collection));
WriteResult result = collection.insert(obj);
mydb.requestDone();
}这样客户端集群同时入库的时候可以按照_id自增而且谁先提交谁插入成功,但是这种方式会降低插入效率。另一方面mongodb集群会复制+分片,复制集上说维护冗余数据会更慢,分片上说在跨网络节点来协调并分配id也会更慢:

- 5.雪花算法提高时间戳精度
可以先看一下美团的分布式id生成方案leafleaf
我这里netty服务器(集群)重启的时候会有大批设备上行登录,一个服务器线程数量在3000~5000个左右,同时获取时间戳很容易就大批数据时间戳一致造成分页失效。解决办法是排序大前提选全局唯一自增Id,只要不重复就行。但是我这里按照时间段分页是基本要求,所以方向是提高时间戳精度。
ObjectId就是类似雪花算法生成id,不过在多客户端进程(比如我这里netty集群)下会造成部分乱序,不过这里用雪花算法的好处就是机器号可以自己指定,如下:
import java.util.Date;
public class SnowFlakeIdWorker {
//其实时间:2015-01-01
private final long twepoch = 0;
//机器Id 占用的位数:5
private final long workerIdBits = 5L;
//数据标识Id 占用的位数:5
private final long datacenterIdBits = 5L;
//机器Id 最大值:31
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
//数据标识Id 最大值:31
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号占用的位数:12
private final long sequenceBits = 12L;
//机器Id左移12位
private final long workerIdShift = sequenceBits;
//数据标识Id左移17位
private final long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳左移22位
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//4095,序列号范围
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
//机器Id
private long workerId;
//数据中心Id
private long datacenterId;
//毫秒内序列(0-4095)
private long sequence = 0L;
//生词生成Id的时间戳
private long lastTimestamp = -1L;
//构造器
private SnowFlakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
//获得下一个ID
public synchronized long nextId() {
long timestamp = timeGen();
//防止系统时间回退
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//同一个毫秒时间戳,说明都在一个毫秒内生成的
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;//加1
//4095用完,则丢弃timeGen()生成的时间戳,用tilNextMillis()生成的下一个毫秒内的时间戳
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
//更新
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
}
//阻塞到下一个毫秒,直到获得新的时间戳
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取当前时间戳
protected long timeGen() {
return System.currentTimeMillis();
}
private final static SnowFlakeIdWorker idWorker= new SnowFlakeIdWorker(1, 1);
public static SnowFlakeIdWorker getInstance(){
return idWorker;
}
public static void main(String[] args) {
/*
long id = 0L;
//-----------------时间戳-------------------|-机器号|--机器数据-|-0到4095序列-
//10110011101011110001101001000100011100101 | 00001 | 00001 | 000000011101
System.out.println("二进制:"+(Long.toBinaryString(id)));//时间戳
for(int i=0;i<5000;i++){
id = SnowFlakeIdWorker.getInstance().nextId();
System.out.println("long:"+id+",time:"+new Date((id>>22))+",timeStamp:"+(id>>22));
}
*/
}
}集群中用不同的机器号(workId)生成Id的话得到的效果就和mongodb的ObjectId一样了(总体有序、局部乱序,集群节点越多乱序就严重),客户端集群指定相同的机器号(workId)的话得到的带有时间戳的id肯定有冲突,但是精度提高,1秒内有4095000个id冲突比之前1秒内1000个id小很多。
如果必须使用时间戳做排序前提,客户端是集群,时间戳ms级别不够,而且时间戳必须严格按照时间戳全局有序递增的话还有一种处理方式,将雪花算法单独拿出来做成Id接口服务,客户端集群从Id接口拿这样就可以实现分布式全局严格按照时间递增,貌似美团就是直接做的一个id服务。
还有一个问题就是我前端vue需要从id中解析出时间戳,js支持的整型最长为53位,这里生成的id是63位的,正好我这里不需要区别集群机器,所以改代码把机器号占用的位数去掉,直接workerIdBits和datacenterIdBits俩参数置0就ok了,得到的id二进制的样子大概是这样子的:
//-----------------时间戳--------------------|-0到4095序列-
//10110011101011110001101001000100011100101 | 000000011101
for(int i=0;i<1;i++){
id = SnowFlakeIdWorker.getInstance().nextId();
System.out.println("id:"+id);
System.out.println("id二进制:"+(Long.toBinaryString(id)));
System.out.println("timeStamp二进制:"+(Long.toBinaryString(id>>12)));
}前端利用二进制转化和字符串截取就很容易取出时间戳了:
//js解析
var num = 6322349191770119;
var num_2_string = num.toString(2);
console.log('二进制字符串:'+num_2_string);
var _num_2_string = num_2_string.substring(0,41);//截取字符串前41位k
console.log('截取后的二进制字符串:'+_num_2_string);
var timeStamp = parseInt(_num_2_string,2);
console.log('时间戳:'+timeStamp);
console.log('右移操作:'+num>>12);到这里问题大概结局了,至于id冲突的问题后期再看吧。