R语言——线性判别分析(LDA)
R语言——线性判别分析*
线性判别分析是一种经典的线性学习方法,在二分类问题上最早由Fisher在1936年提出,亦称Fisher线性判别。线性判别的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别 。
LDA与方差分析(ANOVA)和回归分析紧密相关,这两种分析方法也试图通过一些特征或测量值的线性组合来表示一个因变量。然而,方差分析使用类别自变量和连续数因变量,而判别分析连续自变量和类别因变量(即类标签)。逻辑回归和概率回归比方差分析更类似于LDA,因为他们也是用连续自变量来解释类别因变量的。LDA的基本假设是自变量是正态分布的,当这一假设无法满足时,在实际应用中更倾向于用上述的其他方法。LDA也与主成分分析(PCA)和因子分析紧密相关,它们都在寻找最佳解释数据的变量线性组合。LDA明确的尝试为数据类之间不同建立模型。 另一方面,PCA不考虑类的任何不同,因子分析是根据不同点而不是相同点来建立特征组合。判别的分析不同因子分析还在于,它不是一个相互依存技术:即必须区分出自变量和因变量(也称为准则变量)的不同。在对自变量每一次观察测量值都是连续量的时候,LDA能有效的起作用。当处理类别自变量时,与LDA相对应的技术称为判别反应分析。
下面对R语言实现过程详细介绍
1.导入数据并做初步处理
mydata <- read.csv("tongji.csv")
mydata
mydata$Group <- as.factor(mydata$Group) #将Grop中的1,2转换成因子变量
attach(mydata)
2.观察数据分布情况
library(ggplot2) #导入包ggplot
ggplot(data = mydata , aes(x = height , y = weight , shape = Group ,color = Group))
1. geom_point() + geom_text(aes(label = 性别) , vjust = -0.8) #画出散点图,初步观察数据分布情况

3. 建立判别函数
library(MASS) #导入包MASS
sexyLd <- lda(Group ~ height + weight , data = mydata) #建立判别函数1
sexyLd1 <- lda(Group ~ height + weight + Vital.capacity + sprint + Endurance.running
+ Sitting.body.flexion + jump + Sit.ups +point , data = mydata) #建立判别函数2
sexyLd #查看函数1结果
sexyLd1 #查看函数2结果
> sexyLd
Call:
lda(Group ~ height + weight, data = mydata)
Prior probabilities of groups:
1 2
0.537415 0.462585
Group means:
height weight
1 161.4253 52.95823
2 172.9287 66.36993
Coefficients of linear discriminants:
LD1
height 0.15748938
weight 0.02471315
# 判别函数为y = 0.1575x1 + 0.02471x2
> sexyLd1
Call:
lda(Group ~ height + weight + Vital.capacity + sprint + Endurance.running +
Sitting.body.flexion + jump + Sit.ups + point, data = mydata)
Prior probabilities of groups:
1 2
0.537415 0.462585
Group means:
height weight Vital.capacity sprint Endurance.running Sitting.body.flexion jump Sit.ups point
1 161.4253 52.95823 2756.569 8.898101 3.782278 18.22215 171.0633 39.556962 77.58165
2 172.9287 66.36993 4054.000 7.370588 4.044044 12.01985 226.2721 4.227941 69.18750
Coefficients of linear discriminants:
LD1
height 0.0326378585
weight -0.0121919891
Vital.capacity 0.0003658433
sprint -0.9165278712
Endurance.running -0.4659634284
Sitting.body.flexion -0.0017160164
jump 0.0297380110
Sit.ups -0.0724816461
point -0.1259426473
# 判别函数为y = 0.0326x1 - 0.0122x2 + 0.0004x3 - 0.9165x4 - 0.4660x5 - 0.0017x6 + 0.0297x7 - 0.0725x8 - 0.1259x9
4.预测并原数据进行比较
sexyPredict <- predict(sexyLd) #根据线性函数模型预测所属类别
newGroup <- sexyPredict$class #预测的所属类的结果
cbind(mydata$Group , sexyPredict$x , newGroup) #显示预测前后分组结果
sexyPredict1 <- predict(sexyLd1) #根据线性函数模型预测所属类别
newGroup1 <- sexyPredict1$class #预测的所属类的结果
cbind(mydata$Group , sexyPredict1$x , newGroup1) #显示预测前后分组结果
5.对模型进行评价
tab <- table(mydata$Group , newGroup) #绘制混淆矩阵
tab
erro <- 1-sum(diag(prop.table(tab))) #计算误判率
erro
plot(tab) #可视化
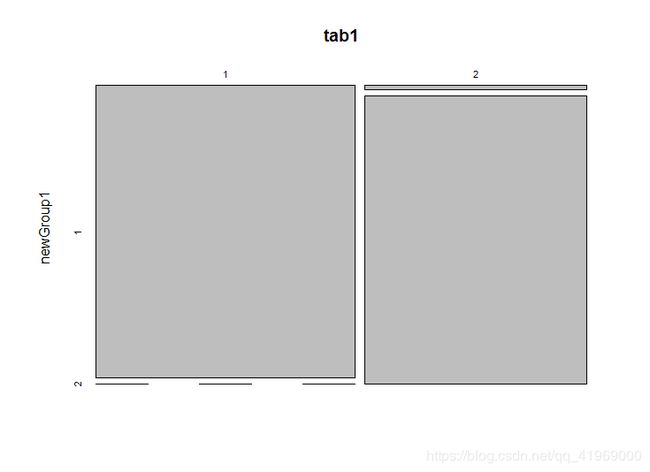
tab1 <- table(mydata$Group , newGroup1) #绘制混淆矩阵
tab1
erro1 <- 1-sum(diag(prop.table(tab1))) #计算误判率
erro1
plot(tab1) #可视化
> tab
newGroup
1 2
1 137 21
2 27 109
> erro
[1] 0.1632653
> tab1
newGroup1
1 2
1 158 0
2 2 134
> erro1
[1] 0.006802721 #显然考虑的因素多了,判断率正确率明显提高

6.给定数字进行判别分类
predict(sexyLd , newdata = data.frame(height = 171 , weight = 50)) #预测1
predict(sexyLd1 , newdata = data.frame(height = 168, weight = 60 , Vital.capacity = 3500 , sprint = 7.1 ,
Endurance.running = 4.20 , Sitting.body.flexion = 10.3, jump = 2.29, Sit.ups = 25 , point = 80)) #预测2
> predict(sexyLd , newdata = data.frame(height = 171 , weight = 50)) #预测1
$class
[1] 2
> predict(sexyLd1 , newdata = data.frame(height = 168, weight = 60 , Vital.capacity = 3500 , sprint = 7.1 ,
Endurance.running = 4.20 , Sitting.body.flexion = 10.3, jump = 2.29, Sit.ups = 25 , point = 80))
$class
[1] 1
# 1代表女性 2代表男性
`