MapReduce内部shuffle过程详解(Combiner的使用)
Maptask调用一个组件FileInputFormat
FileInputFormat有一个最高层的接口 --> InputFormat
我们不需要去写自己的实现类,使用的就是内部默认的组件:TextInputFormat
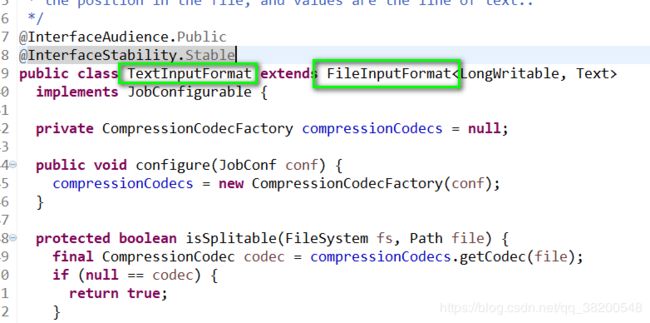
maptask先调用TextInputFormat, 但是实质读数据是TextInputFormat调用RecordReader。 RecordReader 是一个接口,这个接口的实现类调用read方法去读取数据。
InputFormat和RecordReader:
org.apache.hadoop.mapreduce包里的InputFormat抽象类提供了如下列代码所示的两个方法:
public abstract class InputFormat {
public abstract List getSplits(JobContext context);
RecordReader createRecordReader(InputSplit split, TaskAttemptContext context);
}
这两个方法展示了InputFormat类的两个功能:
- 将输入文件切分为map处理所需的split
- 创建RecordReader类,它将从一个split生成键值对序列
RecordReader类同样也是org.apache.hadoop.mapreduce包里的抽象类
public abstract class RecordReader implements Closeable {
/*
* 初始化RecordReader,只能被调用一次。
*/
public abstract void initialize(InputSplit split,
TaskAttemptContext context
) throws IOException, InterruptedException;
/**
* 获取下一个数据的键值对
*/
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
/**
* 获取当前数据的 key
*/
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
/**
* 获取当前数据的value
*/
public abstract
VALUEIN getCurrentValue() throws IOException, InterruptedException;
/**
* 进度
*/
public abstract float getProgress() throws IOException, InterruptedException;
/**
* 关闭RecordReader
*/
public abstract void close() throws IOException;
}
组合使用InputFormat和RecordReader可以将任何类型的输入数据转换为MapReduce所需的键值对。
下面有一篇文章可以参考:
https://www.cnblogs.com/xuepei/p/3664698.html
InputFormat:
通过使用InputFormat,MapReduce框架可以做到:
-
1、验证作业的输入的正确性
-
2、将输入文件切分成逻辑的InputSplits,一个InputSplit将被分配给一个单独的Mapper task
-
3、提供RecordReader的实现,这个RecordReader会从InputSplit中正确读出一条一条的K-V对供Mapper使用。
maptask会将返回的 key - value 交给自定义的Mapper。如果没有自定义的Mapper就是使用默认的Mapper。这个默认的Mapper的map处理方法,就是进来什么就输出什么。

map方法的参数有 key - value ,所以maptask会将InputFormat返回的key - value交给Mapper的map方法去使用。

内部还有一个组件 OutputCollector:
OutputCollector 由hadoop框架提供,复制收集Mapper和Reducer的输出数据,实现map或者reduce函数时,只需要简单地将其输出的
这个收集器会将数据输出到一个环形缓冲区,其实就是一个数组,(一边写数据,一边会对数据进行回收,通过索引来控制,相当于一个环一样)
环形缓冲区其实就是一个数组,后端不断接收数据的同时,前端数据不断溢出,长度用完之后读取的新数据再从前端开始覆盖。这个缓冲区的默认大小是100M – 这个环形缓冲区是内存里面的,速度很快,但是容量有限。-- 这个100M是不会全部被使用的,因为还需要内存进行排序等操作。 这里面有一个保留区
操作80%就会溢出
spiller组件会从环形缓冲区溢出文件,这过程会按照定义的partitioner分区(默认是hashpartition),并且按照key.compareTo()进行排序(底层主要是快排和外部排序)
spiller会在环形缓冲区溢出的时候,对数据进行分区和排序, – (spiller会会环形缓冲区这段内存进行操作)
分区是根据key,这个分区需要调用一个组件 Partitioner - 默认的实现是 HashPartitioner.
排序的时候需要调用被排序对象的compareTo()方法。
这个过程就是将数据分好区,每个区都是排好序的。
分区排序之后,就可以将文件往外写。一个区一个区往外写。 内存中的数据写到文件中。这个文件就在maptask的工作目录里面。就在本地。
每一次溢出就会产生一个文件。

如果内存里面还剩下最后的一点点数据,那也需要溢出。
这些溢出的文件不会一个一个地交给reduce去处理,还会先进行一次合并。合并完之后会形成一个大文件。这个merge使用的是归并排序。

merge之后就会将数据全部交给reduce来进行处理:

reduce task会去下载数据(通过网络从传输)

reduce task 从 map task 机器上下载下来的数据是没有排序的,还需要进行再一次地合并。

问题: reduce task 拿到这个文件是怎么处理的?
reducer 的 reduce方法是处理业务逻辑的,会根据key来处理,相同的key就调用一次reduce() 方法。调用 GroupingComparator()方法


完整的图:

Combainer
Hadoop矿建使用Mapper将数据处理成一个个
这时会出现性能上的瓶颈:
(1)如果我们有10亿个数据,Mapper会产生10亿个键值对在网络间进行传输,但是如果我们对数据求最大值,那么很明显的Mapper值需要输出它所知道的最大值即可。这样不仅可以减少轻网络压力,同样也可以大幅度提高程序效率。
总结:网络带宽严重被占降低效率。
(2)有时候数据远远不是一致性的或者说是平衡分布的,这样不仅Mapper中的键值对,中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于单一的Reducer上,压倒这个Reducer,从而大大降低程序的性能。
总结:单一节点承载过重降低程序性能。
在MapperReducer编程模型中,在Mapper和Reducer之间有一个非常重要的组件,它解决了上述的性能瓶颈问题,它就是Combiner.
注意点:
(1)与mapper和reducer不同的是,combiner没有默认的实现,需要显式设置早conf中才有作用,
(2)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:
opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。
每一个mapper都可能产生大量的本地输出,Combiner额作用就是对map端的输出先做一次合并,减少在map和reduce节点之间的数据传输,以提高网络IO性能,是MapReduce的一种优化手段之一,其具体作用如下所述:
自定义的Combiner其实就是跟Reducer一样的代码:
package com.thp.bigdata.wcdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 自定义的Combiner
* @author tommy
*
*/
public class MyCombiner extends Reducer{
@Override
protected void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
//
System.out.println("Combiner输入分组<" + key.toString() + ",N(N>=1)>");
int count = 0;
for(IntWritable value : values) {
count += value.get(); // 这个count 最后就是某一个单词的汇总的值
// 显示次数表示输入的k2,v2的键值对数量
System.out.println("Combiner输入键值对<" + key.toString() + "," + value.get() + ">");
}
context.write(key, new IntWritable(count));
System.out.println("Combiner输出键值对<" + key.toString() + "," + count+ ">");
}
}
还需要将这个自定义的Combiner添加进去:
// 设置Map规约Combiner
job.setCombinerClass(MyCombiner.class);
我每一个文件中就有8个hello,这个8个hello如果使用了combiner会先进行一次合并:
没使用之前:
Reducer输入分组=1)>
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
Reducer输入键值对
reduce会有56次输入,但是如果使用了combiner的话,每一次map之后,就会进行换一次合并:

接下来会有一个combiner进行一次合并:

第一个文件中的8个hello就进行了一次合并:
每一个文件都会有这个combiner的过程,最后会有reduce的过程进行汇总:

这个reduce过程对hello进行统计只有7次输入,每一次输入的数据都是8次,是combiner先进行了一次合并。
总结:
从控制台的信息我们可以发现,其实combiner只是把相同的hello进行规约,由此输入给reduce的就变成
但是:特别值得注意的一点是,一个combiner只是处理一个节点中的输出,而不能享受向reduce一样的输入(经过了shuffle阶段的数据),这点非常关键
combiner:
前面展示的流水线忽略了一个可以优化MapReduce作业所使用的带宽的步骤,这个过程叫Combiner,它在Mapper之后,Reducer之前运行。combienr是可选的,如果这个过程适合于你的作业,Combiner实例会在每一个运行map任务的节点上运行。Combiner会接收特定节点上的Mapper实例的输出作为输入,接着Combiner的输出会被送到Reducer那里,而不是发送Mapper的输出。Combiner是一个“迷你reduce过程”,他只处理单台机器生成的数据。
参考别的大神的博客:
https://blog.csdn.net/guoery/article/details/8529004