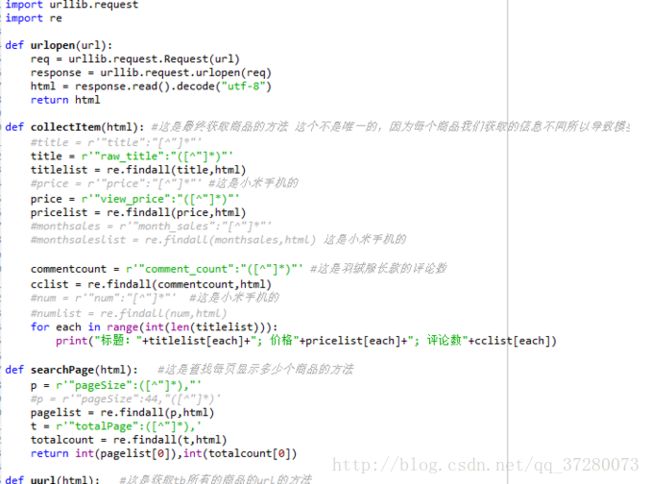
Pythpn 爬虫爬取某宝商品数据
这里没有采用框架 只是用了几个简单方法。
首先我们需要有一个获取html页面的方法:
def urlopen(url):
req =urllib.request.Request(url)
response =urllib.request.urlopen(req)
html =response.read().decode("utf-8")
return html
当然你也可以设置header等,之后我们需要获取所有商品的入口的链接 于是我们发现网址
https://www.taobao.com/tbhome/page/market-list?spm=a21bo.50862.201867-main.1.5dcec6f76GSCWA我们要获取的所有商品的入口在这个一个地址,

我们发现我们需要的链接在都在属性 def uurl(html): #这是获取tb所有的商品的url的方法 p = r' urllist =re.findall(p,html) urll = [] for each in urllist: new = re.subn("/","/",each) url =re.subn("&","&",new[0]) urll.append(url) return urll 有没有发现我的代码多了两行new =re.subn("/","/",each) url =re.subn("&","&",new[0]) 如果不加这两行我们发现,我们获取的url都变成了如下的格式: s.taobao.com/list?q=%E4%BE%BF%E6%B0%91%E6%9C%8D%E5%8A%A1&cat=50097750 我们发现这个网址是无法访问的,然后我们观察这个网址和能访问的网址,我们会发我们获取到的链接中的”&”都变成了” &” 而” /”都变成了” /” 所以我们要进行替换 到这里已经完成一大半了,至少我们获取到了全部的商品入口地址,之后我根据java爬虫的的经验(爬取得是某东),再就是获取商品信息了。 之后我们就要获取商品分类信息这里我本来想用一个通用的方法来获取的商品信息的,但是我不断的查看网页发现我简直在做梦, 某宝应该是为了反爬虫,不同的商品每页显示的商品的数量也是有差别的,有的商品的数据直接是通过ajax请求获取数据(这一类的我没有爬,如果想试一下的话可以用模拟鼠标点击来试一下) 我发现淘宝每页显示的商品信息的数量有 44 48 60 96 这几个数字,而且每个数字前面的参数也是不相同的比如44 后面跟着的参数是 “&p4ppushleft=1%2C48&s=” S是每页显示的个数,第一页是0之后每次加44 60后面的参数有两个一个是 “&bcoffset=12&s=”另一个出线的很少(我不会说我没记录下来,不过确实出现很少) 48 后面的参数是“&p4ppushleft=5%2C48&s=” 96比较特别参数直接是”&s=”也是从0开始是加在中间的,如果有兴趣可以自己做一下这个 我这里用的网站是:https://s.taobao.com/list?spm=a21bo.7723600.8224.30.162e5321pho4wV&q=%E9%95%BF%E6%AC%BE&style=grid&seller_type=taobao&cps=yes&cat=50099260当然你使用任何网站都可以,我用这个网站就是随便点的 小米手机的我也使用过,那个数据量太少我就弃用了 进入网站之后我们发现 我们用箭头所指的几个信息就是我们需要获取其中最上面箭头所指的是我们翻页的次数下面是我们对商品建模所需要的信息(我这里为了方便没有生成对象直接打印了) 看到这里我首先想到的是检查源代码 看看能不能获取到之后迎接给我的是一盆冷水, 我们检查源代码发现这些信息都在,但是我们通过urllib方法却获取不到这些信息,之后我就想这些数据既然有肯定会以某种方式被我们获取到,我首先想到了json 最终我也确实在json中找到了我想要的数据和商品的数据(眼都快找瞎了=.=) 我们发现json中有一个这一条这样的数据 pager":{"pageSize":60,"totalPage":100,"currentPage":1,"totalCount":115369}其中pageSize是我们每页显示的数量totalPage是一共有多少页(有些虽然写了100页但是也就780页左右) currentPage是当前页totalCount是总数 我就写了一个相应的方法如下: def searchPage(html): #这是查找每页显示多少个商品的方法 p =r'"pageSize":([^"]*),"' pagelist =re.findall(p,html) t =r'"totalPage":([^"]*),' totalcount =re.findall(t,html) returnint(pagelist[0]),int(totalcount[0]) 网页翻页解决了我们开始获取商品数据,当然这些数据也在json中,(真的找的眼都快瞎了) 我们发现会有以” p4pTags”出现的数据串,其中的raw_title是我们要找的标题,view_price是我们要找的价格,pic_url是图片地址item_loc是卖家地址view_sales是有多少买了(这里我就选了标题价格和多少人买了,需要注意的是每种商品的数据是不一样的,而且关键字也是不一样,这一个价格是view_price而小米手机的是price所以一个爬虫只能爬一个种类)代码如下 def collectItem(html): #title =r'"title":"[^"]*"' title =r'"raw_title":"([^"]*)"' titlelist =re.findall(title,html) #price =r'"price":"[^"]*"' #这是小米手机的 price =r'"view_price":"([^"]*)"' pricelist =re.findall(price,html) #monthsales =r'"month_sales":"[^"]*"' #monthsaleslist =re.findall(monthsales,html) 这是小米手机的 commentcount =r'"comment_count":"([^"]*)"' #这是羽绒服长款的评论数 cclist = re.findall(commentcount,html) #num =r'"num":"[^"]*"' #这是小米手机的 #numlist =re.findall(num,html) for each inrange(int(len(titlelist))): print("标题:"+titlelist[each]+"; 价格"+pricelist[each]+"; 评论数"+cclist[each]) 最后运行 当然这里还有些缺点,比如每页显示96的我就没有放在里面,而且没有这个爬虫不能爬取全站,代码也有点繁琐但是大多数的商品种类我们通过修改正则都可以获取到商品信息 最后是运行结果 还有很多的大约6000条左右的数据,如果我将一个品类的网址都放上肯 最后附上所有的代码截图 只用了urllib和re也从侧面体现了python的强大, 仅仅用了正则基本就把所需要的信息给获取到了,之后会继续改进这个爬虫,比如用选择器、框架等来简化代码加快运行速度,希望给同样在自学python的人有一些帮助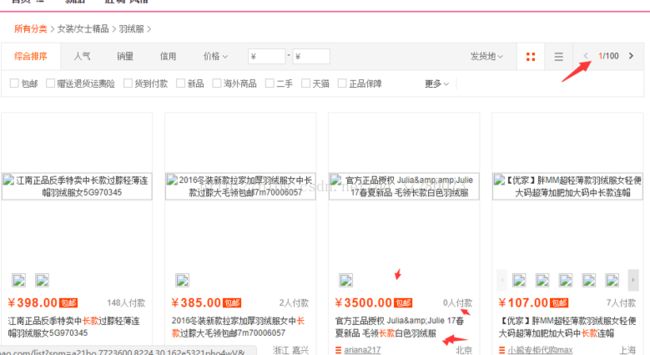


 定还有更多 。。。。。
定还有更多 。。。。。