HBase底层的IO行为
HBase 底层的IO行为
目录
1 、Flush的工作原理
2 、Compaction的原理
3 、Region的split工作原理
4、 WAL的原理
1 、Flush的工作原理
Flush的触发条件:
1.(hbase.regionserver.global.memstore.size)默认;堆大小的40%
regionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写
2.(hbase.hregion.memstore.flush.size)默认:128M
单个region里memstore的缓存大小,超过那么整个HRegion就会flush,
3.(hbase.regionserver.optionalcacheflushinterval)默认:1h
内存中的文件在自动刷新之前能够存活的最长时间
4.(hbase.regionserver.global.memstore.size.lower.limit)默认:堆大小 * 0.4 * 0.95
有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小, 这个大小就是默认值是堆大小 * 0.4 * 0.95,也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为 堆大小 * 0.4 *0.95为止
5.(hbase.hregion.preclose.flush.size)默认为:5M
当一个 region 中的 memstore 的大小大于这个值的时候,我们又触发 了 close.会先运行“pre-flush”操作,清理这个需要关闭的memstore,然后 将这个 region 下线。当一个 region 下线了,我们无法再进行任何写操作。 如果一个 memstore 很大的时候,flush 操作会消耗很多时间。"pre-flush" 操作意味着在 region 下线之前,会先把 memstore 清空。这样在最终执行 close 操作的时候,flush 操作会很快。
6.(hbase.hstore.compactionThreshold)默认:超过3个
一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当超过3个hfile的时候就会 对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长.
Flush 情况分为以下几种:
【1、Memstore级别】
Memstore大小达到上限(hbase.hregion.memstore.flush.size,memsotre默认大小128M)时,会触发memstore flush
【2、Region级别】
当一个region中所有memstore大小总和达到了上限(hbase.hregion.memstore.block.multiplier*hbase.hregion.memstore.flush.size,默认2*128M=256M),会触发memstore flush
有一种场景是hbase在写入数据发生阻塞,原因就是这种情况,region server会在写入时检查每个region中的memstore总大小是否超过了单个memstore默认大小的2倍(hbase.hregion.memstore.block.multiplier参数决定),如果超过了则会阻塞写操作,避免产生OOM。由于在flush时还会由compact/split等操作同时进行,因此整个flush过程会比较漫长,必须要等待memstore完全flush到磁盘才会结束,默认regionserver会睡眠hbase.server.thread.wakefrequency(默认10s),再检查memstore大小是不是低于阈值。
生产环境是难以接受10s的等待时间的,因此在无法改变flush过程的时候,可以通过调整如下两个参数来避免或减少region级别的flush。
hbase.hregion.memstore.block.multiplier=10(默认是2,当节点内存充足时可调大此值)
habse.server.thread.wakefrequency=100(默认时10000ms)
【3、Region Server级别】
一个regionserver上会有很多region,意味着大量的memstore,很有可能单个region并没有超过阈值,但regionserver整体的内存占用达到阈值。
当一个region server上所有region中memstore的大小总和达到了head内存的低水位上限(hbase.regionserver.global.memstore.lowerlimit*hbase_heapsize,heap内存的低水位线,默认0.35),会触发部分memstore的flush,flush顺序是按照memstore由大到小执行,先执行memstore最大region的flush操作,再执行次大的,循环执行直到总体memstore内存使用量低于heap*0.35,以降低阻塞全部写操作flush带来的影响;
而当一个region server上所有region中memstore的大小总和达到了heap内存的上限(hbase.regionserver.global.memstore.upperlimit*hbase_heapsize,heap内存的高水位线,默认0.4),会阻塞所有的写操作,将所有memstore都进行flush。
【4、WAL数量达到上限,region级别】
设计这个触发条件的初衷是为了在region server宕掉时,通过WAL恢复的时间不要太久。
WAL的最大值由hbase.regionserver.hlog.blocksize*hbase.regionserver.maxlogs决定。一旦达到这个值,memstroe flush就会被触发。
WAL数量触发的flush策略是找到最早的un-archived WAL文件,将其对应的Region进行flush。
值得一提的是,blocksize (128 mb) * hbase.regionserver.maxlogs大小与hbase.regionserver.global.memstore.upperLimit * HBASE_HEAPSIZE两者之间谁大谁小,个人觉得前者应小于后者,因为若大于后者的话,将会优先做region server级别的flush,阻塞所有写操作,而这个阻塞往往是分钟级别。但cloudera给出的建议是前者大小应略大于后者,以保证不会提前发生flush,这点有待商榷。
【5、定期自动flush】
Region Server在启动时会启动一个线程PeriodicMemStoreFlusher,该线程每隔habse.server.thread.wakefrequency(默认10s)会检查该regeion Server的全部在线Region,当满足以下条件将会触发flush:
memstore中最老记录的时间戳与当前时间的时间间隔超过配置值hbase.regionserver.optionalcacheflushinterval(默认1小时),如果是meta表的region则为5分钟。
如果该参数为0,即为关闭自动刷写。同时,为了避免同时提交的flush太多,会有3~23秒的随机延迟。
【6、数据更新达到阈值】
同样由PeriodicMemStoreFlusher探测,当最后一次flush后的变更次数超过hbase.regionserver.flush.per.changes(默认3千万),也会触发flush。
【7、手工flush】
在hbase shell中调用flush,可以对某张表或某个region进行flush:
flush 'tablename'或flush 'region name'
Flush流程:
prepare阶段:遍历当前Region中的所有Memstore,将Memstore中当前数据集kvset做一个快照snapshot,然后再新建一个新的kvset。后期的所有写入操作都会写入新的kvset中,而整个flush阶段读操作会首先分别遍历kvset和snapshot,如果查找不到再会到HFile中查找。prepare阶段需要加一把updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
flush阶段:遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时。
commit阶段:遍历所有的Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。
2 、Compaction的原理
(使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟)
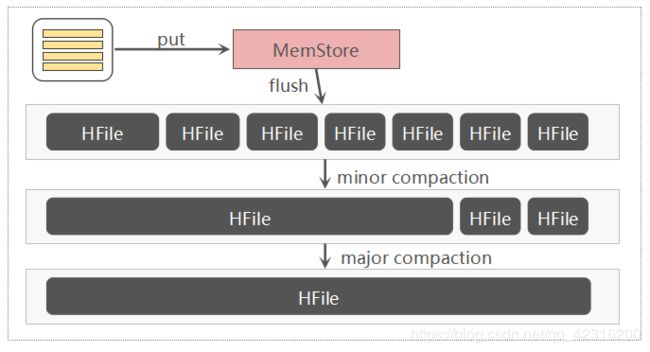
HBase是基于一种LSM-Tree(Log-Structured Merge Tree)存储模型设计的,写入路径上是先写入WAL(Write-Ahead-Log)即预写日志,再写入memstore缓存,满足一定条件后执行flush操作将缓存数据刷写到磁盘,生成一个HFile数据文件。随着数据不断写入,磁盘HFile文件就会越来越多,文件太多会影响HBase查询性能,主要体现在查询数据的io次数增加。为了优化查询性能,HBase会合并小的HFile以减少文件数量,这种合并HFile的操作称为Compaction,这也是为什么要进行Compaction的主要原因。
Compaction会从一个region的一个store中选择一些hfile文件进行合并。合并说来原理很简单,先从这些待合并的数据文件中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这个新生成的文件就会取代之前待合并的所有文件对外提供服务。HBase根据合并规模将Compaction分为了两类:MinorCompaction和MajorCompaction
- Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。
- Major Compaction是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
Compaction的作用:
1)合并文件
2)清除删除、过期、多余版本的数据
3)提高读写数据的效率
Compaction流程:
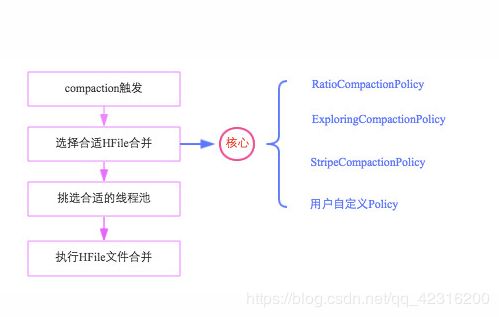
整个Compaction始于特定的触发条件,比如flush操作、周期性地Compaction检查操作等。一旦触发,HBase会将该Compaction交由一个独立的线程处理,该线程首先会从对应store中选择合适的hfile文件进行合并,这一步是整个Compaction的核心,选取文件需要遵循很多条件,比如文件数不能太多、不能太少、文件大小不能太大等等,最理想的情况是,选取那些承载IO负载重、文件小的文件集,实际实现中,HBase提供了多个文件选取算法:RatioBasedCompactionPolicy、ExploringCompactionPolicy和StripeCompactionPolicy等,用户也可以通过特定接口实现自己的Compaction算法;选出待合并的文件后,HBase会根据这些hfile文件总大小挑选对应的线程池处理,最后对这些文件执行具体的合并操作。

Major Compaction 参数
Major Compaction涉及的参数比较少,主要有大合并时间间隔与一个抖动参数因子,如下:
1.hbase.hregion.majorcompaction
Major compaction周期性时间间隔,默认值604800000,单位ms。表示major compaction默认7天调度一次,HBase 0.96.x及之前默认为1天调度一次。设置为 0 时表示禁用自动触发major compaction。需要强调的是一般major compaction持续时间较长、系统资源消耗较大,对上层业务也有比较大的影响,一般生产环境下为了避免影响读写请求,会禁用自动触发major compaction。
2.hbase.hregion.majorcompaction.jitter
Major compaction抖动参数,默认值0.5。这个参数是为了避免major compaction同时在各个regionserver上同时发生,避免此操作给集群带来很大压力。 这样节点major compaction就会在 + 或 - 两者乘积的时间范围内随机发生。
Minor Compaction 参数
Minor compaction涉及的参数比major compaction要多,各个参数的目标是为了选择合适的HFile,具体参数如下:
1.hbase.hstore.compaction.min
一次minor compaction最少合并的HFile数量,默认值 3。表示至少有3个符合条件的HFile,minor compaction才会启动。一般情况下不建议调整该参数。
如果要调整,不建议调小该参数,这样会带来更频繁的压缩,调大该参数的同时其他相关参数也应该做调整。早期参数名称为 hbase.hstore.compactionthreshold。
2.hbase.hstore.compaction.max
一次minor compaction最多合并的HFile数量,默认值 10。这个参数也是控制着一次压缩的时间。一般情况下不建议调整该参数。调大该值意味着一次compaction将会合并更多的HFile,压缩时间将会延长。
3.hbase.hstore.compaction.min.size
文件大小 < 该参数值的HFile一定是适合进行minor compaction文件,默认值 128M(memstore flush size)。意味着小于该大小的HFile将会自动加入(automatic include)压缩队列。一般情况下不建议调整该参数。
但是,在write-heavy就是写压力非常大的场景,可能需要微调该参数、减小参数值,假如每次memstore大小达到1~2M时就会flush生成HFile,此时生成的每个HFile都会加入压缩队列,而且压缩生成的HFile仍然可能小于该配置值会再次加入压缩队列,这样将会导致压缩队列持续很长。
4.hbase.hstore.compaction.max.size
文件大小 > 该参数值的HFile将会被排除,不会加入minor compaction,默认值Long.MAX_VALUE,表示没有什么限制。一般情况下也不建议调整该参数。
5.hbase.hstore.compaction.ratio
这个ratio参数的作用是判断文件大小 > hbase.hstore.compaction.min.size的HFile是否也是适合进行minor compaction的,默认值1.2。更大的值将压缩产生更大的HFile,建议取值范围在1.0~1.4之间。大多数场景下也不建议调整该参数。
6.hbase.hstore.compaction.ratio.offpeak
此参数与compaction ratio参数含义相同,是在原有文件选择策略基础上增加了一个非高峰期的ratio控制,默认值5.0。这个参数受另外两个参数 hbase.offpeak.start.hour 与 hbase.offpeak.end.hour 控制,这两个参数值为[0, 23]的整数,用于定义非高峰期时间段,默认值均为-1表示禁用非高峰期ratio设置。
触发时机
HBase中可以触发compaction的因素有很多,最常见的因素有这么三种:Memstore Flush、后台线程周期性检查、手动触发。
1. Memstore Flush: 应该说compaction操作的源头就来自flush操作,memstore flush会产生HFile文件,文件越来越多就需要compact。因此在每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦文件数# > ,就会触发compaction。需要说明的是,compaction都是以Store为单位进行的,而在Flush触发条件下,整个Region的所有Store都会执行compact,所以会在短时间内执行多次compaction。
2. 后台线程周期性检查:后台线程CompactionChecker定期触发检查是否需要执行compaction,检查周期为:hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier。和flush不同的是,该线程优先检查文件数#是否大于,一旦大于就会触发compaction。如果不满足,它会接着检查是否满足major compaction条件,简单来说,如果当前store中hfile的最早更新时间早于某个值mcTime,就会触发major compaction,HBase预想通过这种机制定期删除过期数据。上文mcTime是一个浮动值,浮动区间默认为[7-7*0.2,7+7*0.2],其中7为hbase.hregion.majorcompaction,0.2为hbase.hregion.majorcompaction.jitter,可见默认在7天左右就会执行一次major compaction。用户如果想禁用major compaction,只需要将参数hbase.hregion.majorcompaction设为0
3. 手动触发:一般来讲,手动触发compaction通常是为了执行major compaction,原因有三,其一是因为很多业务担心自动major compaction影响读写性能,因此会选择低峰期手动触发;其二也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发major compaction;其三是HBase管理员发现硬盘容量不够的情况下手动触发major compaction删除大量过期数据;无论哪种触发动机,一旦手动触发,HBase会不做很多自动化检查,直接执行合并。
选择合适HFile合并
选择合适的文件进行合并是整个compaction的核心,因为合并文件的大小以及其当前承载的IO数直接决定了compaction的效果。最理想的情况是,这些文件承载了大量IO请求但是大小很小,这样compaction本身不会消耗太多IO,而且合并完成之后对读的性能会有显著提升。然而现实情况可能大部分都不会是这样,在0.96版本和0.98版本,分别提出了两种选择策略,在充分考虑整体情况的基础上选择最佳方案。无论哪种选择策略,都会首先对该Store中所有HFile进行一一排查,排除不满足条件的部分文件:
1. 排除当前正在执行compact的文件及其比这些文件更新的所有文件(SequenceId更大)
2. 排除某些过大的单个文件,如果文件大小大于hbase.hzstore.compaction.max.size(默认Long最大值),则被排除,否则会产生大量IO消耗
经过排除的文件称为候选文件,HBase接下来会再判断是否满足major compaction条件,如果满足,就会选择全部文件进行合并。判断条件有下面三条,只要满足其中一条就会执行major compaction:
1. 用户强制执行major compaction
2. 长时间没有进行compact(CompactionChecker的判断条件2)且候选文件数小于hbase.hstore.compaction.max(默认10)
3. Store中含有Reference文件,Reference文件是split region产生的临时文件,只是简单的引用文件,一般必须在compact过程中删除
3 、Region的split工作原理
一个Region代表一个表的一段Rowkey的数据集合,当Region太大,Master会将其拆分。Region太大会导致读取效率太低,遍历时间太长,通过将大数据拆分到不同机器上,分别查询再聚合,Hbase也被人称为“一个会自动分片的数据库”。Region可以手动和自动拆分。

-
ConstantSizeRegionSplitPolicy:0.94版本前默认切分策略。这是最容易理解但也最容易产生误解的切分策略,从字面意思来看,当region大小大于某个阈值(hbase.hregion.max.filesize)之后就会触发切分,实际上并不是这样,真正实现中这个阈值是对于某个store来说的,即一个region中最大store的大小大于设置阈值之后才会触发切分。另外一个大家比较关心的问题是这里所说的store大小是压缩后的文件总大小还是未压缩文件总大小,实际实现中store大小为压缩后的文件大小(采用压缩的场景)。ConstantSizeRegionSplitPolicy相对来来说最容易想到,但是在生产线上这种切分策略却有相当大的弊 端:切分策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
-
IncreasingToUpperBoundRegionSplitPolicy: 0.94版本~2.0版本默认切分策略。这种切分策略微微有些复杂,总体来看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大store大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系 :(#regions) * (#regions) * (#regions) * flush size * 2,当然阈值并不会无限增大, 最大值为用户设置的MaxRegionFileSize。这种切分策略很好的弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表。而且在大集群条件下对于很多大表来说表现很优秀,但并不完美,这种策略下很多小表会在大集群中产生大量小region,分散在整个集群中。而且在发生region迁移时也可能会触发region分裂。
-
SteppingSplitPolicy: 2.0版本默认切分策略。这种切分策略的切分阈值又发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,依然和待分裂region所属表在当前regionserver上的region个 数有关系,如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小region,而是适可而止。
另外, 还有一些其他分裂策略, 比如使用DisableSplitPolicy: 可以禁止region 发生分裂; 而KeyPrefixRegionSplitPolicy ,DelimitedKeyPrefixRegionSplitPolicy 对 于 切 分 策 略 依 然 依 据 默 认 切 分 策 略 , 但 对 于 切 分 点 有 自 己 的 看 法 , 比 如KeyPrefixRegionSplitPolicy要求必须让相同的PrefixKey待在一个region中。
HBase将整个切分过程包装成了一个事务,意图能够保证切分事务的原子性。整个分裂事务过程分为三个阶段:prepare – execute– (rollback);
-
prepare阶段:在内存中初始化两个子region,具体是生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录切分的进展,具体见rollback阶段。
-
execute阶段:切分的核心操作。见下图:
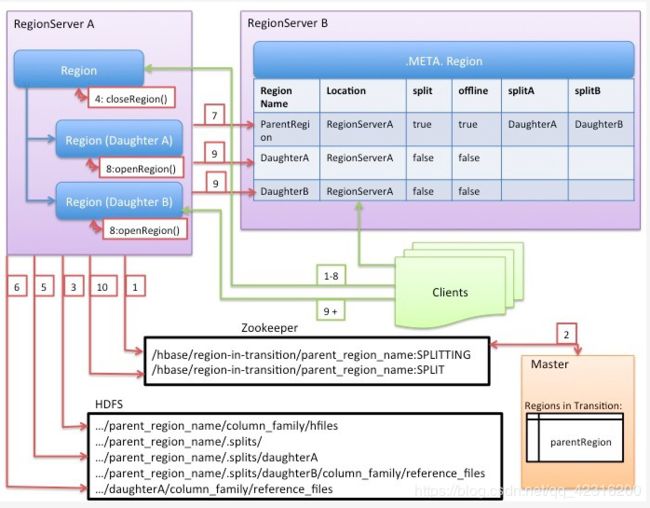
1. regionserver 更改ZK节点 /region-in-transition 中该region的状态为SPLITING。
2. master通过watch节点/region-in-transition检测到region状态改变,并修改内存中region的状态,在master页面RIT模块就可以看到region执行split的状态信息。
3.在父存储目录下新建临时文件夹,split保存split后的daughter region信息。
4.关闭parent region:parent region 关闭数据写入并触发flush操作,将写入region的数据全部持久化到磁盘,此后短时间内客户端落在父region上的请求都会抛出异常NotServingRegionException。
5. 核心分裂步骤:在.split文件夹下新建两个子文件夹,称之为daughter A、daughter B,并在文件夹中生成reference文件, 分别指向父region中对应文件。这个步骤是所有步骤中最核心的一个环节,生成reference文件日志如下所示: 2017-08-12 11:53:38,158 DEBUG [StoreOpene-0155388346c3c919d3f05d7188e885e0-1] regionserver.StoreFileInfo: reference'hdfs://hdfscluster/hbase-rsgroup/data/default/music/0155388346c3c919d3f05d7188e885e0/cf/d24415c4fb44427b8f698143e5c4d9dc00 其中reference文件名为d24415c4fb44427b8f698143e5c4d9dc.00bb6239169411e4d0ecb6ddfdbacf66,格式看起来比较特殊,那这种文件名具体什么含义呢?那来看看该reference文件指向的父region文件,根据日志可以看到,切分的父region是00bb6239169411e4d0ecb6ddfdbacf66,对应的切分文件是d24415c4fb44427b8f698143e5c4d9dc,可见reference文件名是个信息量很大的命名方式,如下所示:

除此之外,还需要关注reference文件的文件内容,reference文件是一个引用文件(并非linux链接文件),文件内容很显然不是用户数据。文件内容其实非常简单, 主要有两部分构成: 其一是切分点splitkey, 其二是一个boolean类型的变量( true 或者false),true表示该reference文件引用的是父文件的上半部分(top),而false表示引用的是下半部分 (bottom)。为什么存储的是这两部分内容?且听下文分解。
看官可以使用hadoop命令亲自来查看reference文件的具体内容: hadoopdfs-cat/hbase-rsgroup/data/default/music/0155388346c3c919d3f05d7188e885e0/cf/d24415c4fb44427b8f698 6. 父region分裂为两个子region后,将daughter A、daughter B拷贝到HBase根目录下,形成两个新的region。
7. parent region通知修改 hbase.meta 表后下线,不再提供服务。下线后parent region在meta表中的信息并不会马上删除, 而是标注split列、offline列为true,并记录两个子region。为什么不立马删除?且听下文分解。

8. 开启daughter A、daughter B两个子region。通知修改 hbase.meta 表,正式对外提供服务。


- rollback阶段:如果execute阶段出现异常,则执行rollback操作。为了实现回滚,整个切分过程被分为很多子阶段,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。代码中使用 JournalEntryType 来表征各个子阶段,

4、 WAL的原理
WAL(Write-Ahead-Log)预写日志是Hbase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。在每次Put、Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文件中去。
客户端向RegionServer端提交数据的时候,会先写入WAL日志,只有当WAL日志写入成功的时候,客户端才会被告诉提交数据成功。如果写WAL失败会告知客户端提交失败,这其实就是数据落地的过程。
在一个RegionServer上的所有Region都共享一个HLog,一次数据的提交先写入WAL,写入成功后,再写入menstore之中。当menstore的值达到一定的时候,就会形成一个个StoreFile。
WAL的持久化的级别有如下几种:
SKIP_WAL:不写wal日志,这种可以较大提高写入的性能,但是会存在数据丢失的危险,只有在大批量写入的时候才使用(出错了可以重新运行),其他情况不建议使用。
ASYNC_WAL:异步写入
SYNC_WAL:同步写入wal日志文件,保证数据写入了DataNode节点。
FSYNC_WAL: 目前不支持了,表现是与SYNC_WAL是一致的
USE_DEFAULT: 如果没有指定持久化级别,则默认为USE_DEFAULT, 这个为使用Hbase全局默认级别(SYNC_WAL)wal写入
先看看wal写入中的几个主要的类
1. WALKey:wal日志的key,包括regionName:日志所属的region
tablename:日志所属的表,writeTime:日志写入时间,clusterIds:cluster的id,在数据复制的时候会用到。
2.WALEdit:在Hbase的事务日志中记录一系列的修改的一条事务日志。另外WALEdit实现了Writable接口,可用于序列化处理。
3. FSHLog: WAL的实现类,负责将数据写入文件系统
在每个wal的写入这里使用的是多生产者单消费者的模式,这里使用到了disruptor框架,将WALKey和WALEdit信息封装为FSWALEntry,然后通过RingBufferTruck放入RingBuffer中。接下来看hlog的写入流程,分为以下3步:
日志写入缓存:由rpcHandler将日志信息写入缓存ringBuffer.
缓存数据写入文件系统:每个FSHLog有一个线程负责将数据写入文件系统(HDFS)
数据同步:如果操作的持久化级别为(SYNC_WAL或者USE_DEFAULT 则需进行数据同步处理
客户端往RegionServer端提交数据的时候,会写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败,换句话说这其实是一个数据落地的过程。在一个RegionServer上的所有的Region都共享一个HLog,一次数据的提交是先写WAL,再写memstore;
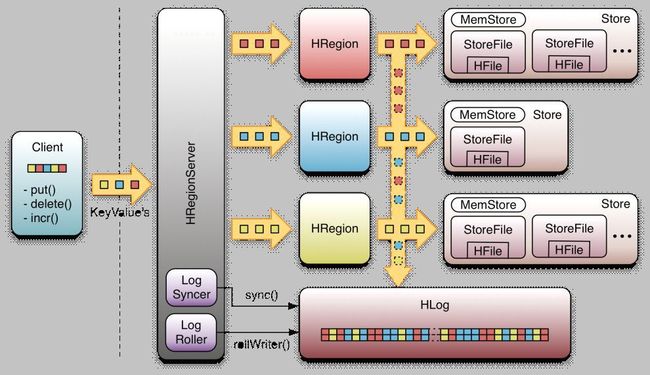
1 客户端对数据执行一个修改操作,如put(),delete(),incr()等。
2 每一个修改被封装到一个KeyValue对象实例,并通过RPC调用发送出来。
3 上述调用成批地发送给含有匹配region的HRegionServer。
4 数据先被写入到WAL,然后被放放到实际拥有记录的存储文件的MemStore中。
5 当MemStore达到一定的大小或经历一个特定时间之后,数据会异步地连续写入到文件系统中。
Write-Ahead-Log(WAL)保证数据的高可用性。
如果没有 WAL,当RegionServer宕掉的时候,MemStore 还没有写入到HFile,或者StoreFile还没有保存,数据就会丢失。
HBase中的HLog机制是WAL的一种实现,每个RegionServer中都会有一个HLog的实例,RegionServer会将更新操作(如 Put,Delete)先记录到 WAL(也就是HLog)中,然后将其写入到Store的MemStore,最终MemStore会将数据写入到持久化的HFile中(MemStore 到达配置的内存阀值)。这样就保证了HBase的高可用性。
HLog类
实现了WAL的类叫做HLog,当hregion被实例化时,HLog实例会被当做一个参数传到HRegion的构造器中,当一个Region接收到一个更新操作时,它可以直接把数据保存到一个共享的WAL实例中去
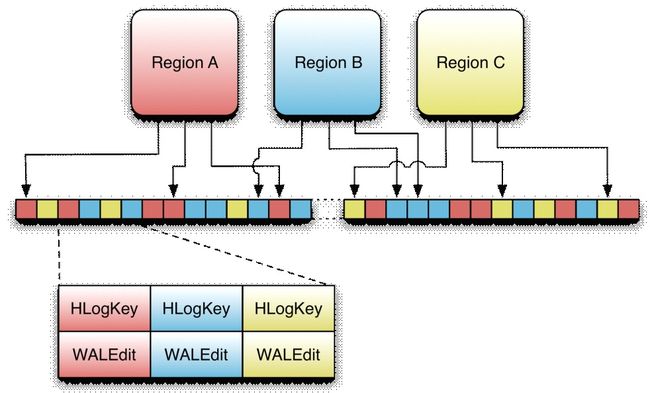
HLogKey类
1、当前的WAL使用的是hadoop的sequencefile格式,其key是HLogKey实例。HLogKey中记录了写入数据的归属信息,,除了table和region名字外,同时还包括sequence number和timestamp,timestamp是“写入时间“,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number
2、HLog sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue
WALEdit类
1、客户端发送的每个修改都会封装成WALEdit类,一个WALEdit类包含了多个更新操作,可以说一个WALEdit就是一个原子操作,包含若干个操作的集合
LogSyncer类
1、Table在创建的时候,有一个参数可以设置,是否每次写Log日志都需要往集群的其他机器同步一次,默认是每次都同步,同步的开销是比较大的,但不及时同步又可能因为机器宕而丢日志。同步的操作现在是通过pipeline的方式来实现的,pipeline是指datanode接收数据后,再传给另外一台datanode,是一种串行的方式,n-Way writes是指多datanode同时接收数据,最慢的一台结束就是整个结束,差别在于一个延迟大,一个开发高,hdfs现在正在开发中,以便可以选择是按pipeline还是n-way writes来实现写操作
2、Table如果设置每次不同步,则写操作会被RegionServer缓存,并启动一个LogSyncer线程来定时同步日志,定时时间默认是一秒也可由hbase.regionserver.optionallogflushinterval设置
LogRoller类
1、日志写入的大小是有限制的,LogRoller类会作为一个后台线程运行,在特定的时间间隔内滚动日志,通过hbase.regionserver.logroll.period属性控制,默认1小时
参考博客:
https://blog.csdn.net/yuexianchang/article/details/80434741
https://www.jianshu.com/p/8ff388759c61
https://blog.csdn.net/u010039929/article/details/74253093
https://www.cnblogs.com/double-kill/p/9835571.html
https://blog.csdn.net/u011598442/article/details/90632702
https://blog.csdn.net/weixin_34119545/article/details/90354589
https://www.cnblogs.com/163yun/p/9014762.html
https://blog.csdn.net/f1550804/article/details/88380971
https://blog.csdn.net/qq_18298439/article/details/88592861
http://blog.sina.com.cn/s/blog_15e0e0a700102w2v4.html