Python爬取前程无忧大数据57000条详细信息看看你到底适合什么?(requests请求-Xpath处理-csv存储)
前程无忧大数据网址:https://search.51job.com/list/000000,000000,0000,00,9,99,%E5%A4%A7%E6%95%B0%E6%8D%AE,2,1.html
入口获取所有的大数据相关岗位招聘信息。如从多个招聘网站获取更多招聘信息更好。
提取数据项至少包括以下字段:
(1)职位名称(岗位名称)、公司名称、 工作地点、薪资(底薪-上限)、发布时间(月-日);
说明:在招聘列表中获取

(2)工作年限要求,学历要求,招聘人数 职能类别
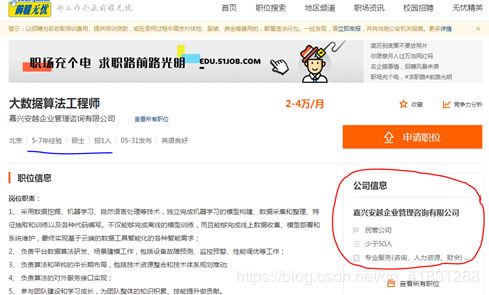
(3)公司性质 公司规模(人数) 公司所属行业
(2)和(3)字段对应网页位置:
由于数据量大,详细页面各式不统一,为了能够适应全部数据,条件判断稍微多了点。但是偶尔还是可能会出现SSL证书验证的问题,重新跑即可。
import requests
from lxml import etree
import csv
import logging
"""请求页面"""
def get_response(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
logging.captureWarnings(True)
response = requests.get(url,headers=headers,verify=False)
response.encoding = 'gbk'
return response.text
"""
获取主页面以及详情页内容
"""
def get_html(html):
html = etree.HTML(html)
infos = html.xpath('//div[@class="el"]')[4:]
info = []
for i in infos:
key = {}
key['job_name'] = str(i.xpath('.//p[@class="t1 "]//a/@title')).strip("[']")
key['company_name'] = str(i.xpath('.//span[@class="t2"]/a/text()')).strip("[']")
key['work_space'] = str(i.xpath('.//span[@class="t3"]/text()')).strip("[']")
key['work_pay'] = str(i.xpath('.//span[@class="t4"]/text()')).strip("[']")
key['pubish_date'] = str(i.xpath('.//span[@class="t5"]/text()')).strip("[']")
if "https" in str(i.xpath('.//p[@class="t1 "]//a/@href')):
key['detail_href'] = "https://jobs.51job.com/"+str(i.xpath('.//p[@class="t1 "]//a/@href')).strip("[']").split("com/")[1]
else:
key['detail_href'] = "https://jobs.51job.com/shanghai-sjq/106755892.html?s=01&t=0"
# if str(i.xpath('.//p[@class="t1 "]//a/@href')).strip("[']").strip(" ").startswith("h") is not True:
#
# key['detail_href'] = "https://"+str(i.xpath('.//p[@class="t1 "]//a/@href')).strip("[']").strip(" ")
# else:
# key['detail_href'] = str(i.xpath('.//p[@class="t1 "]//a/@href')).strip("[']").strip(" ")
"""
获取详情页信息
工作年限要求 学历要求 招聘人数 职能类别 公司性质 公司规模(人数) 公司所属行业
"""
detail_html_str = get_response(key['detail_href'])
detail_html = etree.HTML(detail_html_str)
if "|" in str(detail_html.xpath('.//p[@class="msg ltype"]/@title')):
key['year_limit'] = str(detail_html.xpath('.//p[@class="msg ltype"]/@title')).strip("[']").split('\\xa0\\xa0|\\xa0\\xa0')[1]
else:
key['year_limit'] = "无工作经验"
if "|" in str(detail_html.xpath('.//p[@class="msg ltype"]/@title')):
key['edu_limit'] = str(detail_html.xpath('.//p[@class="msg ltype"]/@title')).strip("[']").split('\\xa0\\xa0|\\xa0\\xa0')[2]
else:
key['edu_limit'] = "本科"
if "|" in str(detail_html.xpath('.//p[@class="msg ltype"]/@title')):
key['recruit_num'] = str(detail_html.xpath('.//p[@class="msg ltype"]/@title')).strip("[']").split('\\xa0\\xa0|\\xa0\\xa0')[3]
else:
key['recruit_num'] = "招若干人"
if str(detail_html.xpath('.//a[@class="el tdn"][1]')) is not False:
key['job_type'] = str(detail_html.xpath('.//a[@class="el tdn"]/text()')).strip("['\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t]").split("\\t\\t\\t\\t\\t\\t\\t\\t\\t")[0]
if "/" in key['job_type']:
key['job_type'] = key['job_type'].split("/")[0]
else:
key['job_type'] = str(detail_html.xpath('.//a[@class="el tdn"]/text()')).strip(
"['\\r\\n\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t]").split("\\t\\t\\t\\t\\t\\t\\t\\t\\t")[0]
else:
key['job_type'] = "无"
if str(detail_html.xpath('.//p[@class="at"][1]/@title')) is not False:
key['company_property'] = str(detail_html.xpath('.//p[@class="at"][1]/@title')).strip("[']")
else:
key['company_property'] = "无"
if str(detail_html.xpath('.//p[@class="at"][2]/@title')) is not False:
key['company_num'] = str(detail_html.xpath('.//p[@class="at"][2]/@title')).strip("[']")
else:
key['company_num'] = "无"
if str(detail_html.xpath('.//p[@class="at"][3]/@title')) is not False:
key['company_business'] = str(detail_html.xpath('.//p[@class="at"][3]/@title')).strip("[']")
else:
key['company_business'] = "无"
info.append(key)
print(info)
return info
"""写入csv文件的head"""
def write_header():
headers = ['职位名称', '公司名称', '工作地点', '薪资','发布日期','工作年限要求','学历要求','招聘人数','职能类别','公司性质','公司规模','公司所属行业']
with open('qianchengwuyou.csv', 'a+', encoding='UTF-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
"""保存数据"""
def save_data(info):
with open('qianchengwuyou.csv','a+',encoding='UTF-8',newline='') as fp:
writer = csv.writer(fp)
# writer.writerow(headers)
for key in info:
writer.writerow([key['job_name'],key['company_name'],key['work_space'],key['work_pay'],key['pubish_date'],key['year_limit'],key['edu_limit'],key['recruit_num'],key['job_type'],key['company_property'],key['company_num'],key['company_business']])
if __name__ == '__main__':
write_header()
#通过format构造url列表
urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,{}.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(i) for i in range(1,1106)]
for url in urls:
html = get_response(url)
info = get_html(html)
save_data(info)