初识 pyhton - KMeans 简单聚类(一)
这篇是当时小学期的时候跟着老师学的一点,虽说是 KMeans 算法的使用,但使用的太浅显了,代码就仅几行,后来我去专门找了下关于 KMeans 聚类的博客,发现确实是老师讲的太少了。但由于时间关系,暂时没时间去深入学了,这里就放一下当时学的那一点。
开始之前先放一个要用到的文件:提取码 : u47s 。对于这样一个表格数据:
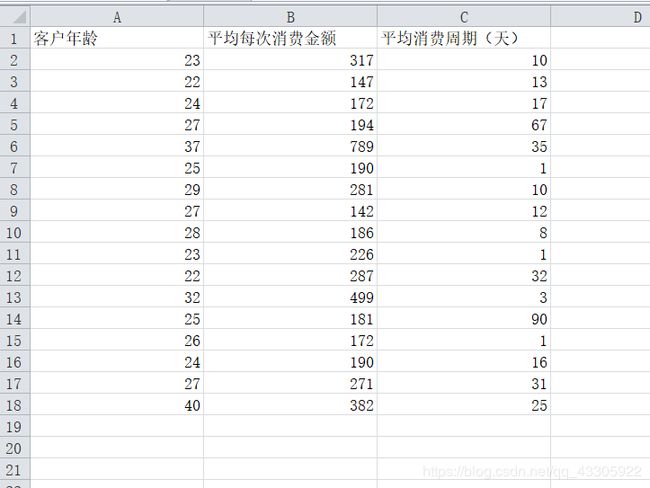
需要做的是对这一些数据进行聚类,划分为三类:超级vip客户,vip 客户 以及普通用户。下面进入正题:
一、读取数据
import pandas as pd
data = pd.read_csv('company.csv',encoding='gbk')
# print(type(data))
print(data)
# 数据->矩阵
mat = data.as_matrix()
#返回一个二元数组,每一条数据就是一个数组
print(type(mat))
print(mat)
# 删除年龄数据,年龄不作为标准
inX = mat[:,1:]当时老师在讲的时候,说是只要选中有效数据,KMeans 算法内部有划分标准,我对 KMeans 算法也不是很熟悉,但还是觉得有些不妥,但也没时间太深入了。
二、聚类
# python 中大多数机器学习算法都不需要手动写,在 sklearn 库中都已经包含
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3) #分为三类
result = kms.fit_predict(inX)
print('聚类后的结果:',result)
# 聚类后的结果: [0 2 2 2 1 2 0 2 2 2 0 0 2 2 2 0 0]这就是根据客户的平均每次消费金额及周期划分的三类,用 012 来表示。
三、可视化
由于聚类后的数据比较抽象,都是012之类的数据,看不出啥,所以将数据进行可视化后再分析。
import matplotlib.pyplot as plt
# 1)、创建画布
plt.figure()
# 属性设置
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.xlabel('消费周期(天)')
plt.ylabel('消费金额')
# 2)、进行绘制
# 逐个点(人)数据分析
for i in range(len(result)):
x = data.iloc[i,2]
y = data.iloc[i,1]
print('第%d个人的数据:'%i,x,y)
# 绘制
if result[i]==0:
plt.plot(x, y, '*r') #配置颜色
pass
elif result[i]==1:
plt.plot(x, y, '*b')
pass
else:
plt.plot(x, y, '*k')
# plt.plot(x,y,'*','r') # 将每一点用 “*” 来表示
# 3)、显示
plt.show()绘制出的图形如下:
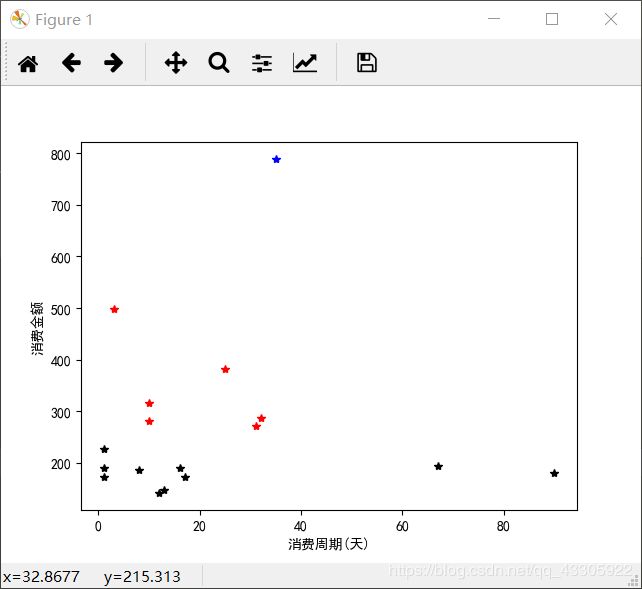
从最后的散点图上都能看出来,这聚类的太粗糙了,也不准确,但也只能先这样了,等以后有时间的话,想起来了再去研究下 KMeans 算法。