网络爬虫简单实例复习
文章目录
- 初级爬虫
- 1 获取网页简单信息
- 2 从黄页中提取某单位的电话号码以及邮箱
- 3 出版社信息写入文件中
- 4 爬取新浪新闻首页部分新闻的内容,并存储至本地
- 中级爬虫
- 5 亚马逊商品生成本地网页存储到本地中
- 6 糗事百科段子
- 7亚马逊图片
- 8 腾讯视频评论
- 10 模拟http请求get和post
- 11 五个例子¶
- 12 中国大学排名
- 13 豆瓣电影top250
初级爬虫
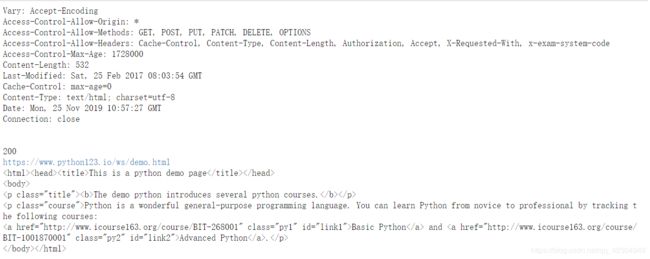
1 获取网页简单信息
import urllib
web=urllib.request.urlopen('https://www.python123.io/ws/demo.html')
print(web.info())
print(web.getcode())
print(web.geturl())
data=web.read().decode()
print(data)
2 从黄页中提取某单位的电话号码以及邮箱
网页源码
<ul>
<li>联系人:李丽li>
<li title="0351-6999992">电话:0351-6999992li>
<li title="[email protected]">邮件:[email protected]li>
<li title="15635361929">手机:15635361929li>
<li title="0351-6999991">传真:0351-6999991li>
<li>地址:山西省太原市杏花岭区府西街54号li>
ul>
程序
import urllib
import re
web = urllib.request.urlopen('http://tykdyy66.chn0769.com')
data = web.read().decode('gbk')
#print(data[:200])
pat = 'title="(\d.*)">'
rst = re.compile(pat).findall(data)
print(rst)
结果
['0351-6999992', '[email protected]', '15635361929', '0351-6999991']
3 出版社信息写入文件中

import re
import urllib
data=urllib.request.urlopen("https://read.douban.com/provider/all").read()
data=data.decode("utf-8") #注意对汉字要进行编码
pat='(.*?)' #匹配出版社名称
#pat='(.*?)' #匹配出版社作品数量
mydata=re.compile(pat).findall(data)
#得到一个数组mydata:['博集天卷', '北京邮电大学出版社',........]
fh=open(r"D:\spider\test\豆瓣阅读.txt","w")
for i in range(0,len(mydata)):
fh.write(mydata[i]+"\n")
fh.close()
4 爬取新浪新闻首页部分新闻的内容,并存储至本地
其中一个新闻首页链接源码
<a target="_blank" href="https://news.sina.com.cn/gov/xlxw/2019-11-
20/doc-iihnzahi2070388.shtml">6张海报读懂习式外交中的中国智慧a>
程序
import urllib.request
import re
import urllib.error
# 第一步:先爬首页
url = 'https://news.sina.com.cn/'
web = urllib.request.urlopen(url)
data = web.read().decode('utf-8','ignore') #ignore表示即使编码错误我们也不用管它
# 第二步:通过正则获取所有新闻链接
pat = '
alllink = re.compile(pat).findall(data)
print(alllink)
print(len(alllink))
# 第三步:依次爬各新闻,并存储到本地
loadpath = './sina_news/'
for i in range(0,len(alllink)):
try:
thisurl = alllink[i]
thispage = urllib.request.urlopen(thisurl).read().decode('utf-8','ignore')
urllib.request.urlretrieve(thisurl,loadpath+str(i)+'.html')
except urllib.error.URLError as err:
print(i)
if hasattr(err,'code'):
print(err.code)
if hasattr(err,'reason'):
print(err.reason)
中级爬虫
5 亚马逊商品生成本地网页存储到本地中
import urllib.request
import re
import urllib.error
#第一步:伪装浏览器访问
url = 'https://www.amazon.cn/s?k=phone'
header = ('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko\
) Chrome/76.0.3809.132 Safari/537.36')
opener = urllib.request.build_opener() # 实例化成opener这个对象
opener.addheaders = [header] # 在opener这个对象中添加头信息
# 将其安装为全局,此时即可用urlopen进行爬取
urllib.request.install_opener(opener)
data = urllib.request.urlopen(url).read().decode('utf-8','ignore') # 首页数据
loadpath = './data.html'
urllib.request.urlretrieve(url,loadpath)
#print(data[:200])
# 第二步:提取商品链接
pat =''
re.compile(pat).findall(data)
alllink = re.compile(pat).findall(data)
print(alllink)
print(len(alllink))
# 第三步:输出
for i in range(0,len(alllink)):
try:
loadpath = './yamaxunlink/'+str(i)+'.html'
thislink = alllink[i]
urllib.request.urlretrieve('https://www.amazon.cn/'+thislink,loadpath) #urlretrieve()函数,\将互联网上的东西批量下载到本地,这种出乱码
print('当前商品(第'+str(i)+'件)爬取成功!')
except urllib.error.URLError as err:
print('当前商品(第'+str(i)+'件)爬取失败!')
if hasattr(err,'code'): # 判断状态码属性
print(err.code)
6 糗事百科段子
import re
import random
import urllib.request as urlreq
import urllib.error as urlerr
uapools = [
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
]
def get_ua(uapools):
thisua = random.choice(uapools)
print(thisua,'\n')
header = ("User-Agent", thisua)
url_opener = urlreq.build_opener()
url_opener.addheaders = [header]
urlreq.install_opener(url_opener)
def get_article(data):
#pat = '.*?(.*?).*?'
pat1 ='target="_blank">(.*?)'; pat2 = '(.*?)
'
rst1 = re.compile(pat1,re.S).findall(data); rst2=re.compile(pat2,re.S).findall(data)
print(rst1,'\n',rst2,'\n','='*50)
#写入文件
with open('糗事百科段子.txt','w',encoding='utf-8') as f:
for title,content in zip(rst1,rst2):
f.write(title+'\n'+content+'\n'+'='*50+'\n')
def get_html(urlweb):
for i in range(1, 6): #爬取前五页文章
try:
print('\n第'+str(i)+'页标题和文章列表:\n')
page = urlweb + str(i)
get_ua(uapools)
data = urlreq.urlopen(page).read().decode("gbk","ignore")
get_article(data) #解析文章
except Exception as e:
print(e,'xz')
uapools.remove(thisua) #爬取失败时,从IP池中删除IP,重新爬取文章
if __name__ == "__main__":
urlweb = "http://www.lovehhy.net/Joke/Detail/QSBK/"
get_html(urlweb)
前三条结果
我想你了怎么办
外甥小的时候问他姥姥以后你死了怎么办啊?我想你了怎么办?他姥姥还没来得及感动就见他恍然大悟:我把坟扒开看看你再把你埋上[捂脸]
==================================================
老规矩割一下
别人是帮别人开面包车送货的,(老规矩割一下)由于面包车比较老旧排气管声音比较大,今天下午去送货时在一个路上开到一个目测20岁左右的男的边看手机边过马路(此处并没有斑马线)我减速按喇叭结果他没反应,火大了离合器油门一起踩下,那声音比跑车还大,这下那家伙那一下以比刘翔还快的速度跳的路边,让你走路玩手机,吓死你…
==================================================
一股泥石流直接爆后闸
内急,皮带坏了,解半天,直接扯断,一股泥石流直接爆后闸,激射到墙上,实在太羞耻了,赶紧跑出洗手间去洗手。
==================================================
7亚马逊图片
import urllib.request
import re
# 第一步:分析网页,构造url
good = '内存条'
# print(urllib.request.quote(good))
# url = 'https://s.taobao.com/search?q='+urllib.request.quote(good)+'&s=' #最简网址
url = 'https://www.amazon.cn/s?k='+urllib.request.quote(good)+'&ref=sr_pg_'
# 第二步:构建用户代理池
uapools = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media \
Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"
]
# 第三步:构建用户代理池函数
import random
def ua(uapools):
thisua = random.choice(uapools) # choice()函数:返回一个列表、元组或字符串的随机项
print(thisua)
# 修改头信息
headers = ('User-Agent',thisua)
opener = urllib.request.build_opener() # 实例化成opener这个对象
opener.addheaders = [headers]
urllib.request.install_opener(opener) # 安装为全局,此时即可用urlopen进行爬取
# 第四步,正则分析,提取图片
loadpath = './亚马逊商品图片/'
for i in range(1,3):
try:
ua(uapools)
# thisurl = url + str(44 * i) # 淘宝
thisurl = url + str( i) # 亚马逊
data = urllib.request.urlopen(thisurl).read().decode('utf-8','ignore')
urllib.request.urlretrieve(thisurl, loadpath+'data' + str(i) + '.html')
# print(data)
# pat = '"pic_url":"(.*?)"'
pat = ' ML3_.jpg) rst = re.compile(pat).findall(data) #获得图片网址列表
#print(rst)
print(len(rst))
for j in range(0,len(rst)):
thisimg = rst[j]
thisimgurl = thisimg+'ML3_.jpg' #构造图片网址
localfile = loadpath +str(i)+'_'+str(j)+ '.jpg' # 存储文件名
try:
urllib.request.urlretrieve(thisimgurl,localfile)
print('当前图片(第' + str(i)+'_'+str(j)+'张)爬取成功!',end='\t')
if((j+1)%4==0): print()
except Exception as err:
print('当前图片(第' + str(i)+'_'+str(j)+ '张)爬取失败!',end='\t')
if((j+1)%4==0): print()
print(err)
print('\n亚马逊(第' + str(i) + '页)爬取成功!')
except Exception as err :
print('\n亚马逊(第' + str(i) + '页)爬取失败!')
print(err)
rst = re.compile(pat).findall(data) #获得图片网址列表
#print(rst)
print(len(rst))
for j in range(0,len(rst)):
thisimg = rst[j]
thisimgurl = thisimg+'ML3_.jpg' #构造图片网址
localfile = loadpath +str(i)+'_'+str(j)+ '.jpg' # 存储文件名
try:
urllib.request.urlretrieve(thisimgurl,localfile)
print('当前图片(第' + str(i)+'_'+str(j)+'张)爬取成功!',end='\t')
if((j+1)%4==0): print()
except Exception as err:
print('当前图片(第' + str(i)+'_'+str(j)+ '张)爬取失败!',end='\t')
if((j+1)%4==0): print()
print(err)
print('\n亚马逊(第' + str(i) + '页)爬取成功!')
except Exception as err :
print('\n亚马逊(第' + str(i) + '页)爬取失败!')
print(err)

8 腾讯视频评论
参考:
python爬虫学习笔记(一)—— 爬取腾讯视频影评
腾讯视频评论爬虫实战
10 模拟http请求get和post
get 和 post请求的区别:
Get:请求的url会附带查询参数
Post:请求的url不带参数
对于Get请求:查询参数在QueryString里保存
对于Post请求:查询参数在From表单里保存
Get和Post请求的区别(爬虫)
11 五个例子¶
- requests库简单使用(JD商品)
import requests as req
#example1 京东商品爬虫
url='https://item.jd.com/100004050001.html'
try:
r=req.get(url,timeout=30)
r.raise_for_status() #!200 HTTPError
r.encoding=r.apparent_encoding #全局赋给局部
print(len(r.text))
print(r.text[:1000])
except:
print('爬取异常')
- 添加头部 headers
#example2 amazon r.request.headers
import requests
url = "https://www.amazon.cn/dp/B0785D5L1H/ref=sr_1_1?__mk_zh_CN"
r = requests.get(url, timeout=30)
r.encoding = r.apparent_encoding
print(r.request.headers)
try:
kv = {'User-Agent': 'Mozilla/5.0'}
r = requests.get(url, headers = kv, timeout=30)
r.raise_for_status() # 如果状态码不是200,引发一个HTTPError异常
r.encoding = r.apparent_encoding
print(r.request.headers,'=='*60)
print(r.text[1000:2000])
except:
print('爬取失败')
- params
#example3 baidu.com so.com
url = 'http://www.baidu.com/'
params = {'wd': 'python'} # 也可以将携带的参数传给params
r = req.get(url, params=params)
print(r.url,r.request.headers)
url = 'https://www.so.com'
params = {
'q': 'sdog'
}
r = req.get(url, params=params)
#print(r.text)
print(r.url,r.request.headers)
结果
https://www.baidu.com/?wd=python{'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
https://www.so.com/?q=sdog {'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
- 存图片
#examp4 存图片
import urllib
import requests as req
url ="http://pic1.win4000.com/wallpaper/6/51e35bd76cd74.jpg"
file_name=url.split("/")[-1]
try:
r=req.get(url,timeout=30)
r.raise_for_status() #!200 HTTPError
r.encoding=r.apparent_encoding #全局赋给局部
print(len(r.text))
#print(r.text[:1000])
except Exception as e:
print('爬取异常:',e)
import urllib
urllib.request.urlretrieve(url,r'./pictures/'+file_name)
with open('./pictures/'+file_name,'wb+') as f:
f.write(r.content)

5. IP地址归属地的自动查询
import requests
from bs4 import BeautifulSoup
url = "http://m.ip138.com/ip.asp?ip="
ip='192.165.76.88' #要查询的ip
try:
r = requests.get(url + ip)
r.raise_for_status()
r.encoding = r.apparent_encoding
soup=BeautifulSoup(r.text)
#print(r.text)
res=soup.find_all('p',class_="result")
print(ip+' 归属地: ',res[0].string[6:])
except Exception as e:
print('爬取失败: ',e)
# 输出: 192.165.76.88 归属地: 瑞典
12 中国大学排名
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
def fillUnivList(uList,html):
soup = BeautifulSoup(html,"html.parser")
#print(soup.find('tbody'))
for tr in soup.find('tbody').children: #遍历soup中的tbody部分的子标签中的所有的tr类型标签
if isinstance(tr, bs4.element.Tag): #排除tr标签中非标签类型的其他信息(有的tr可能是字符串)
tds = tr('td') #tr.find_all('td')的合法简写形式,要记住
uList.append([tds[0].string,tds[1].string,tds[2].string]) #二维数组格式存储数据
def printUnivList(uList,num):#num指代显示前多少个大学的信息
print ("{:^10}\t{:^6}\t{:^10}".format("排名","大学名称","所在地")) #format函数,格式化输出,需要进一步掌握
for i in range(num):
u = uList[i]
print ("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
#print(u[0])
def main():
uInfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html"
html = getHTMLText(url)
fillUnivList(uInfo,html)
printUnivList(uInfo,5)
main()

13 豆瓣电影top250

def get_movies2():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0,10):
link = 'https://movie.douban.com/top250?start=' + str(i * 25)
r = requests.get(link, headers=headers, timeout= 10)
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_='info')
for each in div_list:
title = each.find('div', class_='hd').a.span.text.strip()
info = each.find('div', class_='bd').p.text.strip()
info = info.replace("\n", " ").replace("\xa0", " ")
info = ' '.join(info.split())
rating = each.find('span', class_='rating_num').text.strip()
num_rating = each.find('div', class_='star').contents[7].text.strip()
try:
quote = each.find('span', class_='inq').text.strip()
except:
quote = ""
movie_list.append([title, info, rating, num_rating, quote])
return movie_list
movies=get_movies2()
for i in range(len(movies)):
print('='*90,'\n',movies[i],'\n')
其中前三条内容入下:
==========================================================================================
['肖申克的救赎', '导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /... 1994 / 美国 / 犯罪 剧情', '9.7', '1690184人评价', '希望让人自由。']
==========================================================================================
['霸王别姬', '导演: 陈凯歌 Kaige Chen 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha... 1993 / 中国大陆 中国香港 / 剧情 爱情 同性', '9.6', '1250003人评价', '风华绝代。']
==========================================================================================
['阿甘正传', '导演: 罗伯特·泽米吉斯 Robert Zemeckis 主演: 汤姆·汉克斯 Tom Hanks / ... 1994 / 美国 / 剧情 爱情', '9.5', '1307186人评价', '一部美国近现代史。']
最近申请了个公众号,定期更新大数据,python爬虫相关内容,欢迎关注ღ( ´・ᴗ・` )比心。
