VVC/H.266会议提案阅读(一)之JVET-A1001
目录
- JVET-A1001
- 变换编码
- 1、自适应多核变换(Adaptive multiple Core transform)
- 2、二次变换(Secondary transforms )
- 3、信号相关变换(Signal dependent transform (SDT))
- 自适应环路滤波(Adaptive loop filter)
- 熵编码(Context adaptive binary arithmetic coding (CABAC))
- 1、转换系数级别的上下文模型选择
- 2、多假设概率估计(Multi-hypothesis probability estimation)
- 3、初始化上下文模型
- 测试环境
- 1、参考软件
- 2、测试环境
JVET-A1001
接下来就把文档JVET-A1001中剩下的关于变换、量化、后处理等技术给了解一下。
变换编码
变换编码的改进主要在自适应多核变换(AMT)、二次变换和信号相关变换(SDT)。
1、自适应多核变换(Adaptive multiple Core transform)
除了在HEVC中使用的DCT-II和4x4 DST-VII外,JEM还采用了自适应多变换核(AMT)方案对帧内和帧间编码的残差块进行变换编码。它将DCT/DST多个不同的转换方式进行组合。新引入的变换矩阵有DST-VII、DCT-VIII、DST-I和DCT-V。对于帧内预测残差,根据帧内预测模式预先定义变换集,因此每个帧内预测模式都有自己的变换集,例如某个帧内预测模式变换集可以是{DCT-VIII, DST-VII}。注意,用于水平和垂直变换的变换集不同,即使对于相同的帧内预测模式也是如此。然而,对于帧间预测残差,对于所有帧间预测模式以及水平和垂直变换,只使用一个变换集。

AMT适用于小于64x64的CUs,并且AMT在CU级别上受到控制。
2、二次变换(Secondary transforms )
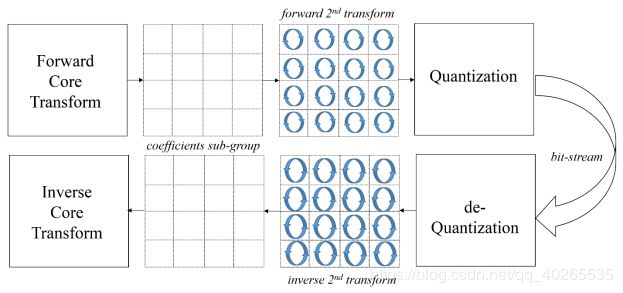
二次变换应用于正向核变换和量化(在编码器)之间,反量化和反向核变换(在解码器端)之间,即对在主变换之后对主变换系数进行第二次变换,之后再进行量化、熵编码等操作。在JEM中,如下图所示,对每个4×4的变换系数子组分别进行二次变换,并且只适用于帧内编码的CU。在JEM中,采用模式相关不可分的二次变换(MDNSST)。二次变换的示意图如下:
下面以以一个例子描述不可分离变换的应用。要应用不可分离变换,4x4输入块X为:
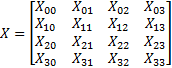
X首先表示为向量:
![]()
不可分变换计算为:
![]()
其中F表示变换系数向量,T为16x16变换矩阵。随后,使用该块的扫描顺序(水平、垂直或对角线)将16x1系数向量重新组织为4x4块。
该技术中共11×3(方向模式) + 1×2(非方向模式)不可分离变换矩阵,即总共有12组,其索引从0到11,其中11为帧内预测模式变换集的个数,每个变换集包含3个变换矩阵。而对于非方向模式,即平面、DC和LM,只应用了一个变换集,其中包含2个变换矩阵。下表定义了从帧内预测模式到转换集的映射,应用于亮度/色度变换系数的变换集由相应的亮度/色度预测模式指定。

3、信号相关变换(Signal dependent transform (SDT))
考虑到帧内和帧间有许多相似的块,利用KLT来研究这种相关性可以提高编码性能,更有效地进行压缩。
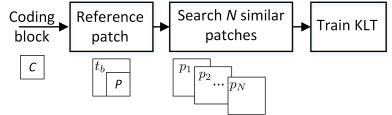
图中的流程图描述了这种思想,对于当前编码块C,首先得到参考块R,R由重构的左上模板 t b t_b tb和编码块的预测块p组成的;然后,用这个参考块R在重建区域内搜索N个最相似的块;最后,基于这些相似的块和预测块计算出一维KLT。该技术适用于不同块大小的4x4、8x8、16x16和32x32,利用率失真优化方法,确定了所提出的变换与DCT/DST变换之间的最佳模式。
为了更加清楚的说明,直接使用例子,KLT通过在重构区域中进行搜索,得到N个与参考块最相似的块 x i x_i xi,i=1,2,…… N N N,此处, x i x_i xi=( x i 1 x_i1 xi1, x i 2 x_i2 xi2…… x i D x_iD xiD),D表示变化块的向量维度,如对于4x4的编码块,D为16。通过这些相似块减去预测块p可获得残差块 u i u_i ui,i=1,2,……N,如下公式:
![]()
这些残差块被用于KLT求导零均值的训练样本,这些N个训练样本可以表示为:U=( u 1 u_1 u1, u 2 u_2 u2…… u N u_N uN),是一个DxN的矩阵。则协方差矩阵Σ为: Σ = U U T Σ=UU^T Σ=UUT,该协方差矩阵的维度为DxD。则KLT的基是该协方差矩阵的特征向量,以此可得到SDT的变换矩阵。
自适应环路滤波(Adaptive loop filter)
在JEM中,实现了基于块的自适应ALF。对于亮度分量,4x4块根据一维Laplacian方向(最多3个方向)和二维Laplacian活性(最多5个活性值)进行分类。方向 D i r b Dir_b Dirb和活性值 A c t b Act_b Actb的计算如式下所示,其中 I i , j I_i,j Ii,j为4x4块左上角相对坐标(i,j)的重建像素。
![]()
![]()
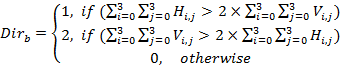
![]()
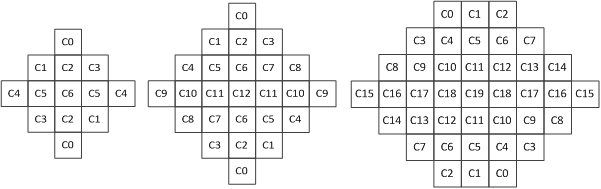
总的来说,每个块可以分为15个(5x3)组中的一个,并根据块的 D i r b Dir_b Dirb和 A c t b Act_b Actb为每个4x4块分配一个索引。因此,对于图像的亮度分量,最多可以发出15组ALF参数,对于图像的两个色度分量,均采用单组ALF系数,且始终使用5x5菱形滤波器。ALF最多支持三个对称滤波器的形状,如下图所示。此外,ALF在编码单元(CU)级别上发出标志,以指示ALF是否应用于该CU。
熵编码(Context adaptive binary arithmetic coding (CABAC))
相对于HEVC,CABAC的主要改进为:Modified context model selection for transform coefficient levels、Multi-hypothesis probability estimation、Adaptive initialization for context models,下面分别进行介绍。(熵编码的知识真的极其匮乏,理解的也不透彻,推荐这个大神的,讲的很详细。[https://blog.csdn.net/Peter_Red_Boy/article/details/89684179])
1、转换系数级别的上下文模型选择
在HEVC中,变换单元(TU)的变换系数采用非重叠系数组(CG)编码,每个CG包含TU的4x4块系数,TU内的CGs和CG内的变换系数按照预先定义的扫描顺序编码,将变换系数级的编码分解为多个扫描遍历。
1、在第一次扫描遍历中,对第一个bin(用bin0表示,也称为significant_coeff _flag,表示系数的大小大于0)进行编码。
2、接下来,可以应用两个扫描遍历来编码第二个/第三个bin(分别用bin1和bin2表示,也称为coeff_abs_greater1_flag和coeff_abs_greater2_flag,表示系数的大小大于1、2)。
3、最后,如果需要,将调用两个扫描遍历来编码符号信息和系数的剩余值(也称为coeff_abs_level_remaining)。
4、只有前三次扫描遍历中的bins才以常规模式编码,并在下面的描述中命名为常规bins。
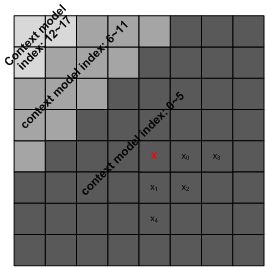
在JEM1中,修改了常规bins的上下文模型选择方法。当在第i次扫描遍历中编码bini (i为0,1,2)时,上下文索引依赖于本地模板所覆盖的邻域中先前编码系数的第i个bins的值。更具体地说,上下文索引是根据相邻系数的第i个bin之和确定的,如上图所示本地模板包含多达五个空间相邻变换系数,其中x表示当前变换系数的位置,而xi(i为0到4)表示其五个相邻变换系数。为了捕捉不同频率下变换系数的特性,可以将一个TU分割成三个区域,并列出分配给每个区域的上下文索引,并且不论TU的大小,分割方法都是固定的。亮度和色度分量以类似的方式处理,但是使用不同的上下文模型集。
2、多假设概率估计(Multi-hypothesis probability estimation)
采用多假设概率更新模型的二进制算术编码时,两个概率 P 0 P_0 P0和 P 1 P_1 P1与每个上下文模型相关联。它们是独立更新的,公式如下:
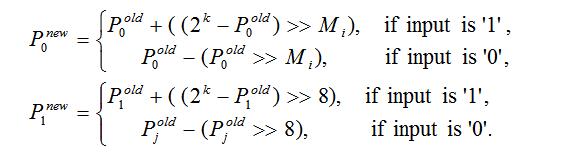
M i M_i Mi是一个控制概率更新速度的参数,k表示概率的精度(这里等于15),概率P是用于区间细分的二进制算术编码器,是2个假设的组合:
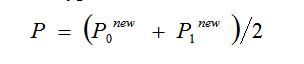
3、初始化上下文模型
在HEVC中,上下文模型的初始概率状态可以通过复制先前编码的帧来初始化,而不是使用固定的表来初始化上下文。更具体地说,在对每张图片的中心位置CTU进行编码之后,将存储所有上下文模型的概率状态,并可选地用作后面帧上每个对应上下文模型的初始状态。
在JEM中,每个帧间编码帧的初始概率状态都是从先前编码的帧中复制而来的,要求该帧具有与当前帧相同的帧类型和相同的帧级别QP。
测试环境
1、参考软件
JEM的主要软件是在HEVC标准参考软件HM16.6的基础上开发的,其软件可以从以下链接下载:[https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM]
(这是我自己下载VTM的链接)
2、测试环境
JEM实验的常用测试条件目前是基于某篇文档中定义的已知HEVC常用测试条件,并进行了以下改进:
1、只进行10bit深度的编码。
2、有Low-delay P编码和 Low-delay B编码。
3、使用交叉分量线性模型(CCLM)预测特性时,将全I帧(AI)和随机存取(RA)配置的色度QP值偏移+1。
终于看完了JVET-A1001文档,会有一些理解不清楚的地方,希望在后面的学习中慢慢改进,加油!!