背景介绍
由于Graph模块直到最近几个版本才加入到Guava中,网上对应的中文教程也几乎是缺失的,因此想借机翻译下它对应wiki的文档,以此作为入门示例。文章肯定有一些翻译不恰当的地方,会在一步一步的了解其理念后,渐进的更新注释。
对应的原文文档为:https://github.com/google/guava/wiki/GraphsExplained
为了便于理解,先抛出它的架构类图,在心目中有个大概的轮廓:
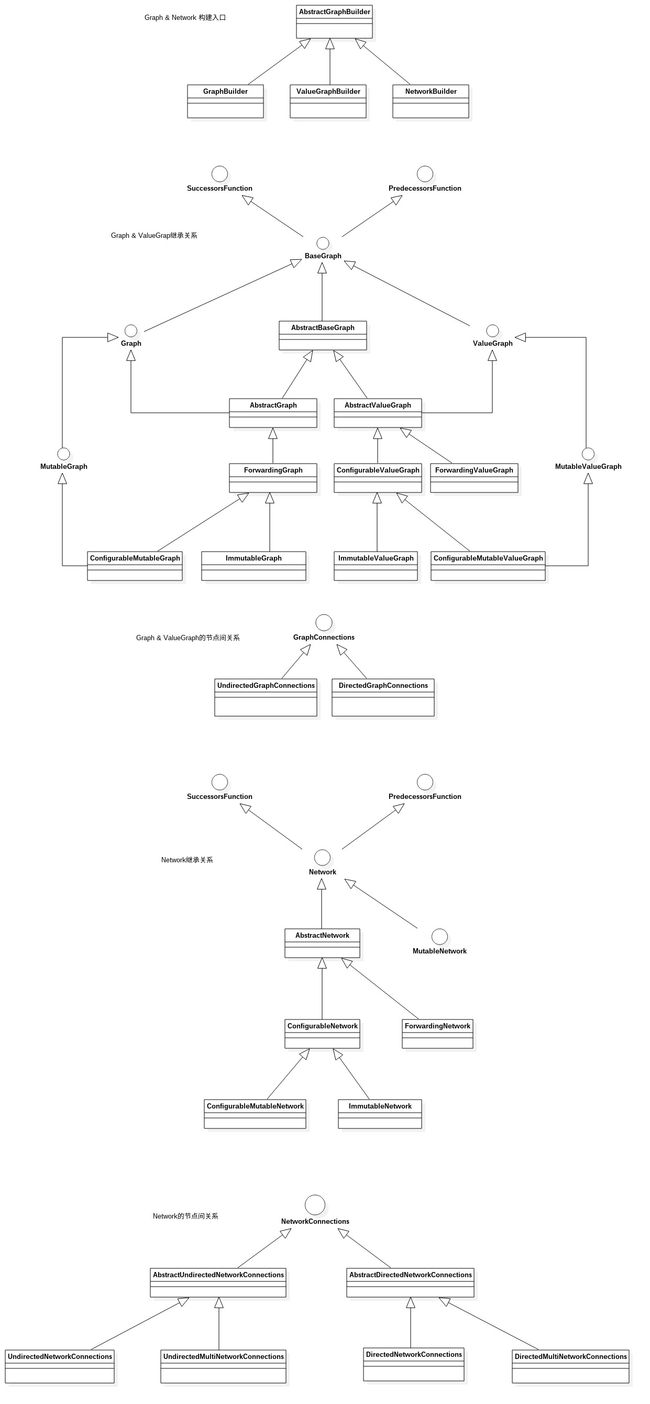
图论的解释
Guava库的目录common.graph包含的模块是一个描述实体(entity)以及实体之间的关系的图数据结构模型库。例如:网页与超链接、科学家与他们写的论文、机场与其航线、人与其家族等。Guava-Graph模块的目的是提供一种通用以及可扩展的语言来描述类似上述的举例。
定义(Definitions)
图中包含一组节点(node)(也称为顶点)和一组连接节点的边(edge)(也称为链接或者弧);边缘的节点我们称为端点(endpoint)。(我们将在下文介绍一个叫Graph的接口,我们将使用“图”来作为一般术语描述该数据结构,也可以使用它引用某个具体的图类型,即接口Graph有很多具体的实现类)。
如果一条边定义了开始(source)和结束(target),这条边被城为有向边(directed),否则称为无向边(undirected)。有向边适用于非对称的关系模型(起源、指向、作者),而无向边适用于对称关系模型(折叠、距离、同级关系)。
图中每一条边都是有向边的,则被称为有向图;每一条边都是无向的,则被称为无向图。(common.graph模块不支持图中既有有向边又有无向边的情形。)
举例:
graph.addEdge(nodeU, nodeV, edgeUV);
-
nodeU和nodeV是两个邻接点(adjacent)。 -
edgeUV是顶点nodeU到顶点nodeV的事件(incident)(反之亦然)
在有向图中,有如下定义:
-
nodeU是nodeV的一个前趋(predecessor) -
nodeV是nodeU的一个后继(successor) -
edgeUV是nodeU的一条出度(outgoing)边 -
edgeUV是nodeV的一条入度(incoming)边 -
nodeU是边edgeUV的起点(source) -
nodeV是边edgeUV的终点(target)
在无向图中,有如下定义:
-
nodeU既是nodeV的前趋也是nodeV的后继 -
nodeV既是nodeU的前趋也是nodeU的后继 -
edgeUV既是nodeU的入度也是nodeU的出度 -
edgeUV既是nodeV的入度也是nodeV的出度
一条连接节点本身的边被称为自环(self-loop),也就是说,一条边连接了两个相同的节点。如果这个自环是有向的,那么这条边既是节点的入度边也是节点的出度边,这个节点既是边的起点(source)也是边的终点(target)。
如果两条边以相同的顺序连接相同的节点,则称这两条边为平行边(parallel);如果以相反的顺序连接相同的节点则称这两条边为逆平行边(antiparallel)。(无向边不能被称为逆平行边)
例如:
//有向图
directedGraph.addEdge(nodeU, nodeV, edgeUV_a);
directedGraph.addEdge(nodeU, nodeV, edgeUV_b);
directedGraph.addEdge(nodeV, nodeU, edgeVU);
//无向图
undirectedGraph.addEdge(nodeU, nodeV, edgeUV_a);
undirectedGraph.addEdge(nodeU, nodeV, edgeUV_b);
undirectedGraph.addEdge(nodeV, nodeU, edgeVU);
在有向图directedGraph中,边edgeUV_a和边edgeUV_b是相互平行边,与边edgeVU是逆平行边;
在无向图undirectedGraph中,边edgeUV_a、edgeUV_b和edgeVU是两两相互逆平行边。
功能(Capabilities)
common.graph模块的核心是提供图相关操作的接口和类。另外,它没有提供类似I/O或者可视化的功能。如果选用这个模块将会有非常多的限制,具体详细信息可以查看下面FAQ的相关主题。总体来讲,它提供了如下几种类型的图:
- 有向图
- 无向图
- 节点和(或)边带权图
- 允许(不允许)自环图
- 允许(不允许)平行边图(允许平行边图有时也称为多重图(
multigraphs) - 节点或边被有序插入、顺序、无序图(graphs whose nodes/edges are insertion-ordered, sorted, or unordered)
Javadoc中有这样的描述:common.graph中的各种类型的图都是通过与其相关的Builder具体实现类型来构建的,不过这些Builder实现类型不一定支持上面提到的所有图类型,但也可能支持其他类型的图。
库中图的数据结构是通过矩阵、邻接list或邻接map等方式来存储的,选择何种存储方式取决于适用的实现场景。
对于以下这些变形图在common.graph中没有确切的支持,尽管它们可以通过已有的图类型进行建模:
- 树(
trees)、森林(forests) - 由不同类型的同类元素(
节点或边)构成的图。(二分图/k分图、multimodal graphs) - 超图
common.graph不允许图中同时存在有向边和无向边。Graphs中提供了很多基本操作(如:图的拷贝和比较操作)。
图的类型
common.graph模块中有三种通过边来作为区分依据的"top-level"接口(interface):Graph、 ValueGraph、和Network。另外还存在一些同级类型,不过这些都不是这三种类型的子类型。
上面三种 "top-level" 接口都继承自接口SuccessorsFunction和PredecessorsFunction。这样做是为了在仅需要访问节点的后继(successors)或者前趋(predecessors)的图中,它可以直接被用来作为图算法(例如,BFS广度优遍历)中参数的类型。 This is especially useful in cases where the owner of a graph already has a representation that works for them and doesn't particularly want to serialize their representation into a common.graph type just to run one graph algorithm.(不知道怎么翻)
Graph
Graph是最简单也是最基本的图类型。为了处理节点与节点之间的关系它定义了一些基本的操作,例如:successors(node)-->获取node的后继、adjacentNodes(node)-->获取node的邻接点、inDegree(node)-->获取node的入度等。这些节点在图中都是唯一的对象,在其内部数据结构中,你可以认为它们是Map的键值(Key)。
Graph中的边是完全匿名的,他们只能根据端点来定义。举例:Graph中,其边连接任意两个可以直航的机场。
ValueGraph
接口ValueGraph包含了Graph中的所有与节点相关的方法,并增加了一些检索指定边权值的方法。
ValueGraph中的每一条边都有一个与之相关的特定权值,但是这些权值不能保证唯一性。ValueGraph与Graph的关系类似与Map与Set的关系(Graph中的边是以顶点对的形式保存在Set中,而ValueGraph的边是以顶点对与其权值的映射关系保存在Map中)。
ValueGraph提供了一个asGraph()的函数,它可以从ValueGraph中返回一个Graph视图,这样作用于Graph实例上的方法也能作用于ValueGraph的实例上。
举例:ValueGraph,其边表示在能直航的两个机场之间航班必须花费的时间。
Network
Network中包含了Graph中的所有与节点相关的方法,还增加了操作边以及操作顶点与边的关系的方法,例如:outEdges(node)--->获取node的出度边, incidentNodes(edge)-->获取边edge的顶点对, 和 edgesConnecting(nodeU, nodeV)-->获取nodeU和nodeV的直连边。
Network中每一条边都是唯一的,就像节点在所有的Graph类型中是唯一的一样。边的唯一性限制使得Network能够天然的支持并行边,以及与边和节点与边相关的方法。
Network类提供了一个asGraph()的方法,它可以从Network中返回一个Graph视图,这样作用于Graph实例上的方法也能操作Network的实例上。
举例:Network,它的每一条边代表了从一个机场到另一个机场可以乘坐的特定航班(两个机场之间可以同时有多趟航班)。
如何选择合适的图类型
这三种图类型之间本质的区别在于它们边表示的不同:
-
Graph中的边是节点之间的匿名连接,没有自己的标识或属性。如果每一对节点之间都是通过最多一条边连接的,而且这些边没有任何与之相关的信息时,则选用它。 -
ValueGraph中的边带有一个值(例如权值或标签),且边在整个图中不能保证其唯一性。如果每一对节点之间都是通过最多一条边连接的,并且每一条边都有与之相关的权值时,则选用它。 -
Network中边是全局唯一的,就像节点在图中是唯一的一样。如果边对象需要唯一,并且希望能查询它们的引用时,则选用它。(请注意,这种唯一性使得Network支持平行边。)
构建图的实例
common.graph中图的具体实现类并没有设计成public的,这样主要是为了减少用户需要了解的图类型的数量,使得构建各种功能的图变得更加容易。
要创建一个内置图类型的实例,可以使用相应的Builder类: GraphBuilder, ValueGraphBuilder和NetworkBuilder。例如:
MutableGraph graph = GraphBuilder.undirected().build();
MutableValueGraph roads = ValueGraphBuilder.directed().build();
MutableNetwork webSnapshot = NetworkBuilder.directed()
.allowsParallelEdges(true)
.nodeOrder(ElementOrder.natural())
.expectedNodeCount(100000)
.expectedEdgeCount(1000000)
.build();
- 可以使用下面两种的任意一种方式通过
Builder来构建图实例:
1、调用静态方法directed()或者undirected()来实例化一个有向图或者无向图。
2、调用静态方法from()基于一个已存在的图实例构建图。 - 在创建了
Builder实例后,还可以选择指定其他特性和功能。 - 同一个
Builder实例可以多次调用build()方法来创建多个图的实例。 - 不需要在
Builder上指定节点和边的类型,只需要在图类型本身上指定即可。 -
build()方法返回一个Mutable子类型的图时,提供了变形的方法。下面将会介绍更多关于Mutable和Immutable的图。
Builder constraints vs. optimization hints
The Builder types generally provide two types of options: constraints and optimization hints.
Constraints specify behaviors and properties that graphs created by a given Builder instance must satisfy, such as:
- whether the graph is directed
- whether this graph allows self-loops
- whether this graph's edges are sorted
and so forth.
Optimization hints may optionally be used by the implementation class to increase efficiency, for example, to determine the type or initial size of internal data structures. They are not guaranteed to have any effect.
Each graph type provides accessors corresponding to its Builder-specified constraints, but does not provide accessors for optimization hints.
可变(Mutable)和不可变(Immutable)图
Mutablexx类型
每种图类型都有与其对应的Mutablexx子类型: MutableGraph,MutableValueGraph,以及 MutableNetwork。这些子类型定义了下面这些变形方法:
- 增加和删除节点的方法:
addNode(node)、removeNode(node)。 - 增加和删除边的方法:
MutableGraph-->putEdge(nodeU, nodeV)、removeEdge(nodeU, nodeV)。
MutableValueGraph-->putEdgeValue(nodeU, nodeV, value)、removeEdge(nodeU, nodeV)。
MutableNetwork-->addEdge(nodeU, nodeV, edge)、removeEdge(edge)。
这些方法的定义与java的集合类型以及guava的新集合类型都有所不同——每种类型都包含变形方法的函数签名。选择将变形方法放在子类型中,一部分原因是为了鼓励防御性编程:一般来说,如果你的代码只是为了检查或者遍历一个图,而不改变它,那么输入应该就指定为Graph、ValueGraph或者Network类型,而不是它们的可变子类型。另一方面,如果你的代码确实需要修改一个对象,那么使用带Mutable修饰的子类对你会很有帮助。
由于Grpah等都是接口,即使它们不包含这些变形方法,但这些接口的实例并不能保证这些方法不被调用(如果它们实际上是Mutablexx的子类型),因为调用者可能会将其转换成该子类型。如果有一种契约的保证,即一个方法的参数或返回值不能被修改的Grahp类型,你可以使用下面介绍的这种不可变(Immutable)实现。
Immutablexx的实现
每一种图类型(Graph、ValueGraph、 Network)都有相应的不可变实现类(ImmutableGraph、ImmutableValueGraph、ImmutableNetwork),这些类类似于Guava的ImmutableSet、ImmutableList、ImmutableMap等,一旦被创建出来,它们就不能被修改,且它们在内部使用了高效的不可变数据结构。
不同与Guava的其他不可变类型,这些不可变实现类压根没有提供修改的方法,所以他们不需要抛出UnsupportedOperationException异常来应对这些操作。
通过调用静态方法copyOf()来创建ImmutableGraph等的实例。例如:
ImmutableGraph immutableGraph = ImmutableGraph.copyOf(graph);
每一种Immutable*类型提供了一下保证:
- 不变性:元素不能被添加、删除、替换。(这些类没有实现
Mutable*的接口) - 迭代的确定性:迭代顺序总是和输入图的顺序相同
- 线程安全:多个线程同时访问该图是安全的操作
- 完整性:该类型不能在包之外定义子类型(允许违反这条)
将这些类看作成接口(interface),而不是实现类:
每一个Immutable*类都是提供了有意义行为保证的类型,而不仅仅是特定的实现类。所以你应该把它们当作是有重要意义的接口来看待。
如果字段或返回值是Immutable*的实例(如ImmutableGraph),则应将其申明为Immutable*类型,而不是对应的接口类型(如Graph)。This communicates to callers all of the semantic guarantees listed above, which is almost always very useful information.
另一方面,一个ImmutableGraph类型的参数对调用者来说会觉得比较麻烦,而更倾向与Graph类型。
警告:正如其他地方指出的,修改一个包含在集合中的元素几乎总是一个坏注意,这样会导致一些未定义的行为和错误出现。因此,通常最好避免使用可变对象作为Immutable*类型的对象的元素,因为大多数用户是期望你的immutable对象是真的不可修改。
图的元素(节点和边)
节点(Network中的边)必须可以用做Map的键:
- 必须在图中唯一:当且仅当
nodeA.equals(nodeB) == false时,则认为nodeA和nodeB是不相等的。 - 必须合适的实现函数
equals()和hashCode()。 - 如果元素是有序的(例如
GraphBuilder.orderNodes()),则必须和equals()保持一致(由Comparator和Comparable接口定义)
如果图的元素有可变状态:
- 不能在
equals()/hashCode()方法中反射获取可变状态(这些在Map的相关文档中有过详细讨论) - 不要创建多个相等的元素,并希望它们可以互换。特别是,如果你需要在创建期间多次引用这些元素,应该在向图中添加这些元素时一次性的创建并保存其引用(而不是每次都通过
new MyMutableNode(id)传给add**()的中)
如果需要保存可变元素的每一个可变状态,可以选用不可变元素,并将可变状态保存在单独的数据结构中(如:一个元素状态Map)。
图的元素必须不能为null!
common.graph的契约和行为
本节讨论常见内置图的实现方式。
变形
可以往图中添加一条边,如果图中还没有出现对应的两个端点时,两个端点则会静默添加到图中:
Graph graph = GraphBuilder.directed().build(); // graph is empty
graph.putEdge(1, 2); // this adds 1 and 2 as nodes of this graph, and puts
// an edge between them
if (graph.nodes().contains(1)) { // evaluates to "true"
...
}
图的equals()和等价
Guava的22版本中每种图都定义有特定意义的equals():
-
Graph.equals()定义为两个相等的Graph有相同的节点和边集(也就是说,两个Graph中,每条边有相同的端点以及相同的方向)。 -
ValueGraph.equals()定义为两个相等的ValueGraph有相同的节点和边集,并且边上的权重也相等。 -
Network.equals()定义为两个相等的Network有相同的节点和边集,以及每个边对象都以相同的方向连接相同的节点(如果有边的话)。
此外,对于每种图类型,只有它们的边具有相同的方向时,两个图才能是相等的(两个图要么都是有向的,要么都是无向的)。
理所当然,hashCode()函数在每种图类型中都与equals()保持一致。
如果想比较两个Network或者两个基于连接性的ValueGraph,或者将一个Network或一个ValueGraph与Graph进行比较,可以使用Network和ValueGraph提供的Graph视图:
Graph graph1, graph2;
ValueGraph valueGraph1, valueGraph2;
Network network1, network2;
// compare based on nodes and node relationships only
if (graph1.equals(graph2)) { ... }
if (valueGraph1.asGraph().equals(valueGraph2.asGraph())) { ... }
if (network1.asGraph().equals(graph1.asGraph())) { ... }
// compare based on nodes, node relationships, and edge values
if (valueGraph1.equals(valueGraph2)) { ... }
// compare based on nodes, node relationships, and edge identities
if (network1.equals(network2)) { ... }
访问器方法
访问器可以返回下面两种集合:
- 返回图的视图。不支持对图的修改将结果反映到到视图上(例如,在通过
nodes()遍历图时,又在调用addNode(n)或者removeNode(n)),而且可能会抛出ConcurrentModificationException异常。 - 尽管输入是有效的,但是当没有元素满足请求时,则会返回一个空集合。
如果传递的元素不在图中,访问器将会抛出IllegalArgumentException异常。
一些JDK的集合框架中的方法(如contains())使用对象来作为参数,而没有使用合适的泛型参数;在Guava22中common.graph模块中方法一般采用泛型参数来改进类型的安全性。
同步
图的同步策略取决于每个图自己的实现。默认情况下,如果在另一个线程中修改了图,则调用图的任何方法都可能导致未定义的行为。
一般来说,内置的实现的可变类型没有提供同步的保证,但是Immutable*类型(由于是不可修改的)是线程安全的。
元素对象
添加到图中的节点、边或值对象与内置实现无关,它们只是作为内部数据结构的键。这意味这,节点/边可以在图实例之间共享。
默认情况下,节点和边是按照顺序来插入的(也就是说,nodes()和edges()的Iterator是按照它们加入到图中的顺序的顺序来访问的,就像在LinkedHashSet中一样)。
实现者的笔记
存储模型
common.graph支持多种机制来存储图的拓扑结构,包括:
- 图本身自己实现拓扑存储(例如使用
Map存储,将节点映射到邻接节点上),这意味着节点只是键,可以在不同的图之间共享。 - 节点自己存储拓扑顺序(例如
List存储的邻接节点),这意味着节点独立与图。 - 一个单独的数据存储库(如数据库)存储拓扑顺序。
注意:Multimap不是一个支持孤立节点(没有边的节点)的内部数据结构,由于它们的限制,一个键要么至少映射一个值,要么不出现在Multimap中。
访问行为
对于返回一个集合的访问器函数,有下面几个语义选项:
- 集合是一个不可变拷贝(例如:
ImmutableSet):试图以任何方式修改集合的尝试都将抛出异常,且对图的修改不会反映到集合中。 - 集合是一个不可修改的视图(例如:
Collections.unmodifiableSet()):视图以任何方式修改集合的尝试都将抛出异常,且对图的修改将反映到集合中。 - 集合是一个可变拷贝:它可以被修改,但是对图的修改不会反映到集合中,反之亦然。
- 集合是一个可变的视图:它可以被修改,对集合的修改也将反映到图中,反之亦然。
(理论上,你可以返回一个through writes in one direction but not the other (collection-to-graph or vice-versa)的集合,但是基本上不会有用或者逻辑清晰,所以请不要这样做)
(1)和(2)一般是首选,在撰写本文时,内置的实现通常使用(2);(3)是一个可行的选项,但是如果用户期望修改集合影响图,或者对图的修改反映在集合上,可能会让用户感到困惑;(4)是一个非常危险的设计选择,应该非常谨慎的使用,因为这样很难保证内部数据结构的一致性。
Abstract*类
每一种图都有一个相应的Abstract类:AbstractGraph等。
如果可能的话,图的实现应该继承适当的Abstract类,而不是直接实现接口。Abstract类提供了几个比较难正确执行或者有助于实现一致性实现的方法,例如:
*degree()toString()Graph.edges()Network.asGraph()
代码例子
判断节点是否在图中?
graph.nodes().contains(node);
节点u和节点v是否存在边?
在无向图的情况下,下面例子中的参数u和v是顺序无关的。
// This is the preferred syntax since 23.0 for all graph types.
graphs.hasEdgeConnecting(u, v);
// These are equivalent (to each other and to the above expression).
graph.successors(u).contains(v);
graph.predecessors(v).contains(u);
// This is equivalent to the expressions above if the graph is undirected.
graph.adjacentNodes(u).contains(v);
// This works only for Networks.
!network.edgesConnecting(u, v).isEmpty();
// This works only if "network" has at most a single edge connecting u to v.
network.edgeConnecting(u, v).isPresent(); // Java 8 only
network.edgeConnectingOrNull(u, v) != null;
// These work only for ValueGraphs.
valueGraph.edgeValue(u, v).isPresent(); // Java 8 only
valueGraph.edgeValueOrDefault(u, v, null) != null;
Graph例子
MutableGraph graph = GraphBuilder.directed().build();
graph.addNode(1);
graph.putEdge(2, 3); // also adds nodes 2 and 3 if not already present
Set successorsOfTwo = graph.successors(2); // returns {3}
graph.putEdge(2, 3); // no effect; Graph does not support parallel edges
ValueGraph例子
MutableValueGraph weightedGraph = ValueGraphBuilder.directed().build();
weightedGraph.addNode(1);
weightedGraph.putEdgeValue(2, 3, 1.5); // also adds nodes 2 and 3 if not already present
weightedGraph.putEdgeValue(3, 5, 1.5); // edge values (like Map values) need not be unique
...
weightedGraph.putEdgeValue(2, 3, 2.0); // updates the value for (2,3) to 2.0
Network例子
MutableNetwork network = NetworkBuilder.directed().build();
network.addNode(1);
network.addEdge("2->3", 2, 3); // also adds nodes 2 and 3 if not already present
Set successorsOfTwo = network.successors(2); // returns {3}
Set outEdgesOfTwo = network.outEdges(2); // returns {"2->3"}
network.addEdge("2->3 too", 2, 3); // throws; Network disallows parallel edges
// by default
network.addEdge("2->3", 2, 3); // no effect; this edge is already present
// and connecting these nodes in this order
Set inEdgesOfFour = network.inEdges(4); // throws; node not in graph
遍历无向图
// Return all nodes reachable by traversing 2 edges starting from "node"
// (ignoring edge direction and edge weights, if any, and not including "node").
Set getTwoHopNeighbors(Graph graph, N node) {
Set twoHopNeighbors = new HashSet<>();
for (N neighbor : graph.adjacentNodes(node)) {
twoHopNeighbors.addAll(graph.adjacentNodes(neighbor));
}
twoHopNeighbors.remove(node);
return twoHopNeighbors;
}
遍历有向图
// Update the shortest-path weighted distances of the successors to "node"
// in a directed Network (inner loop of Dijkstra's algorithm)
// given a known distance for {@code node} stored in a {@code Map},
// and a {@code Function} for retrieving a weight for an edge.
void updateDistancesFrom(Network network, N node) {
double nodeDistance = distances.get(node);
for (E outEdge : network.outEdges(node)) {
N target = network.target(outEdge);
double targetDistance = nodeDistance + edgeWeights.apply(outEdge);
if (targetDistance < distances.getOrDefault(target, Double.MAX_VALUE)) {
distances.put(target, targetDistance);
}
}
}
FAQ
为什么Guava要介绍common.graph?
因为Guava所做的其他事情,同样的理论也适用于图:
- 代码重用/互操作性的统一范式:很多事情的处理都与图相关
- 效率:有多少代码使用了低效的、占用更多空间的图结构(例如矩阵表示)?
- 正确性:做图分析的代码有多少错误?
- 推广图的抽象数据类型:如果图更容易使用,会有多少人会使用图?
- 简洁性:code which deals with graphs is easier to understand if it’s explicitly using that metaphor.
common.graph都支持哪些类型的图?
上面的“功能”章节已经回答这个了。
common.graph没有 feature/algorithm X,后面会添加吗?
也许可能。
我们的理念是,如果(a)与Guava的核心使命相适应,那么就应该有这些东西;(b)有充分的理由期待它会被合理地广泛使用。
comon.graph可能永远都不会有像可视化或者I/O这样的功能,因为它们本身就可以成为一个项目,与Guava的任务不太相符。
像遍历(traversal)、过滤(filtering)或者转换(transformation)这样的功能更加合适,因此将更有可能被包含在库中,尽管最终我们希望其他的图库能提供这些功能。
是否支持非常大的图(例如MapReduce)?
这一次还不是。在少于百万个节点的图应该还是可行的,但你应该把这个库看成类似Java集合框架类型(Map、List、Set等等)。
为什么我要使用它而不是其他的库?
你应该使用适合你的方法,但是如果这个库不支持你,请告诉我们你需要什么。
这个库的主要竞品有:JUNG和JGraphT。
-
JUNG是Joshua O'Madadhain在2003年开源的(领先与common.graph),直到现在他还在维护它。JUNG是相当成熟和功能齐全的图库,已经被广泛使用,不过它仍有些晦涩而且低效。现在common.graph已经发布了,它计划创建一个新版本的JUNG。 -
JGraphT是另一个已经存在一段时间的第三方Java版的图库。我们不太熟悉它,所以我们不能详细评价它,但它至少与JUNG有一些共同点。
Rolling your own solution is sometimes the right answer if you have very specific requirements. But just as you wouldn’t normally implement your own hash table in Java (instead of using HashMap or ImmutableMap), you should consider using common.graph (or, if necessary, another existing graph library) for all the reasons listed above.
主要贡献者
common.graph是一个团队的努力,我们获得了来自谷歌内外许多人的帮助,只是下面这些人的影响最大:
- Omar Darwish做了很多早期的实现,并为覆盖测试设置了标准。
- James Sexton是该项目贡献最多的人,他对项目的方向和设计产生了重大的影响;他负责一些关键性特性也负责我们所提供这些实现上的有效性。
- Joshua O'Madadhain在反思
JUNG的优点和缺点后,在他的帮助下我们启动了common.graph项目,他领导了这个项目的开展,并对设计和代码的各个方面进行了review和编写。