Hadoop全面讲解(二)Hadoop+ZooKeeper高可用
一.ZooKeeper概念讲解
(一)概念
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
- ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
- ZooKeeper包含一个简单的原语集,提供Java和C的接口。
- ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3.4.3\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
(二)原理
- ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。
- ZooKeeper的基本运转流程:
1、选举Leader。
2、同步数据。
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4、Leader要具有最高的执行ID,类似root权限。
5、集群中大多数的机器得到响应并接受选出的Leader。
(三)特点
-
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据。如果在创建znode时Flag设置为EPHEMERAL,那么当创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper里,Zookeeper使用Watcher察觉事件信息。当客户端接收到事件信息,比如连接超时、节点数据改变、子节点改变,可以调用相应的行为来处理数据。Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交。
-
那么Zookeeper能做什么事情呢,简单的例子:假设我们有20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的cgi(向总服务器发出搜索请求)。搜索引擎的服务器中的15个服务器提供搜索服务,5个服务器正在生成索引。这20个搜索引擎的服务器经常要让正在提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以提供搜索服务了。使用Zookeeper可以保证总服务器自动感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,当总服务器宕机时自动启用备用的总服务器。
-
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
-
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
-
重点概念:
1.server2和server3第一次切换用户会比较慢
2.hadoop比较吃内存,如果内存如果比较小,会出现进程起来了,但是一会就消失了,或者使用jps是无法查看到的
3.ps是查看整个操作系统的
4.给集群添加一个数据节点
5.做hadoop集群时一定需要主机名解析,时间同步,用户id
6.su - 中的“-”代表用户的环境变量
7.在开启服务时,不建议使用此命令(例如sbin/hadoop-daemon.sh start datanode),因为会出现warning
8.整个分布式文件系统中各个节点的的状态
9.2版本是50070,3版本是9870,可以通过在配置文件中修改
10.哪些节点在一个机架内,如果使用便宜的,地震可能会漂移
11.client可能是外部直接存储的数据,也可能是其中的一个节点(做client,也做数据存储)
12.可以直接上传到hdfs,通过myeclise的端口传
13.CDH版本:可以直接支持图形化部署,都遵守apache版本
14.HPC:网关计算,不是超算,硬件比较牛逼,比较少
15.hadoop对硬件没有太大的要求
16.第一个副本是随机的,第二个是机架感应技术(一定是在一个机架上的节点),(同一个机架上的另外一个节点)
17.假如file1100M,每个block是128M,是按照block写进入的,数据流,
18.节点越多,冗余性越好,可是比较耗内存
19.迁移数据快还是计算快,计算
20.会按照顺序读取地址链表
21.spark是内存式的,storm,flink都需要YARN管理器(做调度)
22.一般的服务都要首先将其停掉,再开启
23.管理器,下面都会有分布式管理框架,但是都会有mapreduce(类似图书管理系统)
24.硬件运行的状态都会使用日志显示
25.spark主要做内存
26.rm做资源分配
27.nm是控制本质物理界点的container,是am和rm的传输,即am向nm申请,并将状态实时告诉rm
28.am是用户层面的
二.Hadoop+ZooKeeper高可用
~~~~~~~~~~~~~
实验环境:
server1 172.25.66.1
server2 172.25.66.2
server3 172.25.66.3
server4 172.25.66.4
server5 172.25.66.5
物理机 172.25.254.66
~~~~~~~~~~~~~~~
(一)前提工作(开启服务并重新创建一个虚拟机)
1.在server1首先切换到hadoop用户下并查看之前是否成功配置hadoop
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls

2.在server1进入hadoop目录下开启dfs服务,发现会报错(报错内容为:172.25.66.3/2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password)
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh

3.在server1退出hadoop用户登陆后开启nfs服务
[hadoop@server1 hadoop]$ logout
[root@server1 ~]# systemctl start nfs
![]()
4.在server2和server3中将server1中的/home/hadoop目录挂载至本地的/home/hadoop目录下并查看
在server2中操作:
[root@server2 ~]# mount 172.25.66.1:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
在server3中操作:
[root@server3 ~]# mount 172.25.66.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# df
5.在server1中切换到hadoop用户下并重新开启服务,发现还是报错(报错内容如下:172.25.66.3: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).),这是因为之前开启过dfs服务,但是没有成功开启,此时应该先关闭dfs服务,再重细腻开启
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
6.在server1中关闭dfs服务并重新开启,发现没有报错
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
注意:
1.可以使用ps ax和jps查看dfs服务是否成功开启
2.如果使用jps查看时有时出现两个有时出现一个,其原因是因为内存太小,所以需要加内存,具体做法如下:
#查看jps
[hadoop@server1 hadoop]$ jps
[hadoop@server1 hadoop]$ jps
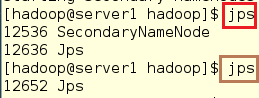
#可以查看到内存的大小是1024MB
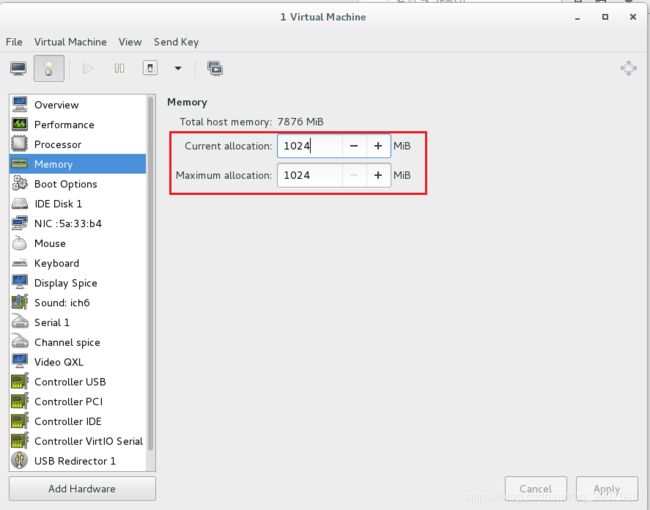
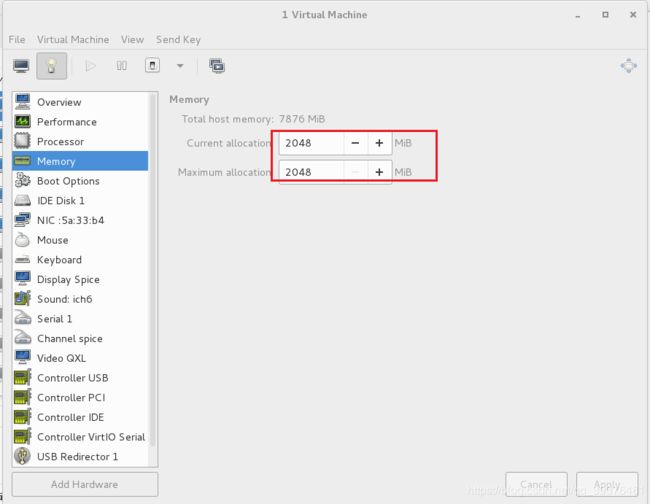
#将快照关机后,将其内存由1024MB更改成2048MB
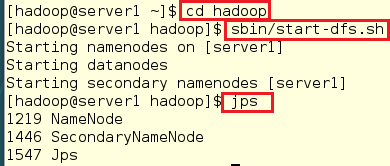
#重新开启dfs服务,在此之前需要将其关闭
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
[hadoop@server1 hadoop]$ jps
7.重新创建一个虚拟机并对新的虚拟机做初始配置并开启服务
#首先安装nfs
[root@server4 ~]# yum install nfs-utils -y
[root@server4 ~]# systemctl start rpcbind
[root@server4 ~]# systemctl enable rpcbind
[root@server4 ~]# showmount -e 172.25.66.1
[root@server4 ~]# useradd hadoop
[root@server4 ~]# id hadoop
[root@server4 ~]# mount 172.25.66.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# su - hadoop
[hadoop@server4 ~]$ cd hadoop
[hadoop@server4 hadoop]$ cd etc/hadoop/
[hadoop@server4 hadoop]$ vim workers
[hadoop@server4 hadoop]$ cat workers
[hadoop@server4 hadoop]$ cd ../..
#开启hadoop服务
[hadoop@server4 hadoop]$ sbin/hadoop-daemon.sh start datanode

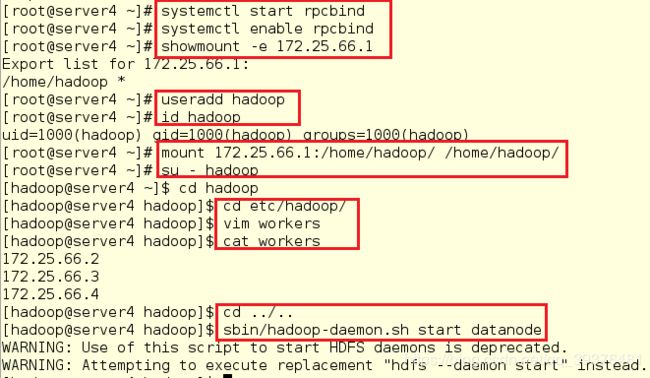
注意:
(1)在成功共享后,千万不要再轻易删除hadoop用户,否则可能会导致快照崩溃,实验无法继续,我删了几次用户后,再次切换到hadoop目录下,发现已经显示的是bash命令行,重新配置后,解压jdk安装包又出现问题,所以,在删除东西的时候,一定要注意
(2)在开启服务时会发现会有报错,但是此报错并不影响,其原因是因为版本已经更新,希望用新的命令替代旧的命令
8.在server1中查看节点
[hadoop@server1 hadoop]$ bin/hdfs dfsadmin -report
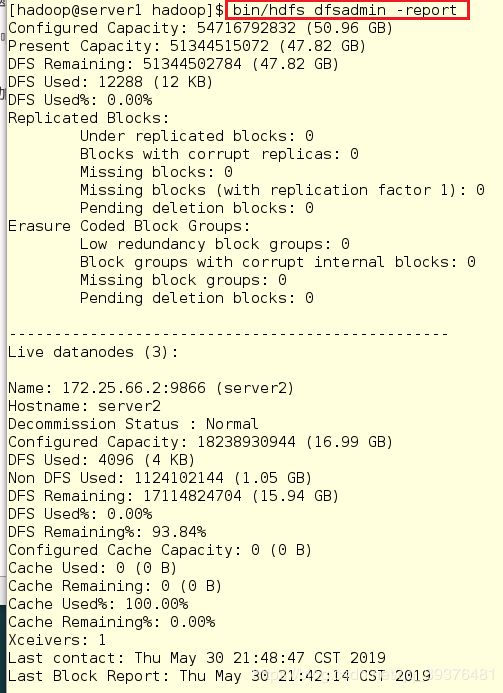
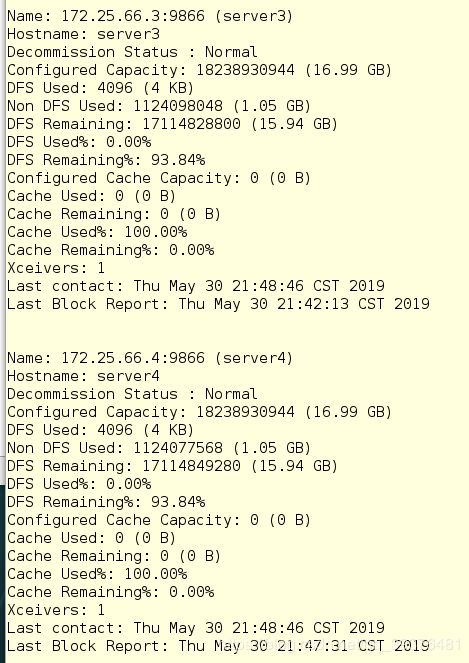
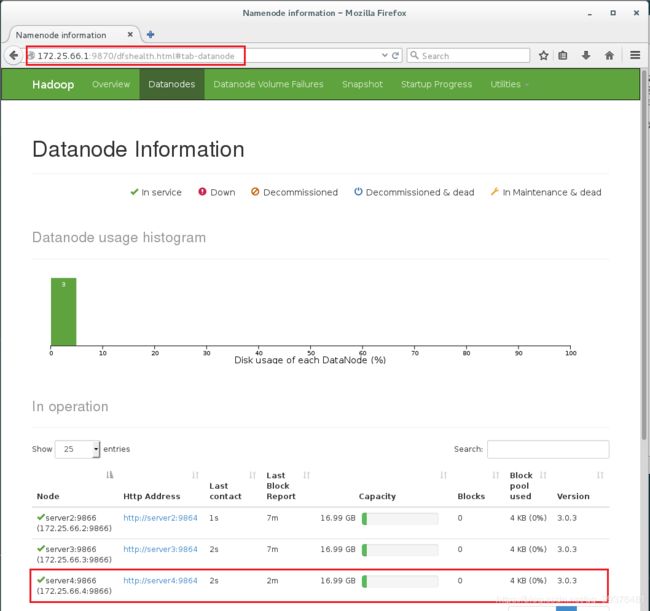
9.在浏览器中输入网址可以发现到3个节点都已经成功添加
(二)配置zookeeper高可用
1.在server1和server4中关闭之前的服务,并清理环境
在server1中的操作:
[hadoop@server1 hadoop]$ sbin/stop-yarn.sh
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
[hadoop@server1 hadoop]$ jps
[hadoop@server1 hadoop]$ cd /tmp
[hadoop@server1 tmp]$ ls
[hadoop@server1 tmp]$ rm -rf *
[hadoop@server1 tmp]$ ls
在server4中的操作:
[hadoop@server4 ~]$ cd hadoop
[hadoop@server4 hadoop]$ sbin/stop-yarn.sh
[hadoop@server4 hadoop]$ sbin/stop-dfs.sh
[hadoop@server4 hadoop]$ jps
[hadoop@server4 hadoop]$ cd /tmp
[hadoop@server4 tmp]$ ls
[hadoop@server4 tmp]$ rm -rf *
[hadoop@server4 tmp]$ ls
2.在server2和server3将数据删除
在server2中的操作:
[hadoop@server2 ~]$ cd /tmp
[hadoop@server2 tmp]$ ls
[hadoop@server2 tmp]$ rm -rf *
[hadoop@server2 tmp]$ ls
在server3中的操作
[hadoop@server3 ~]$ cd /tmp
[hadoop@server3 tmp]$ ls
[hadoop@server3 tmp]$ rm -rf *
[hadoop@server3 tmp]$ ls
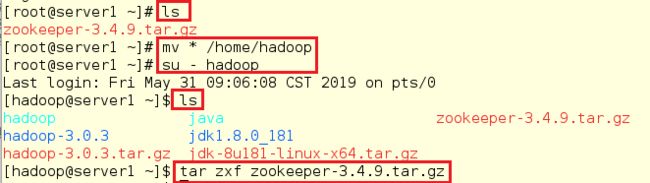
3.在server1中解压zoopker安装包(因为是共享的,所以在server1中解压即可)
[root@server1 ~]# ls
[root@server1 ~]# mv * /home/hadoop
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
[hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz
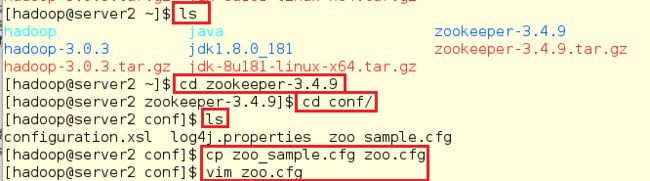
4.以server2为节点搭建zookeeper(任意一个做节点都可以)
[hadoop@server2 ~]$ ls
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ cd conf/
[hadoop@server2 conf]$ ls
[hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@server2 conf]$ vim zoo.cfg
在zoo.cfg中添加的内容如下(添加从节点信息):
#2888是follow和领导者之间的通讯接口,3888做选举
29 server.1=172.25.66.2:2888:3888
30 server.2=172.25.66.3:2888:3888
31 server.3=172.25.66.4:2888:3888

5.在server2,server3,server4中创建/tmp/zookeeper目录,并新建一个myid文件写入数字,注意,这里的数字要和之前在配置文件中的定义一样
在server2中的操作:
[hadoop@server2 conf]$ mkdir /tmp/zookeeper
[hadoop@server2 conf]$ echo 1 > /tmp/zookeeper/myid
![]()
在server3中的操作:
[hadoop@server3 tmp]$ mkdir /tmp/zookeeper
[hadoop@server3 tmp]$ echo 2 > /tmp/zookeeper/myid
![]()
在server4中的操作:
[hadoop@server4 tmp]$ mkdir /tmp/zookeeper
[hadoop@server4 tmp]$ echo 3 > /tmp/zookeeper/myid
![]()
注意:
各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入
一个唯一的数字,取值范围在 1-255。比如:172.25.0.2 节点的 myid 文件写入数字“1”,此数字与配置文件中的定义保持一致,(server.1=172.25.0.2:2888:3888)其它节点依次类推。
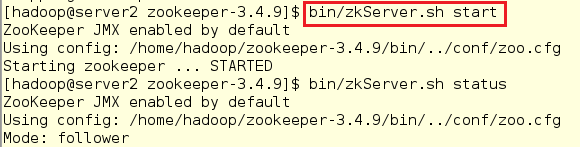
6.在各节点启动服务并查看各节点状态(如果节点没有起来,需要将其关闭后再重新启动,否则会出现报错)
在server2中,发现节点是从节点:
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh status
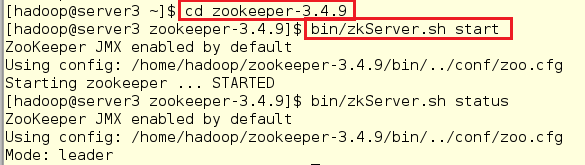
在server3中,发现节点是主节点:
[hadoop@server3 ~]$ cd zookeeper-3.4.9
[hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh status
在server4中,发现节点是从节点:
[hadoop@server4 ~]$ cd zookeeper-3.4.9
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh status
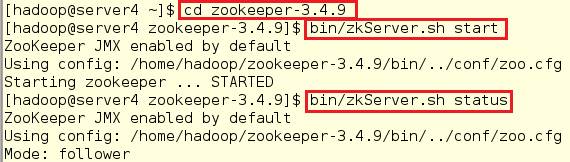
注意:
一定要在zookeeper-3.4.9目录下执行此命令
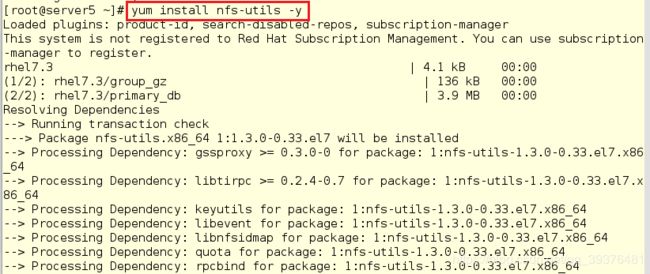
7.在server5中安装nfs-utils安装包并创建hadoop用户,然后进行挂载
[root@server5 ~]# yum install nfs-utils -y
[root@server5 ~]# useradd hadoop
[root@server5 ~]# id hadoop
[root@server5 ~]# mount 172.25.66.1:/home/hadoop/ /home/hadoop
[root@server5 ~]# df
注意:
此时在server1中连接server5时会发现,不需要输入密码,只需要输入yes,在之后,连yes也不需要输入,说明共享时,免密也共享了
8.更改core-site.xml和hdfs-site.xml
[hadoop@server1 hadoop]$ vim core-site.xml
[hadoop@server1 hadoop]$ vim hdfs-site.xml
![]()
文件core-site.xml更改的内容如下:
18
19
20 fs.defaultFS
21 hdfs://masters
22
23
24
25 ha.zookeeper.quorum
26 172.25.66.2:2181,172.25.66.3:2181,172.25.66.4:2181
27
28
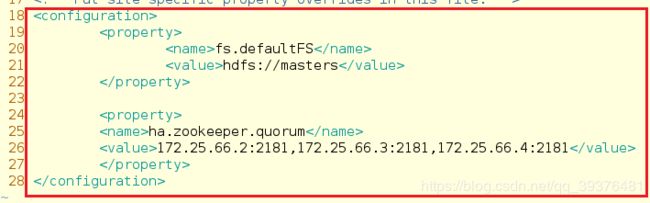
文件hdfs-site.xml更改的内容如下:
dfs.nameservices
masters
dfs.namenode.rpc-address.masters.h1
172.25.66.1:9000
dfs.namenode.http-address.masters.h1
172.25.66.1:9870
dfs.namenode.rpc-address.masters.h2
172.25.66.5:9000
dfs.namenode.http-address.masters.h2
172.25.66.5:9870
dfs.namenode.shared.edits.dir
qjournal://172.25.66.2:8485;172.25.66.3:8485;172.25.66.4:8485/masters
dfs.journalnode.edits.dir
/tmp/journaldata
!-- 开启 NameNode 失败自动切换 -->
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.masters
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000

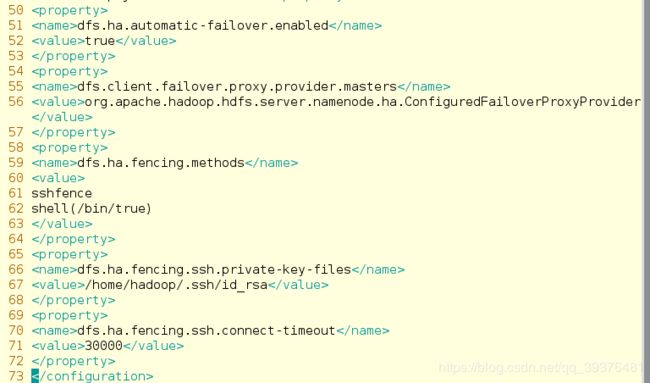
注意:
在配置文件中不要写汉字,否则可能出现报错
9.启动 hdfs 集群(按顺序启动)
在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 ~]$ cd hadoop
[hadoop@server2 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server2 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server2 hadoop]$ jps
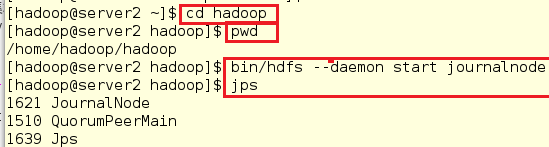
注意:
因为之前在三个 DN 上依次启动 zookeeper 集群,所以这里不需要再次启动
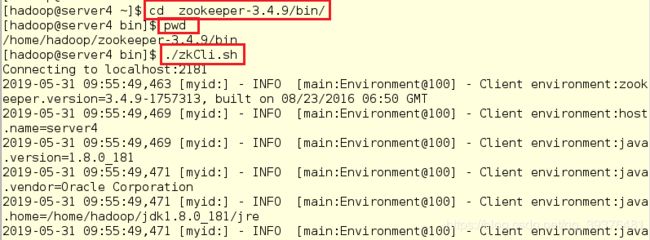
10.在server4中查看master在哪个节点上(因为还没有设置,所以不显示)
[hadoop@server4 ~]$ cd zookeeper-3.4.9/bin/
[hadoop@server4 bin]$ pwd
#连接zookeeper
[hadoop@server4 bin]$ ./zkCli.sh
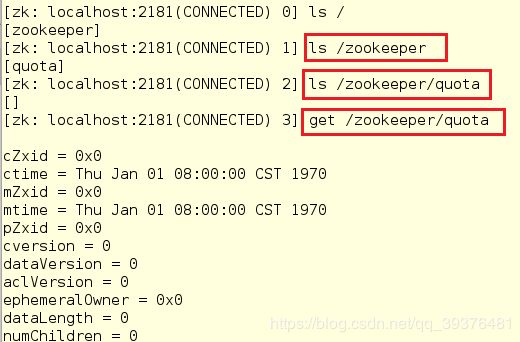
[zk: localhost:2181(CONNECTED) 0] ls /
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[zk: localhost:2181(CONNECTED) 2] ls /zookeeper/quota
[zk: localhost:2181(CONNECTED) 3] get /zookeeper/quota
11.格式化 HDFS 集群(只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ pwd
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
12.Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
[hadoop@server1 hadoop]$ cd /tmp
[hadoop@server1 tmp]$ ls
[hadoop@server1 tmp]$ scp -r hadoop-hadoop/ server5:/tmp
13.格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
14.启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ pwd
[hadoop@server1 hadoop]$ sbin/start-dfs.sh

15.查看各节点的状态
在server1中查看:
[hadoop@server1 hadoop]$ jps

在server5中查看:
[hadoop@server5 tmp]$ jps
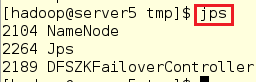
在server2中查看:
[hadoop@server2 hadoop]$ jps
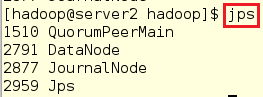
在server3中查看:
[hadoop@server3 hadoop]$ jps
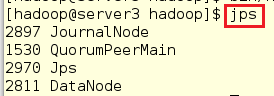
在server4中查看:
[hadoop@server4 ~]$ jps
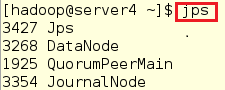
注意:
如果某个节点中的java进程少,关闭服务后,重新开启服务即可,不论是重新开启服务还是重新格式化,都需要将服务先关闭
(三)测试故障自动切换
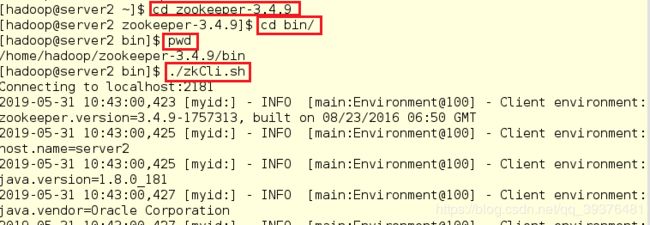
1.在server2中使用命令查看master在哪个节点上,此时发现在server1中
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ cd bin/
[hadoop@server2 bin]$ pwd
[hadoop@server2 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /hadoop-ha
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha/masters/ActiveBreadCrumb
[zk: localhost:2181(CONNECTED) 2] get /hadoop-ha/masters/ActiveBreadCrumb
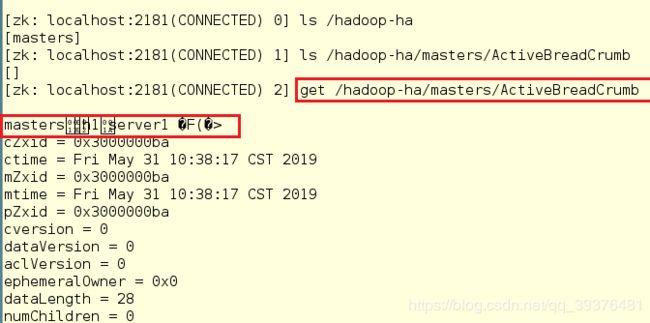
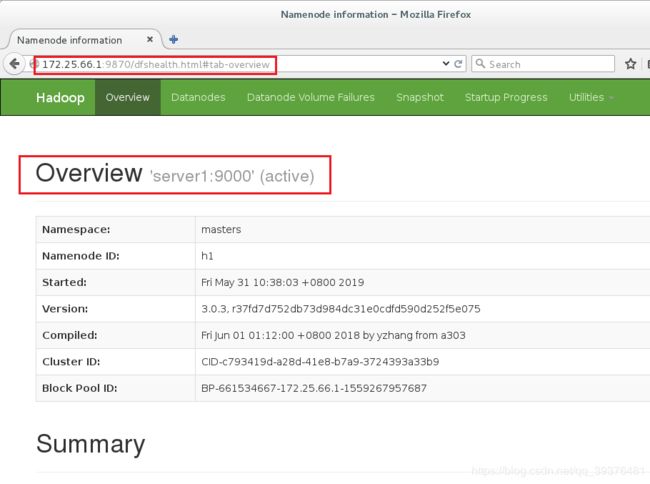
2.在浏览器中输入网址172.25.66.1:9870和172.25.66.2:9870,会发现server1中显示的是active,server5中显示的是standby

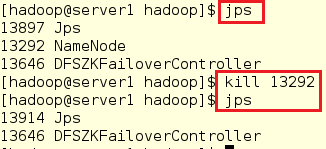
3.手动停掉server1,server5的状态就变成了active,而server1此时
[hadoop@server1 hadoop]$ jps
[hadoop@server1 hadoop]$ kill 13292
[hadoop@server1 hadoop]$ jps
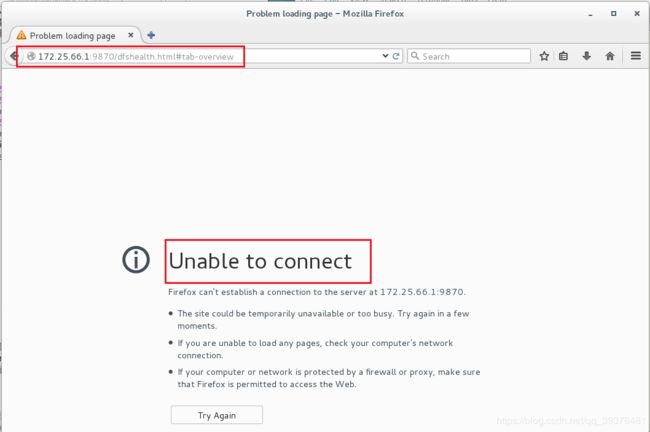
4.此时在浏览器中输入网址172.25.66.1:9870和172.25.66.2:9870,会发现server1无法连接,server5中显示的是active(杀掉 h1 主机的 namenode 进程
后依然可以访问,此时 h2 转为 active 状态接管 namenode)
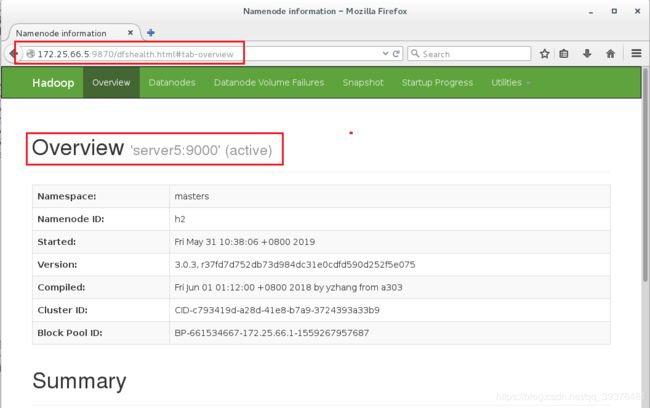
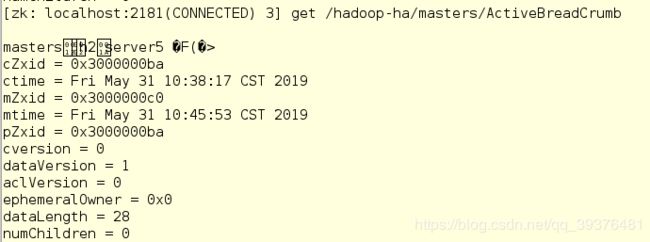
5.在命令中使用命令查看master在哪个节点上,此时发现在server5中
[zk: localhost:2181(CONNECTED) 3] get /hadoop-ha/masters/ActiveBreadCrumb
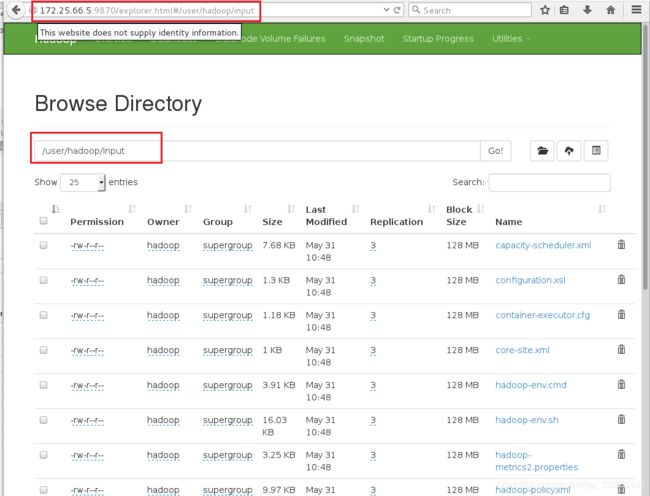
6.试图在server1中上传文件,发现虽然server1已经关闭,但是依旧可以上传文件
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/* input

7.在浏览器中输入网址172.25.66.5:9870,并选择Utilities->Browse the file system后会发现在server1中上传的文件
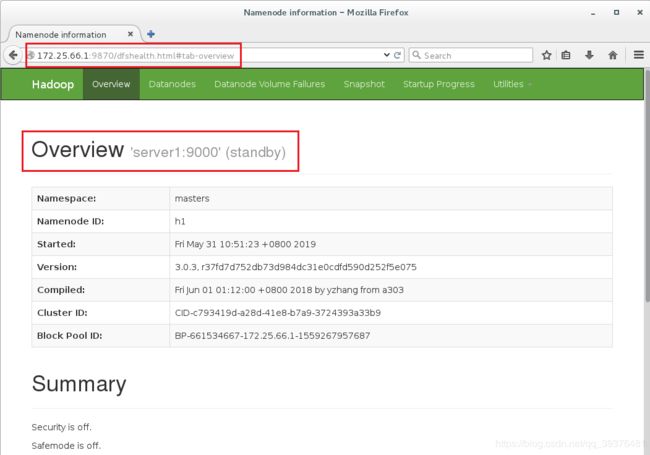
8.在server1中重新打开server1后,发现其状态会变成standby
[hadoop@server1 hadoop]$ bin/hdfs --daemon start namenode
[hadoop@server1 hadoop]$ jps

9.在浏览器中输入网址172.25.66.1:9870和172.25.66.2:9870,会发现server1中显示的是standby(备用),server5中显示的是active
总结:
1.在开始之前需要将原始的数据都清除,相当于重新初始化
2.tick是ms,其他都是s
3.zk节点的id,对应的主机名
4.2888是follow和领导者之间的通讯接口,3888做选举
5.1和5都是做高可用节点的
6.需要动态变,否则1挂了那么整个就挂了
7.告诉节点的值
8.masters中包含哪个主机,做隐射
9.首先要将zk集群提起来
10.本身就是一个高可用集群,所以不需要用他
出现的问题的总结:
如果出现namenode有时候有,有时候没有(在server1中没有出现任何问题,但当打开浏览器或者在server5中查看jps后就有问题),说明配置文件可能有错,首先关闭hdfs集群,修改配置文件后,需要将其server2,server3,server4中的journalnode关闭,再重新开启,然后格式化HDFS集群,格式化zookeeper即可