Python 自动化办公
自动化办公
- Excel
- ①读写
- ②套用模板 (EXCEL样式)
- Word
- ①任务案例一
- ②任务案例二
- 挑战实用案例:50个客户 批量生产N份不同乙方合同
- 数据可视化
- 邮件
- 微信自动化
- 正则表达式
Excel
①Excel文件读取与写入
②Excel模板套用
③配合数据库生成报表
Word
①格式文档生成
②word批量转PDF
③拆分和合并PDF
PPT
①PPT自动生成
②数据分析PPT自动生成
Excel
①读写
import xlrd
import xlwt
#读
xlsx = xlrd.open_workbook('C:/Users/acer/Desktop/1.xlsx')
table = xlsx.sheet_by_index(0) # 根据索引, 0表示工作簿的第一个表
# table = xlsx.sheet_by_name("sheet1") 根据表名也行
print(table.row(1)[0].value) #第一行 第0列
# print(table.cell_value(1,0))
#写
new_workbook = xlwt.Workbook() #创建工作簿
worksheet = new_workbook.add_sheet('new_test') #创建new_test表
worksheet.write(0,0,'test') #第0行第0列写入test内容
new_workbook.save('C:/Users/acer/Desktop/test.xlsx')
②套用模板 (EXCEL样式)
font\borders\alignment

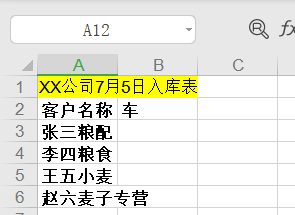
打开看看准备好的模板,test.xls
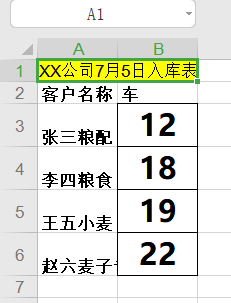
运行Python代码后的结果,test1.xls
from xlutils.copy import copy
import xlrd
import xlwt
#复制模板 xlutils对xlsx支持差
tem_excel = xlrd.open_workbook('C:/Users/acer/Desktop/test.xls',formatting_info=True)
tem_sheet = tem_excel.sheet_by_index(0) # 根据sheet索引或者名称获取sheet内容
new_excel = copy(tem_excel) #复制工作簿
new_sheet = new_excel.get_sheet(0) #获取第0个表
#初始化样式
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = '微软雅黑'
font.bold = True
font.height =360 #字体是18号,那么要18*20=360
style.font = font
borders = xlwt.Borders()
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
style.borders = borders
#对齐
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_CENTER #中心对齐 水平居中
alignment.vert = xlwt.Alignment.VERT_CENTER #垂直对齐 垂直居中
style.alignment = alignment
new_sheet.write(2,1,12,style) #行,列,内容,样式名
new_sheet.write(3,1,18,style)
new_sheet.write(4,1,19,style)
new_sheet.write(5,1,22,style)
new_excel.save('C:/Users/acer/Desktop/test1.xls')
❤xlsxwriter(超过256列写入才用到)
缺点 不支持带格式的文件
import xlsxwriter as xw
workbook = xw.Workbook('C:/Users/acer/Desktop/number.xlsx') #新建工作簿
sheet0 = workbook.add_worksheet('sheet0') #新建工作表
for i in range(0,300):
sheet0.write(0,i,i)
workbook.close()
❤openpyxl
缺点:性能不稳定,少了边框线等
import openpyxl
workbook = openpyxl.load_workbook('C:/Users/acer/Desktop/number.xlsx') #打开工作簿
sheet0 = workbook['sheet0'] #打开工作表
sheet0['B6'] = '测试' #向单元格写入值
sheet0['B7'] = '4'
sheet0['B8'] = 4
workbook.save('C:/Users/acer/Desktop/测试写数据.xlsx')
挑战实用案例:把文件名快速整理到Excel中
import os
import xlwt
file_dir = 'd:/'
os.listdir(file_dir)
new_workbook = xlwt.Workbook() #新建工作簿
worksheet = new_workbook.add_sheet('new_test') #新建表
n = 0
for i in os.listdir(file_dir):
worksheet.write(n,0,i)
n += 1
new_workbook.save('C:/Users/acer/Desktop/file_name.xls')
Word
①任务案例一



from docx import Document #安装的库是 python-docx
from docx.enum.text import WD_ALIGN_PARAGRAPH #对齐
from docx.shared import Pt #磅数
from docx.oxml.ns import qn #中文格式
# 以上是docx库中需要用到的部分
import time
price = input('请输入今日价格:')
company_list = ['客户1','客户2','客户3']
today = time.strftime("%Y-%m-%d",time.localtime()) #"%Y/%m/%d" ,time对中文支持较差
print(today)
for i in company_list:
document = Document()
document.styles['Normal'].font.name = u'宋体'
# 设置文档的基础字体
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'),u'宋体')
# 设置文档的基础中文字体
p1 = document.add_paragraph()
# 初始化建立第一个自然段
p1.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 对齐方式为居中,没有这句的话默认左对齐
run1 = p1.add_run('关于下达%s产品价格的通知' % (today))
run1.font.name = '微软雅黑' # 设置西文字体
run1.element.rPr.rFonts.set(qn('w:eastAsia'),u'微软雅黑') # 设置中文字体
run1.font.size = Pt(21) #设置字体大小为21磅
run1.font.bold = True #设置加粗
p1.space_after = Pt(5) # 段后距离5磅
p1.space_before = Pt(5) # 段前距离5磅
p2 = document.add_paragraph()
run2 = p2.add_run(i + ':') # 这里是对客户的称呼
run2.font.name = '仿宋_GB2312'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run2.font.size = Pt(16)
run2.font.bold = True
p3 = document.add_paragraph()
run3 = p3.add_run(' 根据公司安排,为提供优质客户服务,我单位拟定了今日黄金价格为%s元,特此通知。' % price)
run3.font.name = '仿宋_GB2312'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run3.font.size = Pt(16)
run3.font.bold = True
p4 = document.add_paragraph()
p4.alignment = WD_ALIGN_PARAGRAPH.CENTER
run4 = p4.add_run(' (联系人:小杨 电话:123456)')
run4.font.name = '仿宋_GB2312'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run4.font.size = Pt(16)
run4.font.bold = True
document.save('C:/Users/acer/Desktop/办公自动化/Word/%s-价格通知.docx' %i) #以“客户名-价格通知”作为文件名保存
②任务案例二

from docx import Document #安装的库是 python-docx
from docx.enum.text import WD_ALIGN_PARAGRAPH #对齐
from docx.shared import Pt #磅数
from docx.oxml.ns import qn #中文格式
from docx.shared import Inches #图片尺寸
import time
price = input('请输入今日价格:')
company_list = ['客户1','客户2','客户3']
today = time.strftime("%Y-%m-%d",time.localtime()) #"%Y/%m/%d" ,time对中文支持较差
for i in company_list:
document = Document()
document.styles['Normal'].font.name = u'微软雅黑'
# 设置文档的基础字体
document.styles['Normal'].element.rPr.rFonts.set(qn('w:eastAsia'), u'微软雅黑')
# 设置文档的基础中文字体
document.add_picture('C:/Users/acer/Desktop/banner.png',width=Inches(6))
# 在文件最上头插入图片作为文件头,宽度为6英寸
p1 = document.add_paragraph()
# 初始化建立第一个自然段
p1.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 对齐方式为居中,没有这句的话默认左对齐
run1 = p1.add_run('关于下达%s产品价格的通知' % (today))
run1.font.name = '微软雅黑' # 设置西文字体
run1.element.rPr.rFonts.set(qn('w:eastAsia'),u'微软雅黑') # 设置中文字体
run1.font.size = Pt(21) #设置字体大小为21磅
run1.font.bold = True #设置加粗
p1.space_after = Pt(5) # 段后距离5磅
p1.space_before = Pt(5) # 段前距离5磅
p2 = document.add_paragraph()
run2 = p2.add_run(i + ':') # 这里是对客户的称呼
run2.font.name = '仿宋_GB2312'
run2.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run2.font.size = Pt(16)
run2.font.bold = True
p3 = document.add_paragraph()
run3 = p3.add_run(' 根据公司安排,为提供优质客户服务,我单位拟定了今日黄金价格为%s元,特此通知。' % price)
run3.font.name = '仿宋_GB2312'
run3.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run3.font.size = Pt(16)
run3.font.bold = True
p4 = document.add_paragraph()
p4.alignment = WD_ALIGN_PARAGRAPH.CENTER
run4 = p4.add_run(' (联系人:小杨 电话:123456)')
run4.font.name = '仿宋_GB2312'
run4.element.rPr.rFonts.set(qn('w:eastAsia'), u'仿宋_GB2312')
run4.font.size = Pt(16)
run4.font.bold = True
#设置表格
table = document.add_table(rows=3,cols=3,style='Table Grid') #Word中自带的表格格式 Table Grid
table.cell(0,0).merge(table.cell(0,2)) #合并单元格,这个写法就像Excel,左上,右下
# 0,1 0,2都是同样的效果,因为合并了
table_run1 = table.cell(0,0).paragraphs[0].add_run('XX产品报价表') #单元格-》段落-》内容
table_run1.font.name = u'隶书'
table_run1.element.rPr.rFonts.set(qn('w:eastAsia'),u'隶书')
table.cell(0, 0).paragraphs[0].alignment = WD_ALIGN_PARAGRAPH.CENTER #表头居中
table.cell(1,0).text = '日期' #直接使用文档默认字体
table.cell(1, 1).text = '价格'
table.cell(1, 2).text = '备注'
table.cell(2, 0).text = 'today'
table.cell(2, 1).text = str(price)
table.cell(2, 2).text = ''
#设置分页符,最后打个广告
document.add_page_break()
p5 = document.add_paragraph()
run5 = p5.add_run('此处是广告')
document.save('C:/Users/acer/Desktop/办公自动化/Word/Word(图片+表格)/%s-价格通知.docx' %i) #以“客户名-价格通知”作为文件名保存
挑战实用案例:50个客户 批量生产N份不同乙方合同

from docx import Document
import xlrd
# Word 方案
def change_text(old_text,new_text):
all_paragraphs = document.paragraphs
for paragraph in all_paragraphs:
for run in paragraph.runs:
run_text = run.text.replace(old_text,new_text)
run.text = run_text
all_tables = document.tables
for table in all_tables:
for row in table.rows:
for cell in row.cells:
cell.text = cell.text.replace(old_text,new_text)
cell.text = cell.text
# Excel 信息(客户信息,放在Word进行替换)
xlsx = xlrd.open_workbook('合同信息表.xlsx')
sheet = xlsx.sheet_by_index(0)
for table_row in range(1,sheet.nrows):
document = Document("模板.docx")
for table_col in range(0,sheet.ncols):
change_text(str(sheet.cell_value(0,table_col)),str(sheet.cell_value(table_row,table_col)))
document.save("%s合同.docx" % str(sheet.cell_value(table_row,0)))
print("%s合同完成" % str(sheet.cell_value(table_row,0)))
数据可视化
Pandas 做数据透视表
import pandas as pd
import numpy as np
e_file = pd.ExcelFile('C:/Users/acer/Desktop/入库单.xlsx')
data = e_file.parse('Sheet1')
# print(data)
# 行、列、value、aggfunc是计算地区量 margins是True 总ALL
pt1 = pd.pivot_table(data, index=['销售商'],columns=['来源省份'], values=['入库量'],aggfunc=np.sum,margins=True)
pd.set_option('display.max_columns',None)
pt2 = pd.pivot_table(data, index=['销售商'],columns=['来源省份'], values=['入库量'],aggfunc=np.size,margins=True)
print(pt1)
print(pt2)
Matplotlib 画图
对中文的支持下较差,因此要有 用来正常显示中文标签
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
date = ['2018/7/21','2018/7/22','2018/7/23']
hebei = [69,93,65]
shanxi = [36,37,41]
###折线图###
# plt.plot(date,hebei,color='red',label='河北') # 横坐标,纵坐标
# plt.plot(date,shanxi,color='blue',label='山西')
# plt.title('每日入库量对比')
# plt.xlabel('日期')
# plt.ylabel('车次')
# plt.legend()
# plt.show()
###柱状图###
# plt.bar(date,hebei,color='red',label='河北')
# plt.legend()
# plt.show()
#水平柱状图
# plt.barh(date,hebei,color='red',label='河北')
# plt.legend()
# plt.show()
###饼图### 1对1的数据
number = [666,354]
province = ['河北','山西']
colors = ['#999fff','#fff999']
plt.pie(x=number,labels=province,colors=colors)
plt.legend()
plt.show()
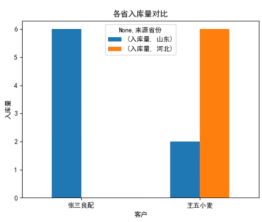
Pandas + Matplotlib 生成各种图表
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
e_file = pd.ExcelFile('C:/Users/acer/Desktop/入库单.xlsx')
data = e_file.parse('Sheet1')
# print(data)
# 行、列、value、aggfunc是计算地区量 margins是True 总ALL
pd.set_option('display.max_columns',None)
pt2 = pd.pivot_table(data, index=['销售商'],columns=['来源省份'], values=['入库量'],aggfunc=np.size)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
pt2.plot(kind='bar')
plt.xticks(rotation=0) # 横坐标
plt.title('各省入库量对比')
plt.xlabel('客户')
plt.ylabel('入库量')
plt.show()
邮件
邮件01: 最基础
import smtplib
from smtplib import SMTP_SSL
from email.mime.text import MIMEText #构造邮件正文
from email.mime.multipart import MIMEMultipart #邮件的主体
from email.header import Header #邮件标题,收件人
host_server = "smtp.qq.com"
mail_title = u"梨泰院class" # 邮件标题
sender = "[email protected]" # 发件人
receiver = "[email protected]"
mail_content = "你好" # 邮件正文
msg = MIMEMultipart() # 邮件主体(容器)
msg['Subject'] = Header(mail_title,'utf-8')
msg['From'] = sender
msg['To'] = receiver
msg.attach(MIMEText(mail_content,'plain','utf-8')) # 邮件正文内容
# plain是无格式
smtp = SMTP_SSL(host_server) # SSL登录
smtp.login("[email protected]", "xxxxx") # xxxx 是QQ邮箱的授权码
smtp.sendmail(sender, receiver, msg.as_string()) # 富文本转字符串
smtp.quit()
邮件02:附带HTML格式的 + 附件
import smtplib
from smtplib import SMTP_SSL
from email.mime.text import MIMEText # 构造邮件正文
from email.mime.multipart import MIMEMultipart # 邮件的主体
from email.mime.application import MIMEApplication # 邮件的附件
from email.header import Header # 邮件标题,收件人
host_server = "smtp.qq.com"
mail_title = u"梨泰院class" # 邮件标题
sender = "[email protected]" # 发件人
receiver = "[email protected]"
mail_content = "你好 百度 " # 邮件正文
msg = MIMEMultipart() # 邮件主体(容器)
msg['Subject'] = Header(mail_title,'utf-8')
msg['From'] = sender
msg['To'] = receiver
# msg.attach(MIMEText(mail_content,'plain','utf-8')) # 邮件正文内容
# plain是无格式
msg.attach(MIMEText(mail_content,'html','utf-8'))
# 附件
attachment = MIMEApplication(open("1.PNG",'rb').read())
msg.attach(attachment)
try:
smtp = SMTP_SSL(host_server) # SSL登录
smtp.ehlo(host_server) # 跟服务器打个招呼,确定一下状态,不是所有的邮件服务器都需要这个功能。建议加上
smtp.login("[email protected]", "fxxxxxx") # fxxxxxx 是QQ邮箱的授权码
smtp.sendmail(sender, receiver, msg.as_string()) # 富文本转字符串
smtp.quit()
print("邮件发送成功")
except smtplib.SMTPException:
print("无法发送邮件")
邮件03: HTML 定位嵌套图片
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.image import MIMEImage
HOST = "smtp.qq.com"
SUBJECT = u"梨泰院class"
FROM = "[email protected]"
TO = "[email protected]"
def addimg(src, imgid):
fp = open(src, 'rb')
msgImage = MIMEImage(fp.read()) # 读取图片的二进制数据 放到对象msgImage
fp.close()
msgImage.add_header('Content-ID', imgid)
return msgImage
# MIMEMultipart 多部分组成
msg = MIMEMultipart('related') #像一个容器
msgtext = MIMEText("""

Look! Styles and colors
This text is in Verdana and red
This text is in Times and green
This text is 30 pixels high
 """
,_subtype='html', _charset='utf8')
msg.attach(msgtext)
msg.attach(addimg("1.PNG","class"))
msg.attach(addimg("2.PNG","dream"))
#xlsx 读完文件 base64编码 utf8的字符集
attach = MIMEText(open("1.xlsx","rb").read(),"base64","utf-8")
attach["Content-Type"] = "application/octet-stream" #附件类型
msg.attach(attach) #塞进容器
try:
msg['Subject'] = SUBJECT
msg['From'] = FROM
msg['To'] = TO
server = smtplib.SMTP(HOST)
server.login("[email protected]", "xxxxx") # xxxxx 是QQ邮箱的授权码
server.sendmail(FROM, [TO], msg.as_string()) # 富文本转字符串
server.quit()
print("Send OK")
except Exception:
print("Fail" + str(e))
"""
,_subtype='html', _charset='utf8')
msg.attach(msgtext)
msg.attach(addimg("1.PNG","class"))
msg.attach(addimg("2.PNG","dream"))
#xlsx 读完文件 base64编码 utf8的字符集
attach = MIMEText(open("1.xlsx","rb").read(),"base64","utf-8")
attach["Content-Type"] = "application/octet-stream" #附件类型
msg.attach(attach) #塞进容器
try:
msg['Subject'] = SUBJECT
msg['From'] = FROM
msg['To'] = TO
server = smtplib.SMTP(HOST)
server.login("[email protected]", "xxxxx") # xxxxx 是QQ邮箱的授权码
server.sendmail(FROM, [TO], msg.as_string()) # 富文本转字符串
server.quit()
print("Send OK")
except Exception:
print("Fail" + str(e))
邮件04:接收邮件 zmail
import zmail
server = zmail.server('[email protected]', 'frvhwkfykwfwbjhh')
mail = server.get_latest()
zmail.show(mail)
print(mail['subject']) # 只获取标题
print(mail['id'])
print(mail['from'])
print(mail['to'])
print(mail['content_text'])
print(mail['content_html'])
# 保存了mail里的全部附件,target_path 默认存放路径 None 表当前
zmail.save_attachment(mail,target_path='C:/Users/acer/Desktop/垃圾文件',overwrite=True)
微信自动化
import itchat
from wxpy import * # 导入wxpy库
@itchat.msg_register(TEXT) # @是函数的修饰,作用:如果收到是纯文字信息,则执行下面的函数
def text_reply(msg):
print(msg.text)
reply_text = msg.text.replace('吗?', '!')
print(reply_text)
return reply_text
@itchat.msg_register([PICTURE,RECORDING,ATTACHMENT,VIDEO]) # 如果是图片,录音,附件,视频等
def download_files(msg):
print(msg)
msg.download(msg.fileName) # 以fileNmae命名 存到Python文件所在的文件夹下
bot = Bot() # 登录微信web
xiaobin = bot.mps().search('小栤机器人')[0] # 机器人设为小栤机器人, 关注微信公众号:小栤机器人
group = bot.groups() # 找出所有群聊,为避免小冰跑到群里说话
chat = 0
@bot.register() # 接受所有消息
def forward_others(msg):
global chat
global group
global friend
# 指定群聊
#group = bot.groups().search('Amy Agony')[0]
# 指定好友
#friend = bot.friends().search('好友名')[0]
# if msg.chat != xiaobin and msg.chat not in group: # 消息不是小冰的,也不是群消息,则转发给小冰,意思就和好友聊天
if msg.chat != xiaobin:
chat = msg.chat # 说话的人
msg.forward(xiaobin) # 转发消息给小冰
else:
if msg.chat == xiaobin: # 说话对象是小冰
msg.forward(chat, suffix='--彬彬机器人') # 转发消息给,对你说话的好友,并且在小冰的消息后面加上‘--XX’
bot.join()
itchat.auto_login(enableCmdQR=True,hotReload=True)
itchat.run() # 保证在一直运行
正则表达式
\b 代表单词开头或者结尾,不代表任何东西,只是标识位置,单词只能包括数字、字母、汉子等,不包括特殊符号
^ 代表字符串的开头
$ 代表字符串的结尾
\d 匹配一位数字
\d {数量} 匹配若干数量
\b\d{6}\b 单词开始 中间6个数 单词结束
\b\d{7,10}\b 大于等于7 小于等于10个数
\b\d{7,}\b 大于等于7
.匹配除换行符以外的任意字符
·111... 找以111开头,后面三个任意
·111.* 找以111开头,后面任意数
* 代表前面的部分重复任意次,可能为0次
+ 代表前面的部分重复任意次,不可能为0次
? 代表前面的部分0次或1次
\s 匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等
\w 匹配字母或数字或下划线或汉字等
( ) 分组 括号里作为一个整体
| 或
[\u4e00-\u9fa5]* 专门匹配所有汉字
[范围] 某个范围的字符[0-9][a-z][A-Z]
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开头或结束的位置
[^范围] 匹配除了范围以外的任意字符