初始机器学习-笔记
初始机器学习
2-1 什么是机器学习
利用计算机从历史数据中找出规律,并把这些规律用到对未来不确定场景的决策
例如预测天气 公司业绩
2-2 从数据中寻找规律
用模型刻画(拟合)规律
函数——函数曲线——拟合
实际解决问题时,有几百维,很难用可视化的方法去描述问题
2-3 机器学习发展的原动力
从历史数据中找出规律,把这些规律用到对未来自动作出决定。
用数据代替expert——业务逻辑
经济驱动,数据
2-4 业务系统发展的历史
1.基于专家经验
2.基于统计-分维度统计
3.机器学习=在线学习
机器学习两种使用场景 离线学习和在线学习。
离线学习:批处理的方式,对以前的数据进行学习,从而运用到后面的指导中
在线学习:对实时产生的数据进行学习,再对实时得业务进行指导
3-1 机器学习的典型应用:
购物篮分析
所谓的购物篮分析就是看在我们的订单中有哪些商品是被同时购买的
用到的算法就是关联规则(实质上是数据挖掘的算法)
3-2 机器学习的典型应用:
用户细分精准营销
聚类(比如:把用户数据拿过来给算法,对用户进行分类)
3-3 机器学习的典型应用:
垃圾邮件 朴素贝叶斯
信用卡欺诈 决策树(风险识别)
3-4 crt预估和协同过滤
互联网广告:crt预估(线性回归),预测最有可能点的广告排在第一名
推荐系统:协同过滤
3-5 机器学习的典型应用:
自然语言处理
情感分析:比如:通过用户的评价判断该用户是积极用户还是消极用户。
实体识别:比如:将一篇文章的主体部分提炼出来
图像识别 深度学习
更多应用 : 语音识别 个性化医疗 情感分析 人脸识别 自动驾驶 智慧型机器人 私人虚拟助理 手势控制 视频内容自动识别
4-1 机器学习和数据分析的区别
一、数据特点不同(数据类别、数据量、数据分析方法)
机器学习:行为数据(如搜索历史、浏览历史、点击历史、评论等);海量分析,一致性要求相对不高;全量分析
数据分析:交易数据(与钱相关,如用户订单、存取款账单、话费账单等)少量数据,一致性要求严格(如银行存取款,数据精准);采样分析
二、解决业务问题不同
机器学习:预测未来事件(未来趋势)
数据分析:报告过去事件(历史总结)
三、技术手段、方法不同
机器学习:数据挖掘;数据(算法)驱动;规模大
数据分析:OLAP;用户驱动(企业数据分析师的经验等);规模小;交互式分析
缺点:受限于分析师的经验,分类的多样化受限制
四、参与(驱动)者不同
机器学习:数据+算法,数据质量决定结果
数据分析:数据分析师,能力&经验决定结果
五、服务用户不同
机器学习:个体用户
数据分析:公司高层
5-1 机器学习常见算法和分类(1)
算法分类:
分类1
(1)有监督学习:1)分类算法:Y类:垃圾邮件、X类:正常邮件;2)回归算法
(2)无监督学习:Y是什么类型我们不知道,聚类:让机器去数据自行分析
(3)半监督学习:强化学习,小孩学走路
分类2:
分类与回归
聚类
标注
分类3(最重要):
生成模型:告诉你属于哪个类的概率
判别模型:直接判别数据属于哪个类别
5-2 机器学习常见算法和分类(2)
机器学习常见算法:
决策树算法(有监督):解决分类、回归问题;C4.5、kNN(不常用)
聚类:K-Means算法(无监督)
统计学习:SVM算法
关联分析及规则:Apriori(淘汰)——需多次扫描庞大数据库
FP-Growth——仅需两次扫描数据库
链接挖掘:PageRank算法(Google)
集装与推进:AdaBoost(人脸识别)(决策树改进版,有监督学习)(本质上解决分类问题)
逻辑回归:google、百度搜索结果排
推荐算法:产品推荐等
文本分析&挖掘、自然语言处理:LDA、Word2Vector、HMM、CRF
深度学习:图像识别
常见算法:
FP-Growth:华人发明
逻辑回归:谷歌百度搜素排名
RF、GBDT:随机森林,决策算法的改进
推荐算法:各大电商网站的标配
LDA:文本分析、自然语言算法
Word2Vector:文本挖掘
HMM、CRF:隐马可夫模型、条件随机场
6-1 机器学习解决问题(1)
机器学习解决问题的框架:
一、目标的确立
STEP1:确定目标(业务需求)
STEP2:收集(历史)数据,决定项目质量高度
STEP3:特征工程(清理整合数据,提取特征)结构化,时间占比70%,很重要
6-2 6-2 机器学习解决问题(2)
图:分类/回归问题框架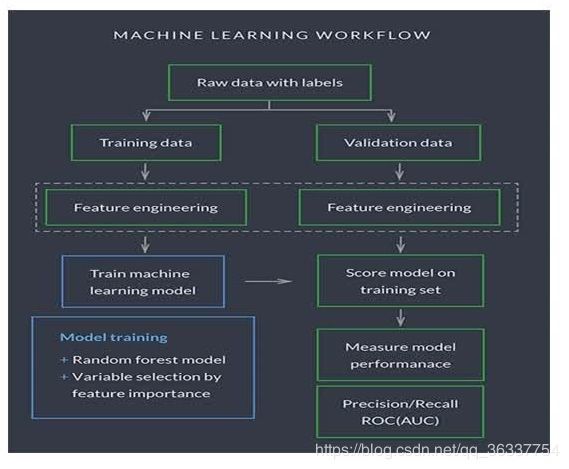
机器学习解决问题的框架:
二、训练模型
STEP1:定义模型(形成目标公式)
STEP2:定义损失函数(数学的方式定义预测值与现实值的差异)(决定了模型的好坏)
STEP3:优化算法(寻找确定损失函数极小值)
后两步最难
三、模型评估(标准)
STEP1:交叉验证
STEP2:效果评估