【论文学习】Fooling Detection Alone is Not Enough--Adversarial Attack against Multiple Object Tracking论文学习
文章目录
- 写在前面
- 概念介绍
- AML
- tracking-by-detection
- 论文的总体介绍
- 前人所做过的研究
- 论文的工作
- 实现方法(Methodology)
- 实现算法的关键点
- 代码实践
- 代码解读
写在前面
最近参与导师的一个项目,是对百度无人驾驶项目Apollo进行攻击。目前在看感知模块的camera部分实现,同时也在看相关的对于图像,视觉,检测,追踪的攻击手段,看了一些论文和博客,分享一下
Fooling Detection Alone is Not Enough–Adversarial Attack against Multiple Object Tracking这篇论文的学习心得,这篇论文是我找到的对于图像的目标检测,追踪攻击的较好的一篇论文。
概念介绍
因为我之前对于网络安全不是特别了解,对于目标检测,目标追踪的攻击手段也不了解,所以在看论文的时候遇到了一些陌生的概念。这里记录一下,方便后面查阅。
AML
AML的全称是adversarial machine learning,中文翻译过来就是对抗机器学习。这是安全领域的一个概念,就是对于机器学习模型进行攻击。主要分为训练阶段的攻击和推理阶段的攻击。训练阶段的攻击又分为标签操纵(label manipulation)和输入操纵(input manipulation)。标签操纵是对于训练数据的标签进行替换,输入操纵是构造尽量少且恶意程度尽量高的恶意样本来污染训练数据(恶意的攻击物理世界中的数据,例如交通信号灯,或者是自动驾驶摄像头正在拍摄的图像等)。推理阶段的攻击包括白盒攻击和黑盒攻击。白盒攻击是基于我们已经知道了模型中的所有参数,通过加入尽量小的扰动(这里就用r来表示这个 扰动)来干扰预测结果,获得我们想要的不正确的预测结果。白盒攻击的一大难点是干扰r的确定,FGSM就是一个常用的确定干扰的方法。黑盒攻击当然就是基于我们对于模型的参数一无所知,这个时候就需要猜测内部结构(影子模型攻击),或者加入大一些的扰动进行攻击。
tracking-by-detection
目标视觉跟踪(Visual Object Tracking),大家比较公认分为两大类:生成(generative)模型方法和判别(discriminative)模型方法,目前比较流行的是判别类方法,也叫检测跟踪(tracking-by-detection)。tracking-by-detection的经典套路就是图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,机器学习训练分类器,下一帧用训练好的分类器找最优区域。与生成类方法最大的区别,是分类器训练过程中用到了背景信息,这样分类器专注区分前景和背景,判别类方法普遍都比生成类好。Apollo源码中用的也是这种tracking-by-detection。
论文的总体介绍
现在很多对抗机器学习(AML)的工作都逐渐在更多的关注对于自动驾驶的视觉感知部分的攻击,研究使用对抗样本(Adversarial Example)来对目标检测模型进行攻击。但是要知道,在视觉感知部分,在检测物体之后也需要对物体进行追踪。这个追踪的过程也叫做Multiple Object Tracking(MOT),目的是获得周围物体的运动轨迹(moving trajectory)。MOT在设计的时候,就不得不需要考虑它的健壮性,因为目标检测部分会出现一些错误,我们必须考虑到前面可能出现的错误,因此它就给现在的一些盲目把攻击重心放在目标检测的攻击手段带来了很多挑战:如果只考虑对目标检测模型的攻击,需要达到98%的攻击成功率才能影响真正影响最后的追踪结果,而问题是目前是没有一个攻击技术是可以满足这个要求的。这篇论文所做的工作是第一个采用AML,对于自动驾驶的完整视觉感知模块进行攻击(之前大部分研究是只针对于目标检测部分)。通过 追踪器劫持(tracker hijack) 来有效的欺骗Multiple Object Tracking(MOT)。这篇论文的研究结果在 Berkeley Deep Drive这个数据集上进行了evaluation,发现平均只要对3个帧进行了攻击,就可以达到100%的成功率。而在相同的前提下(也对3个帧进行攻击),盲目的只针对目标检测进行攻击只能达到25%的 成功率。
论文中所做工作的源码已经开源在github上,网址为https://github.com/anonymousjack/hijacking
前人所做过的研究
自从2018年有人提出采用AE(对抗样本)对交通信号灯的分类模型进行攻击,就有越来越多的人开始关注对于自动驾驶的视觉感知模块的攻击,研究通过使用AE(对抗样本)对目标检测模型进行攻击。之前有研究者采用AE对停止标志和前车的后尾灯检测模型YOLO模型进行攻击。也有研究者基于上面的研究,对于图像进行进一步的变换来提高对模型的攻击的健壮性,并且对于一辆实际道路中车速为30km/h的车辆进行实验,可以达到72%的成功率。但是要知道目标检测只是感知模块的前半部分,后面还有追踪模块,也就是MOT也是很重要的。MOT的一个重要用途就是预测周围车辆未来的运动轨迹,从来为自己的车辆规划之后的路径来避免与周围车辆的碰撞。为了在保证追踪的准确的同时考虑到前面目标检测模块可能出现的检测错误,被检测的物体只有在多个帧中始终保持了轨迹的足够的一致性和稳定性,才能将其作为追踪结果,影响后面本车辆的决策。如果仅仅对于目标检测模型进行攻击,必须要在连续的60帧中都成功将检测进行误判,才能欺骗的了追踪过程,而要实现这个就必须要达到98%的攻击成功率。但是目前是没有一个攻击可以达到如此高的成功率。
论文的工作
作者从Berkeley Deep Drive数据集的100个短片中选择了20个,来对自己的研究进行evaluation,最后发现只要AE在2-3个连续帧上都欺骗成功,实现误判,最终的对于车辆的攻击就可以成功完成。而前人的研究(只基于目标检测模型进行攻击),在相同前提下(AE在2-3个连续帧上都欺骗成功),只能达到25%的成功率。
在对MOT过程的攻击中,作者采用了一个攻击技术,那就是追踪器劫持(tracker hijack)。这个技术不断的影响MOT的追踪错误率的降低过程( tracking error reduction process),这里我的理解大概就是跟我们平时训练一般的机器学习模型的时候,训练目的是loss的不断减小,accuracy rate准确率的不断增加一样。最终保证了AE在单个帧或者相邻2-3个帧的被误判,从而导致潜在的车辆行驶危险。
这篇论文的工作是基于一种假设,那就是单纯的只对于目标检测进行攻击是不能达到对整个视觉感知过程进行攻击的目的的(以往都是单纯对目标检测进行攻击)。
MOT过程主要是要确定物体以及物体的轨迹。目前tracking-by-detection是一个主流的MOT典范。在tracking-by-detection中,检测(Detection)部分是为了确定图像中的物体,而追踪(Track)部分是将物体和轨道进行联系。
追踪部分的整体过程如下:
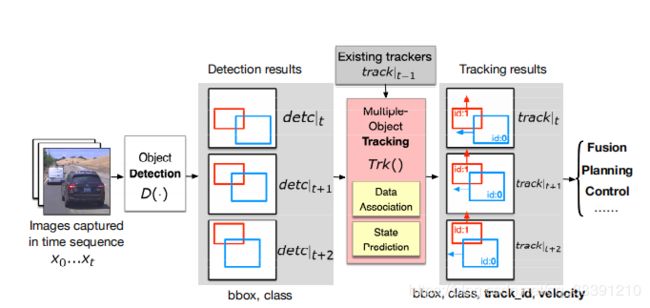 每个物体在时刻t都有一个轨迹,图中用track|t-1表示,采用卡尔曼滤波(Kalman filter)实现预测-更新的不断迭代,更新(update)步骤是将检测结果 d e t c ∣ t detc|_t detc∣t作为一个measurement来更新估计(estimation)结果。卡尔曼滤波使用了速度模型来估计下一帧中的物体位置,以此来补偿不同帧之间物体的运动。但是,这种error reduction process使得追踪器劫持成为可能。
每个物体在时刻t都有一个轨迹,图中用track|t-1表示,采用卡尔曼滤波(Kalman filter)实现预测-更新的不断迭代,更新(update)步骤是将检测结果 d e t c ∣ t detc|_t detc∣t作为一个measurement来更新估计(estimation)结果。卡尔曼滤波使用了速度模型来估计下一帧中的物体位置,以此来补偿不同帧之间物体的运动。但是,这种error reduction process使得追踪器劫持成为可能。
一般是在物体连续出现在特定数目图像帧中,这个时候才会创建一个追踪器,这个特定数目也被称为hit count,论文中用H表示;如果一个物体连续好几帧都没有出现,就会删除这个追踪器,这个特定数目被称为 reserved age,论文中用R表示。MOT可以选择一些measurement来对不同帧的物体进行匹配,这些measurement包括bounding box的重叠,视觉表示等。这篇论文选用基于IOU的匈牙利匹配(IoU-based Hungarian matching)作为measurement的算法。百度的Apollo采用的也是这种方法。
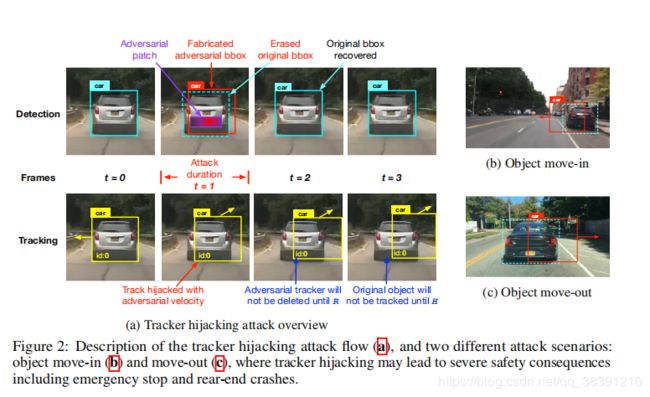 追踪器劫持的过程如图所示。可以看到本来t0时刻目标车辆预测之后的速度方向是向左的,但是在t1时刻,将一个对抗补丁( adversarial patch)贴在车辆的后面(也就是图上的红色区域,其实是贴了一个对抗补丁)。这个对抗补丁有两个效果:(1)清除了上面的检测阶段生成的目标物体身上的边界框(bounding box)。(2)在清除正确的bounding box(图上的蓝色虚线框框)后,伪造了一个跟真实bounding box相似size的bounding box(也就是图上的红色框框)。这个伪造的bounding box之后就会跟追踪器进行关联,也就是论文采用的攻击方法:追踪器劫持(tracker hijack)。此时我们看到t2时间之后,速度就完全偏离真实情况了。虽然攻击只持续了一帧,但是却可以影响之后的很多帧,因为追踪器的创建和删除是有一定要求的(前面说过,有H和R这两个参数的限制)。这部分借用原论文,大家可以更好的理解(因为我自己也理解了好久,需要多读几遍体会一下)原论文中是这么描述的:the tracker that has been hijacked with attacker-induced velocity will not be deleted until a reserved age ® has passed, and (2) the target object, though is recovered in the detection result, will not be tracked until a hit count (H) has reached, and before that the object
追踪器劫持的过程如图所示。可以看到本来t0时刻目标车辆预测之后的速度方向是向左的,但是在t1时刻,将一个对抗补丁( adversarial patch)贴在车辆的后面(也就是图上的红色区域,其实是贴了一个对抗补丁)。这个对抗补丁有两个效果:(1)清除了上面的检测阶段生成的目标物体身上的边界框(bounding box)。(2)在清除正确的bounding box(图上的蓝色虚线框框)后,伪造了一个跟真实bounding box相似size的bounding box(也就是图上的红色框框)。这个伪造的bounding box之后就会跟追踪器进行关联,也就是论文采用的攻击方法:追踪器劫持(tracker hijack)。此时我们看到t2时间之后,速度就完全偏离真实情况了。虽然攻击只持续了一帧,但是却可以影响之后的很多帧,因为追踪器的创建和删除是有一定要求的(前面说过,有H和R这两个参数的限制)。这部分借用原论文,大家可以更好的理解(因为我自己也理解了好久,需要多读几遍体会一下)原论文中是这么描述的:the tracker that has been hijacked with attacker-induced velocity will not be deleted until a reserved age ® has passed, and (2) the target object, though is recovered in the detection result, will not be tracked until a hit count (H) has reached, and before that the object
remains missing in the tracking result.作者考虑到在实际应用中一个帧的攻击可能不会完全导致追踪器的被劫持,因此实验了很多,发现一旦连续3个帧被攻击偏离原bounding box,就可以达到100%的成功率。
实现方法(Methodology)
实现方法就如下所示:
(1)输入
视频图像序列X= [ x 0 x_0 x0, x 1 x_1 x1, …, x n x_n xn],目标检测器(object detector)D(·),MOT算法Trk(·)。
计划攻击的物体(object)编号K,预期的劫持后的速度 v → \overrightarrow{v} v,对抗补丁区域patch(这是个Mask Matrix)
(2)输出
攻击后的得到的图像序列 X ′ X' X′= [ x 1 ′ x'_1 x1′, …, x r ′ x'_r xr′]
(3)实现步骤
X’← {}, d e t c ∣ 0 detc|_0 detc∣0 ← D( x 0 x_0 x0), t r a c k ∣ 0 track|_0 track∣0 ← {current_tracks} (这里第一步是初始化步骤)
for t = 1 to n do
d e t c ∣ t detc|_t detc∣t ← D( x t x_t xt)
if d e t c ∣ t detc|_t detc∣t[K]== t r a c k ∣ t − 1 track|_{t-1} track∣t−1[K]
then 将目标物体K和已经创建好的追踪器进行联系,并且通过下面的公式1找到放置伪造的bbox的位置
pos ← FINDPOS(Trk(·), t r a c k ∣ t − 1 track|_{t-1} track∣t−1, K, v → \overrightarrow{v} v , patch)
通过以下公式2生成攻击后的帧x’
x t ′ x'_t xt′ ← GENERATEADV(x, D(·), pos, K, patch)
X’ → + \xrightarrow{+} + x t ′ x'_t xt′
else
return X’ (此时已经攻击成功,目标物体K此时已经没有和原来的追踪器联系到一起了,追踪器已经成功被劫持,所以可以返回生成值,提前结束循环了)
end if
t r a c k ∣ t track|_t track∣t ← Trk( t r a c k ∣ t − 1 track|_{t-1} track∣t−1, D( x t ′ x'_t xt′)) (这里是用得到的帧 x t ′ x'_t xt′更新追踪器,这个帧此时很可能已经被修改)
end for
实现算法的关键点
上面介绍了论文的实现基本步骤,实现 中最关键的两个点如下:
(1)找到某一帧中放置自己伪造的bounding box的最优位置(也就是上面的pos),这里就是上面的公式1这个步骤。因为追踪器劫持的目的就是去掉原本正确的检测到的bounding box,换成我们自己伪造的bounding box,所以这一步骤尤其关键。这部分很重要的点就是要得到干扰值σ,要让原来正确的追踪器和伪造的box之间的匈牙利匹配值达到最大,从而可以成功攻击,得到我们预期想要的速度 v → \overrightarrow{v} v。 (我理解的这里是不是就是和AML的推理阶段的白盒攻击差不多,得到一个干扰值才能进行攻击)
(2)生成一个可以成功完成追踪器劫持攻击的对抗补丁(也就是上面的公式2这个步骤),要伪造好一个bounding box,放在上面已经得到的pos位置上,然后劫持追踪器。
代码实践
跑到Github上将源码下载了下来,实践了一番。这篇论文的源码不复杂,大概就是包括检测部分(使用yolo),追踪部分(使用卡尔曼滤波和匈牙利匹配等),攻击部分(算法流程如上)。采用的是python语言。
输入部分也不是很多,一共也就20个mp4文件(10个move-in类型的,10个move-out类型的)。输出部分是每一个mp4文件输入对应的被攻击的帧以及各个攻击帧的伪造的补丁bounding box的位置。
记录一下一个move-in文件对应的输出:
 一个move-out文件对应的输出:
一个move-out文件对应的输出:

代码解读
后面补充。。。