selenium 的使用
高级爬虫: 让 Selenium 控制你的浏览器帮你爬
作者: 莫烦 编辑: 莫烦 2017-12-30
学习资料:
- 本节学习代码
- Selenium Python 官网
Selenium 是为了测试而出生的. 但是没想到到了爬虫的年代, 它摇身一变, 变成了爬虫的好工具. 让我试着用一句话来概括 Seleninm: 它能控制你的浏览器, 有模有样地学人类”看”网页.

那么你什么时候会要用到 Selenium 呢? 当你:
- 发现用普通方法爬不到想要的内容
- 网站跟你玩”捉迷藏”, 太多 JavaScript 内容
- 需要像人一样浏览的爬虫
安装 Selenium
因为 Selenium 需要操控你的浏览器, 所以安装起来比传统的 Python 模块要多几步. 先在 terminal 或者 cmd 用 pip 安装 selenium.
# python 2+
pip install selenium
# python 3+
pip3 install selenium
要操控浏览器, 你就要有浏览器的 driver. Selenium 针对几个主流的浏览器都有 driver. 针对 Linux 和 MacOS.
- Chrome driver
- Edge driver
- Firefox driver
- Safari driver
Linux 和 MacOS 用户下载好之后, 请将下载好的”geckodriver”文件放在你的计算机的 “/usr/bin” 或 “/usr/local/bin” 目录. 并赋予执行权限, 不会放的, 请使用这条语句.
sudo cp 你的geckodriver位置 /usr/local/bin
sudo chmod +x /usr/local/bin/geckodriver
对于 Windows 用户, 官网上的说法, 好像没有提到要具体怎么操作, 我想, 应该是把 geckodriver 这个文件的位置加在 Windows 的环境变量中(PATH).
如果你安装有任何的问题, 请在它们的官网上查询解决方案.
偷懒的火狐浏览器插件
在这教你用火狐浏览器偷懒的一招, 因为暂时只有火狐上有这个插件. 插件 Katalon Recorder 下载的网址在这

这个插件能让你记录你使用浏览器的操作. 我以前玩网游, 为了偷懒, 用过一个叫”按键精灵”的东西, 帮我做了很多重复性的工作, 拯救了我的鼠标和键盘, 当然还有我的手指! 看着别人一直在点鼠标, 我心中暗爽~ 这个 Katalon Recorder 插件 + Selenium 就和按键精灵是一个意思. 记录你的操作, 然后你可以让电脑重复上千遍.
安装好火狐上的这个插件后, 打开它.
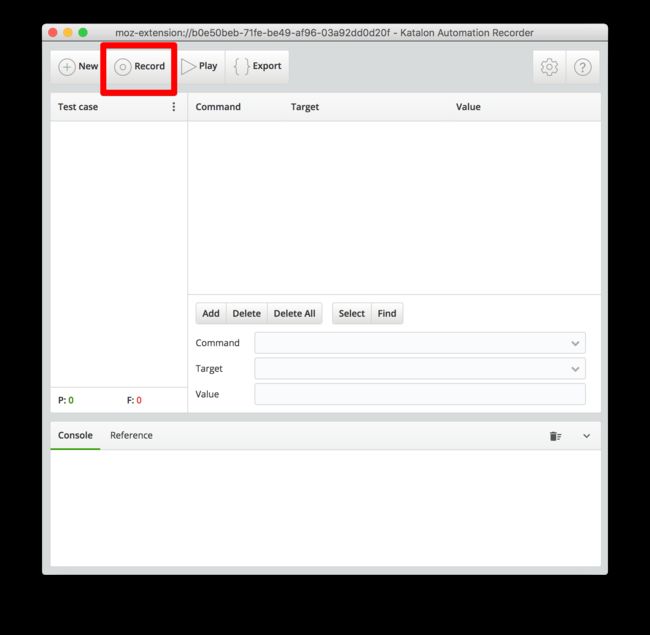
找到插件上的 record, 点它. 然后用火狐登录上 莫烦Python, 开始你的各种点击工作, 比如我的一连串操作是 (强化学习教程->About页面->赞助页面->教程->数据处理->网页爬虫)
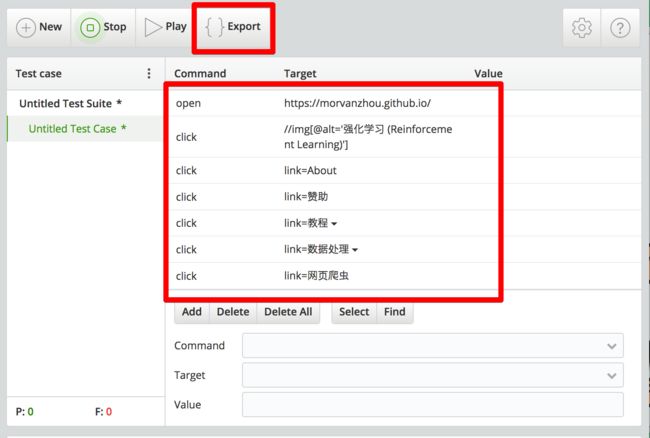
每当你点击的时候, 插件就会记录下你这些点击, 形成一些log. 最后神奇的事情将要发生. 你可以点击 Export 按钮, 观看到帮你生成的浏览记录代码!
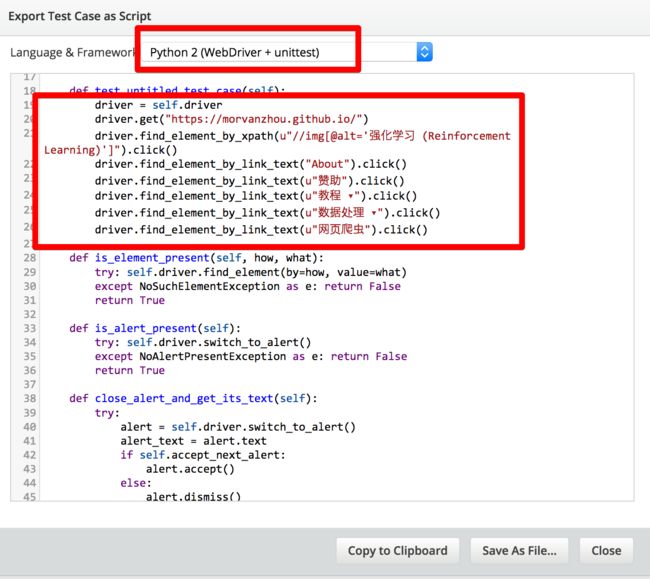
虽然这个代码输出只有 Python2 版本的, 不过不影响. 我们直接将这些圈起来的代码复制. 这将会是 python 帮你执行的行为代码.
Python 控制浏览器
好了, 有了这些代码, 我们就能回到 Python. 开始写 Python 的代码了. 这里十分简单! 我将 selenium 绑定到 Chrome 上 webdriver.Chrome(). 你可以绑其它的浏览器.
from selenium import webdriver
driver = webdriver.Chrome() # 打开 Chrome 浏览器
# 将刚刚复制的帖在这
driver.get("https://morvanzhou.github.io/")
driver.find_element_by_xpath(u"//img[@alt='强化学习 (Reinforcement Learning)']").click()
driver.find_element_by_link_text("About").click()
driver.find_element_by_link_text(u"赞助").click()
driver.find_element_by_link_text(u"教程 ▾").click()
driver.find_element_by_link_text(u"数据处理 ▾").click()
driver.find_element_by_link_text(u"网页爬虫").click()
# 得到网页 html, 还能截图
html = driver.page_source # get html
driver.get_screenshot_as_file("./img/sreenshot1.png")
driver.close()
我们能得到页面的 html code (driver.page_source), 就能基于这个 code 来爬取数据了. 最后爬取的网页截图就是这样.
不过每次都要看着浏览器执行这些操作, 有时候有点不方便. 我们可以让 selenium 不弹出浏览器窗口, 让它”安静”地执行操作. 在创建 driver 之前定义几个参数就能摆脱浏览器的身体了.
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # define headless
driver = webdriver.Chrome(chrome_options=chrome_options)
...
最后同样再截一张图, 证明 driver 真的爬到了这个 “网页爬虫” 教程页面. 不过因为没有出现实体的浏览器, 这个页面大小和上面的图片还是有点差别的.

Selenium 能做的事还有很多, 比如填 Form 表单, 超控键盘等等. 这个教程不会细说了, 只是个入门, 如果你还想继续深入了解, 欢迎点进去他们的 Python 教学官网.
最后, Selenium 的优点我们都看出来了, 可以很方便的帮你模拟你的操作, 添加其它操作也是非常容易的, 但是也是有缺点的, 不是任何时候 selenium 都很好. 因为要打开浏览器, 加载更多东西, 它的执行速度肯定没有其它模块快. 所以如果你需要速度, 能不用 Selenium, 就不用吧.
相关教程
- 简单的分布式爬虫
- 加速爬虫: 异步加载 Asyncio
- 高级爬虫: 让 Selenium 控制你的浏览器帮你爬
- 高级爬虫: 高效无忧的 Scrapy 爬虫库
分享到: 



如果你觉得这篇文章或视频对你的学习很有帮助, 请你也分享它, 让它能再次帮助到更多的需要学习的人. 莫烦没有正式的经济来源, 如果你也想支持 莫烦Python 并看到更好的教学内容, 赞助他一点点, 作为鼓励他继续开源的动力.。
声明:转载自莫凡的教程。他做得很好,也希望他的人气高起来。