爬虫(一):认识爬虫+搜索引擎+爬虫分类+爬虫准备工作+http和https
文章目录
- 一、爬虫工程师的分类
- 1.初级爬虫工程师
- 2.中级爬虫工程师
- 3.高级爬虫工程师
- 二、认识爬虫
- 1.爬虫定义
- 2.爬虫解决的问题
- 三、搜索引擎
- 1.搜索引擎的工作流程
- 2.搜索引擎的局限性
- 四、爬虫分类
- 五、爬虫准备工作
- 1.robot协议
- 2.网络地图sitemap
- 3.估算网站大小
- 4.了解网站架构
- 5、获取网站所有者
- 六、http和https
- hash例子————给字符串和文件进行hash加密
- 七、案例练习
一、爬虫工程师的分类
1.初级爬虫工程师
- 1.web 前端的知识: HTML、CSS、JavaSc1ipt、 DOM、 DHTML 、Ajax、jQuery、json 等;
- 2.正则表达式, 能提取正常一般网页中想要的信息,比如某些特殊的文字, 链接信息, 知道什么是懒惰, 什么是贪婪型的正则;
- 3.会使用 XPath 等获取一些DOM 结构中的节点信息;
- 4.知道什么是深度优先, 广度优先的抓取算法, 及实践中的使用规则;
- 5.能分析简单网站的结构, 会使用urllib或requests 库进行简单的数据抓取。
2.中级爬虫工程师
- 1.了解什么事HASH,会简单地使用MD5,SHA1等算法对数据进行HASH一遍存储
- 2.熟悉HTTP,HTTPS协议的基础知识,了解GET,POST方法,了解HTTP头中的信息,包括返回状态码,编码,user-agent,cookie,session等
- 3.能设置user-agent进行数据爬取,设置代理等
- 4.知道什么事Request,什么事response,会使用Fiddler等工具抓取及分析简单地网络数据包;对于动态爬虫,要学会分析ajax请求,模拟制造post数据包请求,抓取客户端session等信息,对于一些简单的网站,能够通过模拟数据包进行自动登录。
- 5.对于一些难搞定的网站学会使用phantomjs+selenium抓取一些动态网页信息
- 6.并发下载,通过并行下载加速数据爬取;多线程的使用。
3.高级爬虫工程师
1、能够使用Tesseract,百度AI,HOG+SVM,CNN等库进行验证码识别。
2、能使用数据挖掘技术,分类算法等避免死链。
3、会使用常用的数据库进行数据存储,查询。比如mongoDB,redis;学习如何通过缓存避免重复下载的问题。
4、能够使用机器学习的技术动态调整爬虫的爬取策略,从而避免被禁IP封禁等。
能使用一些开源框架scrapy,scrapy-redis等分布式爬虫,能部署掌控分布式爬虫进行大规模数据爬取。
二、认识爬虫
1.爬虫定义
一个程序脚本—>自动的抓取互联网上信息的脚本。
2.爬虫解决的问题
- 解决冷启动问题
- 搜索引擎的根基:做搜索引擎少不了爬虫
- 建立知识图谱,帮助建立机器学习知识图谱
- 可以制作各种商品的比价软件,趋势分析。
三、搜索引擎
1.搜索引擎的工作流程
1. 第一步:抓取网页
通过搜索引擎将待爬取的url加入到通用爬虫的url队列中,进行网页内容的爬取
2. 第二步:数据存储
将爬取下来的网页保存到本地,这个过程会有一定的去重操作,如果某个网页的内容大部分内容都会重复,搜索引擎可能不会保存
3. 第三步:预处理
- 提取文字
- 中文分词
- 消除噪音(比如版权声明文字,导航条,广告等)
4. 第四步:设置网站排名,为用户提供服务
2.搜索引擎的局限性
- 搜索引擎只能爬取原网页,但是页面90%内容都是无用的
- 搜索引擎不呢个满足不同行业,不同人的特定需求
- 通用搜索引擎只能爬取文字信息,不能对音频、图片等进行爬取
- 只能基于关键字查询,无法基于语义查询
四、爬虫分类
A.通用爬虫:就是将互联网的上页面整体的爬取下来之后,保存到本地。
通用爬虫要想爬取网页,需要网站的url.但是搜索引擎是可以搜索所有网页的。那么通用爬虫url就要涉及到所有网页,这个‘所有’是如何做到的。
- 新网站向搜索引擎主动提交网址
- 在其他网站上设置新网站外链。
- 搜索引擎和DNS解析服务商(如DNSPod等)合作,新网站域名将被迅速抓取。
B.聚焦爬虫:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
五、爬虫准备工作
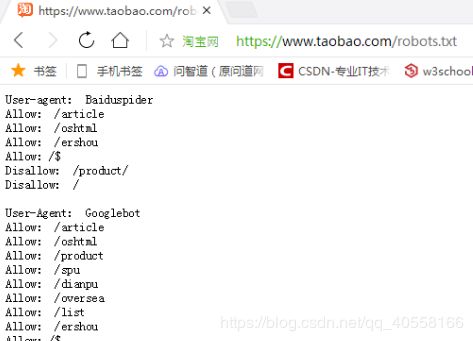
1.robot协议
- 定义:网络爬虫排除标准
- 作用:告诉搜索引擎哪里可以爬,哪里不可以爬
2.网络地图sitemap
- 作用:就是一个网站地图,可以知道网站的子网站
- 常用:help.bj.cn
3.估算网站大小
- 在百度上搜索
4.了解网站架构
为了更好的了解网站,抓取该网站的信息,我们可以先了解一下该网站大致所使用的的技术架构。
①安装builtwith:
Import buildwith
Buildwith.parse(‘http://www.sina.com.cn’)
②使用:在python交互环境下,输入:
Import buildwith
Buildwith.parse(‘http://www.sina.com.cn’)
5、获取网站所有者
1.安装python-whois:pip install python-whois
2.使python的交互模式下输入:
Import whois
Whois.whois(‘http://www.sina.com.cn’)
六、http和https
1.什么是http协议?
- 超文本传输协议
- 一个规范,约束发布和接受html页面的规范
2.端口号
- http协议端口号:80
- https协议的端口号:443
3.http协议的特点
- 是一个应用层协议
- 无连接
- 每次请求都是独立的。
- http 1.1着呢国家了一个connection:keep-alive,表示客户端和服务器的连接是一个长连接
- 无状态
- 表示客户端每次请求都不能记录请求状态,就是两条请求直接不可通信
- cookie和session可以帮助记录状态
4.url:统一资源定位符
- 为啥可以通过url定位互联网上的任意资源
http://ip:port/path- ip:可以定位电脑
- port:端口号—用来从互联网进入电脑
- path:就是为了在电脑中找到对应的资源路径
- 三种特殊符号
- ? 问号后面就是请求参数
- & 请求参数用&连接,例如:?name=zhangsan&age=12
- 警号# 表示锚点:锚点就是在请求这个url时,页面会跳入的指定位置
- 基本格式:scheme://host[:port#]/path/…/?query-string
-
scheme:协议(例如:http, http, ftp)
-
host:服务器的IP地址或者域名
1.port:服务器的端口(如果是走协议默认端口,缺省端口80)
2.path:访问资源的路径
3.query-string:参数,发送给http服务器的数据
4.anchor:锚(跳转到网页的指定锚点位置)在python中,有一个模块可以帮助我们解析url。 代码: from urllib import parse url = 'http://localhost.com:8080/index.htm?username="zhangsan"&password="123"' print(parse.urlparse(url)) 输入内容: ParseResult( scheme='http', netloc='localhost.com:8080', path='/index.htm', params='', query='', fragment='')
-
5.http工作过程
(1)地址解析,将url解析出对应的内容:scheme:协议(例如:http, http, ftp)
- host:服务器的IP地址或者域名
- port:服务器的端口(如果是走协议默认端口,缺省端口80)
- path:访问资源的路径
- query-string:参数,发送给http服务器的数据anchor:锚(跳转到网页的指定锚点位置)
(2)封装http请求数据包
(3)封装成TCP包,建立TCP连接(TCP的三次握手)
TCP握手协议
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
SYN:同步序列编号(Synchronize Sequence Numbers)
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据

(4)客户端发送请求
(5)服务器接收请求,发送响应
(6)服务器关闭tcp连接
6.当我们在浏览器输入一个url,为什么可以加载出一个页面?为什么在抓包的过程中请求了一个url,会出现很多的资源请求?
- 我们在浏览器输入一个url,客户端会发送这个url对应的一个请求到服务器获取内容
- 服务器收到这个请求,解析出对应内容,之后将内容封装到响应里发送到客户端
- 当客户端拿到这个html页面,会查看这个页面中是否有css、js、image等url,如果有,在分别进行请求,获取到这些资源。
- 客户端会通过html的语法,将获取到的所有内容完美的显示出来。
7.客户端请求
①组成:请求行、请求头部、空行、请求数据四个部分组成
② 请求方法get/post
- 1.get方法:
get,获取—>从服务器上获取资源—>通过请求参数来告诉服务器获取什么资源。—>请求参数是在url里面用&进行拼接的,也就是?后面的内容。---->所以不安全—>传输参数大小受限。 - 2.post请求:
post,传递—>向服务器传递数据---->数据是封装在请求的实体。—>可以传递更多内容—>更安全。 - 3.get和post的区别
(1)get是从服务器获取内容,post是向服务器传递内容
(2)get不安全,因为参数拼接在url后面。post比较安全,因为参数是放在是实体里面。
(3)get传参大小受限,post不受限。
③重要的请求头:
User-Agent:客户端请求标识。
Accept: (传输文件类型)允许传入的文件类型。
Referer :表明产生请求的网页来自于哪个URL,用户是从该Referer页面访问到当前请求的页面。
cookie (cookie):在做登录的时候需要封装这个头。
Content-Type (POST数据类型)
发送POST请求时,需要特别注意headers的一些属性:
Content-Length: 144: 是指发送的表单数据长度为144,也就是字符个数是144个。
X-Requested-With: XMLhttpRequest :表示Ajax异步请求。
8.服务响应
- 组成:状态行,响应头,空行,响应正文。
- 重要响应头:Content-Type:text/html;charset=UTF-8:告诉客户端,资源文件的类型,还有字符编码
- 状态码:
- 100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。
- 200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。
- 300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、 常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
- 400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服 务器拒绝访问,权限不够—DDos)。
- 500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
hash例子————给字符串和文件进行hash加密
import hashlib
#对一个字符串进行hash
def hash_str(text):
md5 = hashlib.md5()
md5.update(bytes(text,encoding='utf-8'))
return md5.hexdigest()#返回密文的16进制格式
#--------------------------------------------------
#对文件进行hash
#对文件进行hash要避免把文件全部读出来在进行
chuckSize = 4096
def hash_file(filename):
h = hashlib.sha256()
with open(filename,'rb') as f:
while True:
chuck = f.read(chuckSize)
if not chuck:
break
h.update(chuck)
return h.hexdigest()#得到文件最终的hash
七、案例练习
# -----------------------------------------1.用递归方式完成斐波那契数列。
# 方法1
def Fbnq(num):
if num == 1 or num == 2:
return 1
else:
return Fbnq(num - 1) + Fbnq(num - 2)
num = int(input('输入数字:'))
print(Fbnq(num))
# 方法2
a, b, c = 0, 1, []
for i in range(num):
if num == 1:
a = 1
c.append(a)
else:
a, b = b, a + b
c.append(a)
print(c)
#--------------------------------------------------------------------
# 2.用递归的方法,获取一个列表的最大值和最小值。
from copy import deepcopy
def GetMax(list):
if len(list) == 1:
return list[0]
else:
if list[0] > list[1]:
del list[1]
else:
del list[0]
return GetMax(list)
def GetMin(list):
if len(list) == 1:
return list[0]
else:
if list[0] > list[1]:
del list[0]
else:
del list[1]
return GetMin(list)
list = [1, 2, 3, 0, -5, 99, 213, -32]
list_copy = deepcopy(list)
print('该列表最大值:', GetMax(list))
print('该列表最小值:', GetMin(list_copy))