python百余行代码能做什么?能实现一个类IDM下载程序!
文章目录
- 1.前言
- 2.环境
- 3.效果
- 4.实现步骤
- 4.1 导包
- 4.2 初始化
- 4.3 获取下载
- 4.4 终端打印
- 4.5 执行
- 5. 运行方法与效果
- 5.1 运行方法
- 5.2 效果
- 6.思考与不足
- 6. 1 思考
- 6.2 不足
- 7. 附录
- 7.1 程序下载
1.前言
很久没写博客了。某天在b站上面看到的使用python的多线程文件IO操作机制,突发奇想来实现下
人们总有这样的困扰,使用有名的工具下载大文件的时候,总会限速(比如某度云),使用迅雷下载BT文件的时候又不得不被广告困扰。使用IDM这种无限制下载软件的时候 ,又会弹出各种注册弹窗的问题。故笔者这里使用python的多线程文件IO下载,百行代码左右实现一个快速下载工具。
2.环境
- win10
- python3.6
- Pycharm2017
3.效果
使用python实现的类IDM下载器,具有不限制网速(取决于网速带宽),以及多线程下载的特点。
4.实现步骤
4.1 导包
实现这个功能主要用到的是python中的Request库,以及线程处理库,基于python对文件IO操作的友好性,使用较少的代码实现了上述下载的功能。
import os
import time
import sys
from requests import get,head
from concurrent.futures import ThreadPoolExecutor,wait
如果运行出错。可能需要安装相关包
4.2 初始化
新定义一个下载类,对其进行初始化,声明下载链接,线程数以及另存为的文件名
def __init__(self, url, nums, file):
self.url = url # url链接
self.num = nums # 线程数
self.name = file # 文件名字
self.getSize = 0 # 大小
self.info = {
'main': {
'progress': 0, # 主线程状态
'speed': '' # 下载速度
},
'sub': {
'progress': [0 for i in range(nums)], # 子线程状态
'stat': [1 for i in range(nums)] # 下载状态
}
}
r = head(self.url)
# 状态码显示302则迭代寻找文件
while r.status_code == 302:
self.url = r.headers['Location']
print("此url已重定向至{}".format(self.url))
r = head(self.url)
self.size = int(r.headers['Content-Length'])
print('该文件大小为: {} bytes'.format(self.size))
- HTTP中返回302表示文件重定向,可能出现的原因是下载文件链接失效,这时候主需要重新选择一个可以在游览器中就可以下载的文件连接即可
4.3 获取下载
定义一个下载方法,主要使用Request库,以及多线程的方式,由于python对文件I/O为密集型操作,较为友好,因此使用此种方式为直接获取的形式。
def down(self, start, end, thread_id, chunk_size = 10240):
raw_start = start
for _ in range(10):
try:
headers = {'Range': 'bytes={}-{}'.format(start, end)}
r = get(self.url, headers=headers, timeout=10, stream=True) # 获取
print(f"线程{thread_id}连接成功")
size = 0
with open(self.name, "rb+") as fp:
fp.seek(start)
for chunk in r.iter_content(chunk_size=chunk_size):
if chunk:
self.getSize += chunk_size
fp.write(chunk)
start += chunk_size
size += chunk_size
progress = round(size / (end - raw_start) * 100, 2)
self.info['sub']['progress'][thread_id - 1] = progress
self.info['sub']['stat'][thread_id - 1] = 1
return
except Exception as error:
print(error)
self.down(start, end, thread_id)
print(f"{start}-{end}, 下载失败")
self.info['sub']['start'][thread_id - 1] = 0
4.4 终端打印
定义一个显示方法,在终端对其但打印下载信息,包括主线程下载速度以及子线程线程数和状态
def show(self):
while True:
speed = self.getSize
time.sleep(0.5)
speed = int((self.getSize - speed) * 2 / 1024)
if speed > 1024:
speed = f"{round(speed / 1024, 2)} M/s"
else:
speed = f"{speed} KB/s"
progress = round(self.getSize / self.size * 100, 2)
self.info['main']['progress'] = progress
self.info['main']['speed'] = speed
print(self.info)
if progress >= 100:
break # end
4.5 执行
定义运行方法,包括对文件IO的处理以及下载判断
def run(self):
# 创建一个要下载的文件
fp = open(self.name, 'wb')
print(f"正在初始化下载文件: {self.name}")
fp.truncate(self.size)
print(f"文件初始化完成")
start_time = time.time()
fp.close()
part = self.size // self.num # 整除
pool = ThreadPoolExecutor(max_workers=self.num + 1)
futures = []
for i in range(self.num):
start = part * i
if i == self.num - 1:
end = self.size
else:
end = start + part - 1
futures.append(pool.submit(self.down, start, end, i + 1))
futures.append(pool.submit(self.show))
print(f"正在使用{self.num}个线程进行下载...")
wait(futures)
end_time = time.time()
speed = int(self.size / 1024 / (end_time - start_time))
if speed > 1024:
speed = f"{round(speed / 1024, 2)} M/s"
else:
speed = f"{speed} KB/s"
print(f"{self.name}下载完成,平均速度: {speed}")
入口函数如下
if __name__ == '__main__':
debug = 1 # 测试情况
if debug:
url = 'http://119.6.237.61:8899/w10.xitongxz.net/202007/DEEP_GHOST_WIN10_X64_V2020_07.iso'
down = Dowmloader(url, 8, os.path.basename(url))
else:
# 命令行执行方式
url = sys.argv[1] # 下载链接
file = sys.argv[2] # 默认保存在项目路径下,文件的名字以文件格式结尾
thread_num = int(sys.argv[3]) # 使用的线程数量
down = Dowmloader(url, thread_num, file)
down.run()
5. 运行方法与效果
5.1 运行方法
运行程序的方式有两种,
- 直接运行
- 使用命令行运行
直接运行就是直接在IDE中执行程序。输出为py文件,如上图所示,另外一种就是使用命令行参数的方式,可自行选择仙下载线程和文件名
比如我们的python文件名字为test_demo.py 要下载一个.iso文件,在工程目录下执行如下命令,我这里要下载的文件是一个iso镜像系统,
将其链接拷贝出来
# python .py文件 链接 文件名 线程数
python test_demo.py '链接' test.iso 8
![]()
5.2 效果
使用这种方式,将取决于自己网速,而不再受限制了,有点香啊
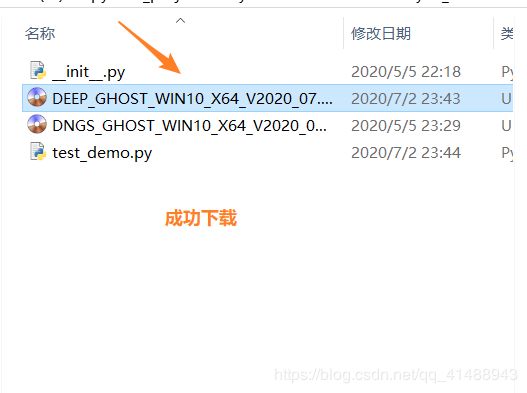
6.思考与不足
6. 1 思考
python中对任务的执行方法有两种
- CPU计算密集型:指CPU计算占主要的任务,CPU一直处于满负荷状态。比如在一个很大的列表中查找元素,复杂的加减乘除等。
- IO密集型:是指磁盘IO、网络IO占主要的任务,计算量很小。比如请求网页、读写文件等。当然我们在Python中可以利用time中的sleep达到IO密集型任务的目的
因此,在使用爬虫等网页操作的时候,多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好,而使用多线程时,考虑到计算机硬件结构的负担,线程保持在8个左右最为合适,设置较多的线程加大CPU的负担。
6.2 不足
在执行这个程序的时候,有些功能暂时未能实现,如
- 该程序暂时不能实现断点续传的功能,只能将程序一直运行下去,知道文件下载完毕
- 暂时未能将其封装为一个下载界面,提供可视化的下载监控,可能后期会实现下
7. 附录
7.1 程序下载
- GitHub
- CSDN