spark 安装部署与介绍
spark
- spark 概述
- 一. spark和hadoop
- 二. 应用常景和解决
- 生态系统组件
- 应用场景
- Spark执行任务流程图
- 三. Spark安装
- 四. Spark部署模式
- 1、单机本地模式(Spark所有进程都运行在一台机器的JVM中)
- 2、伪分布式模式 (在一台机器中模拟集群运行,相关的进程在同一台机器上)。
- 3、分布式模式包括:Spark自带的 Standalone、Yarn、Mesos。
- 3.1 Spark On yarn模式
- 3.2 Standalone:spark://主机名:port
- 3.2.1 Standalone 配置
- 3.2.2 Standalone有两种模式
- 3.3 Mesos模式
- 4、Spark专业术语
- 五.spark-submit 详解
- 六.Spark启停命令
- Spark webUI 及 History Server
- 启动Spark集群
- 七.spark shell
- 进入spark-shell
- 1、spark-shell本地单机模式
- 2、spark-shell sparkalone模式
- 3、spark-shell on yarn模式
- 4、spark-shell操作练习
- 4.1读取HDFS文件系统
spark 概述
一. spark和hadoop
| MapReduce | Spark |
|---|---|
| 数据存储结构:磁盘HDFS文件系统的split | 使用内存构建弹性分布式数据集RDDs对数据进行运算和cache |
| 编程范式:Map + Reduce | DAG: Transformation + Action |
| 计算中间结果落到磁盘IO及序列化、反序列化代价大 | 计算中间结果在内存中维护存取速度比磁盘高几个数量级 |
| Task以进程的方式维护,需要数秒时间才能启动任务 | Task以线程的方式维护对于小数据集读取能够达到亚秒级的延迟 |
hadoop缺点:
1.表达能力有限(MapReduce)
2.磁盘IO开销大(shuffle)
3.延迟高
spark:
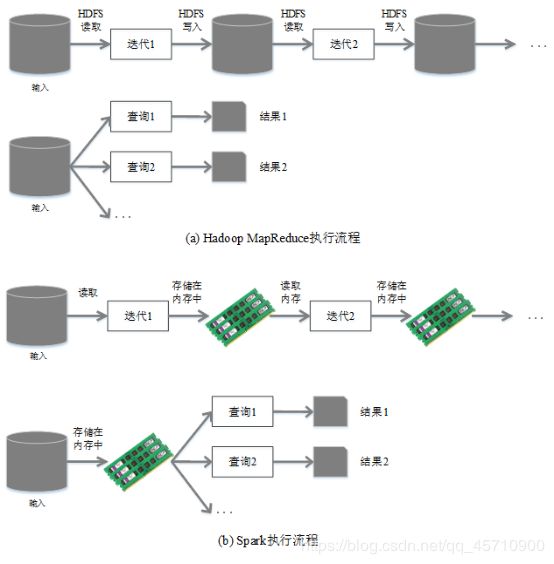
1.Spark的计算模式属于MapReduce,在借鉴Hadoop MapReduce优点的同时很好地解决了MapReduce所面临的问题
2.不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活
3.Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高
4.Spark基于DAG的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制(函数调用)
使用Hadoop进行迭代计算非常耗资源;
Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据
二. 应用常景和解决
在实际应用中,大数据处理主要包括以下三个类型:
1.复杂的批量数据处理:
通常时间跨度在数十分钟到数小时之间
2.基于历史数据的交互式查询:
通常时间跨度在数十秒到数分钟之间
3.基于实时数据流的数据处理:
通常时间跨度在数百毫秒到数秒之间
当同时存在以上三种场景时,就需要同时部署三种不同的软件比如:
MapReduce:离线批处理
Impala:交互式查询处理
Storm:实时流处理
这样做难免会带来一些问题:
不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换
不同的软件需要不同的开发和维护团队,带来了较高的使用成本
比较难以对同一个集群中的各个系统进行统一的资源协调和分配
Spark:既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等
Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案
Spark所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和流数据处理
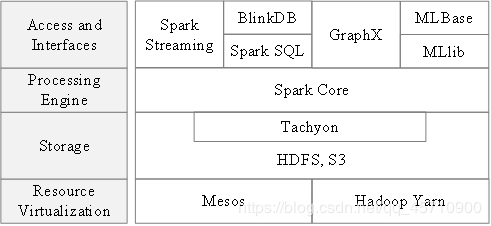
生态系统组件
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件。
应用场景
| 应用场景 | 时间跨度 | 其他框架 | Spark生态系统组件 |
|---|---|---|---|
| 复杂的批量数据处理 | 小时级 | MapReduce | Hive Spark |
| 基于历史数据的交互式查询 | 分钟级、秒级 | Impala、Dremel、Drill | Spark SQL |
| 基于实时数据流的数据处理 | 毫秒、秒级 | Storm、S4 | Spark Streaming |
| 基于历史数据的数据挖掘 | - | Mahout | MLlib |
| 图结构数据的处理 | - | Pregel、Hama | GraphX |
Spark执行任务流程图
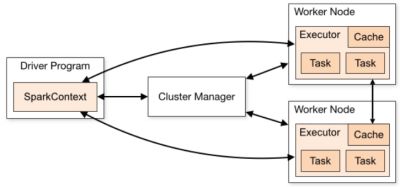
1、Spark运行架构包括:Master(集群资源管理)、Slaves(运行任务的工作节点)、应用程序的控制节点(Driver)和每个工作节点上负责任务的执行进程(Executor);
2、Master是集群资源的管理者(Cluster Manager)。支持:Standalone,Yarn,Mesos;
3、Slaves在spark中被称为Worker,工作节点,包括Executor。;
4、Driver Program。该进程运行应用的 main() 方法并且创建了SparkContext。由Cluster Manager分配资源,SparkContext将发送Task到Executor上执行。
5、每个工作节点上负责任务的执行进程(Executor);
Executor包括cache、分配到Executor上的task任务(task1、task2…tasksN)
三. Spark安装
1.从https://spark.apache.org/获得Spark的安装包
2.解压并安装Spark
tar –zxvf spark-****-bin-hadoop2.7.tgz
3.配置Spark
在YARN平台上运行Spark需要配置HADOOP_CONF_DIR、YARN_CONF_DIR和HDFS_CONF_DIR环境变量
3.1 vim /etc/profile
export HADOOP_CONF_DIR=$HADOOP_HOME/home/lyb/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/home/lyb/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/home/lyb/hadoop
保存关闭后执行
3.2 source /etc/profile
使环境变量生效
3.3 修改spark-env.sh
cp spark-env.sh.tmplate spark-env.sh
vim spark-env.sh
JAVA_HOME=/home/lyb/jdk
4.验证Spark安装
计算圆周率PI的值
进入Spark安装主目录
./bin/spark-submit
--class org.apache.spark.examples.SparkPi
--master yarn-cluster 模式选择(yarn-client;local)
--num-executors 3 进程数
--driver-memory 1g 驱动内存
--executor-memory 1g 运行时内存
--executor-cores 1 核数
/home/lyb/spark/examples/jars/spark-examples*.jar 10
四. Spark部署模式
1、单机本地模式(Spark所有进程都运行在一台机器的JVM中)
local:本地模式。在本地启动一个线程来运行作业;
local[N]:也是本地模式。启动了N个线程;
local[*]:还是本地模式。用了系统中所有的核;
local[N,M]:第一个参数表示用到核的个数;第二个参数表示容许该 作业失败 的次数。上面的几种模式没有指定M参数,其默认值都是1;
2、伪分布式模式 (在一台机器中模拟集群运行,相关的进程在同一台机器上)。
local-cluster[N, cores, memory]:伪分布式模式。N模拟集群的Slave节点个数;cores模拟集群中各个Slave节点上的内核数;memory模拟集群的各个Slave节点上的内存大小.
3、分布式模式包括:Spark自带的 Standalone、Yarn、Mesos。
spark:// :Spark的Standalone模式;
yarn:YARN模式;
(mesos|zk) : //:Mesos模式;
simr://:simr是Spark In MapReduce的缩写。在MapReduce 1中是没有 YARN的,如果要在MapReduce 中使用Spark,就使用这种模式。
3.1 Spark On yarn模式
1、Spark On yarn模式。是一种最有前景的部署模式。但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode);
2、由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化;
3、YARN拥有强大的社区支持,且逐步已经成为大数据集群资源管理系统的标准;
4、spark on yarn 的支持两种模式:
yarn-cluster:适用于生产环境
yarn-client:适用于交互、调试,希望立即看到app的输出
1.Spark支持资源动态共享,运行于Yarn的框架都共享一个集中配置好的资源池
2.可以很方便的利用Yarn的资源调度特性来做分类·,隔离以及优先级控制负载,
拥有更灵活的调度策略
3.Yarn可以自由地选择executor数量
4.Yarn是唯一支持Spark安全的集群管理器,使用Yarn,Spark可以运行于Kerberized Hadoop
之上,在它们进程之间进行安全认证
yarn-client和yarn-cluster的区别:
1)yarn-cluster:适用于生产环境;
2)yarn-client:适用于交互、调试,希望立即看到应用程序的输出
3)SparkContext初始化不同,这也导致了Driver所在位置的不同,YarnCluster
的Driver是在集群的某一台NM上,但是Yarn-Client就是在RM在机器上;
4)而Driver会和Executors进行通信,这也导致了Yarn_cluster在提交App之后可
以关闭Client,而Yarn-Client不可以;
5) Client结果当场就可看到,而cluster则需要到hadoop/logs/userlogs下找或者
自己配置的logs路径下
3.2 Standalone:spark://主机名:port
standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。从一定程度上说,该模式是其他两种的基础。
standalone-cluster:适用于生产环境
standalone-client:默认模式。适用于交互、调试,希望立即看到app的输出
是spark自己实现的,它是一个资源调度框架。
运行流程:
1)当spark集群启动以后,worker节点会有一个心跳机制和master保持通信;
2)SparkContext连接到master以后会向master申请资源,而master会根据worker
心跳来分配worker的资源,并启动worker的executor进程;
3)SparkContext将程序代码解析成dag结构,并提交给DagScheduler;
DAGScheduler:负责分析用户提交的应用,并根据计算任务的依赖关系建立DAG,
且将DAG划分为不同的Stage,每个Stage可并发执行一组task。
注:DAG在不同的资源管理框架实现是一样的。
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage,Reduce Stage
4)dag会在DagScheduler中分解成很多stage,每个stage包含着多个task;
5)stage会被提交给TaskScheduler,而TaskScheduler会将task分配到worker,提交
给executor进程,executor进程会创建线程池去执行task,并且向SparkContext
报告执行情况,直到task完成;
6)所有task完成以后,SparkContext向Master注销并释放资源;
总结:
standalone的是spark默认的运行模式,它的运行流程主要就是把程序代码解析成dag
结构,并再细分到各个task提交给executor线程池去并行计算。
在运行流程中我们并没有提到job这个概念,只是说dag结构会被分解成很多的stage。
其实,分解过程中如果遇到action操作(这不暂时不关注action操作是什么),那么
就会生成一个job,而每一个job都包含着一个或者多个stage,所以job和stage也是
一个总分的逻辑关系。
3.2.1 Standalone 配置
1.修改配置
1)修改spark-env.sh
SPARK_MASTER_HOST=master
//主节点host名称
SPARK_MASTER_PORT=7077
//spark传输端口号
SPARK_WORKER_CORES=2
// 分配给每个Worker core的个数
SPARK_WORKER_MEMORY=2g
// 分配给每个Worker内存的数量
SPARK_DAEMON_MEMORY=1g
//配给服务器的内存
SPARK_WORKER_INSTANCES=3
//实例数(一台虚拟机默认一个worker实例但配完后每台就有几个worker)
//从节点的worker数
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
//如果有这一项spark-shell启动是会检查hadoop的相关配置
//但如果环境变量配置了就不用配置了
2)修改spark-default.conf
spark.master spark://master:7077
//访问地址
spark.eventLog.dir hdfs://namenode:8021/directory
//日志地址路径
spark.serializer org.apache.spark.serializer.KryoSerializer
//序列化
spark.driver.memory 1g
//diver内存
spark.cores.max=6
//核心最大数
//当超过时会kill 将要运行的Standalone的executor
3)修改slaves
slave1
slave2
//这里面写的是从节点的节点主机名称
//worker所在节点主机
2.启动
//尽量在spark/sbin启动start-all.sh
//因为这里的start-all.sh与hadoop启动的脚本相同
//虽然说是根据Path路径顺序来但会冲突
注意:启动前先启动hadoop
spark/sbin/start-all.sh
当在slave1和slave2上看到每个节点都有3个worker时就成功了
webUI:
master:8080
//master需要在本机上配置c:windows/system32/Driver/etc/hosts
3.2.2 Standalone有两种模式
3.测试
Standalone有两种模式:
Standalone-client模式
Standalone-cluster模式
spark-submit --master spark://master:7077
--class org.apache.spark.examples.SparkPi jar地址 main函数需要参数
//不写默认client模式
spark-submit --master spark://master:7077
--deploy-mode client //依靠
--class org.apache.spark.examples.SparkPi jar地址 100
1.client模式适用于测试调试程序。Driver进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。
在Driver端可以看到task执行的情况。生产环境下不能使用client模式,是因为:假设要提交100个application到集群运行
Driver每次都会在client端启动,那么就会导致客户端100次网卡流量暴增的问题。
(因为要监控task的运行情况,会占用很多端口,如上图的结果图)客户端网卡通信,都被task监控信息占用。
spark-submit --master spark://master:7077
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi jar路径 100
1.当在客户端提交多个application时,Driver会在Woker节点上随机启动,这种模式会将单节点的网卡流量激增问题分散到集群中。
在客户端看不到task执行情况和结果。要去webui中看。
2.cluster模式适用于生产环境
3.Master模式先启动Driver,再启动Application。
运行时可以在
master:8080 查看进度
3.3 Mesos模式
Spark On Mesos模式。也是很多公司采用的模式,官方推荐这种模式。Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然;
目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序:
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配
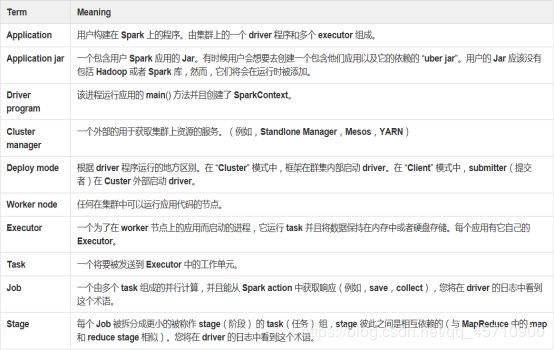
4、Spark专业术语
五.spark-submit 详解
Options:
--master MASTER_URL
spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE
driver运行之处,client运行在本机,cluster运行在集群
--class CLASS_NAME
应用程序包的要运行的class
--name NAME
应用程序名称
--jars JARS
用逗号隔开的driver本地jar包列表以及executor类路径
--py-files PY_FILES
用逗号隔开的放置在Python应用程序PYTHONPATH上的.zip, .egg, .py文件列表
--files FILES
用逗号隔开的要放置在每个executor工作目录的文件列表
--properties-file FILE
设置应用程序属性的文件放置位置,默认是conf/spark-defaults.conf
--driver-memory MEM
driver内存大小,默认512M
--driver-java-options
driver的java选项
--driver-library-path
driver的库路径Extra library path entries to pass to the driver
--driver-class-path
driver的类路径,用--jars 添加的jar包会自动包含在类路径里
--executor-memory MEM
executor内存大小,默认1G
Spark standalone with cluster deploy mode only:
–driver-cores NUM
driver使用内核数,默认为1
–supervise
如果设置了该参数,driver失败是会重启
Spark standalone and Mesos only:
–total-executor-cores NUM
executor使用的总核数
YARN-only:
–executor-cores NUM
每个executor使用的内核数,默认为1
–queue QUEUE_NAME
提交应用程序给哪个YARN的队列,默认是default队列
–num-executors NUM
启动的executor数量,默认是2个
–archives ARCHIVES
被每个executor提取到工作目录的档案列表,用逗号隔开
六.Spark启停命令
1、在主节点启动所有服务(包括slave节点,需要做免密码登录)
start-all.sh stop-all.sh
与hadoop的命令有冲突,需要调整
2、逐一启动主节点、从节点(在不同的节点上发指令)
start-master.sh | stop-master.sh
start-slave.sh spark://node1:7077
3、一次启停全部的从节点
start-slaves.sh | stop-slaves.sh
备注:
以上命令成对出现,有start一般就有stop
4、spark-daemon.sh
spark-daemon.sh start org.apache.spark.deploy.master.Master
spark-daemon.sh stop org.apache.spark.deploy.master.Master
spark-daemon.sh status org.apache.spark.deploy.master.Master
备注:很少使用
Spark webUI 及 History Server
1、能在主从节点启动相应服务(启动后用jps检查)
start-dfs.sh / stop-dfs.sh
start-all.sh / stop-all.sh
2、spark的日志文件
缺省位置$SPARK_HOME/logs/
3、进入spark-shell,执行命令
4、Web UI
http://hostIp:8080/
不要从windows的IE中连接linux主机查看。就在Linux环境中查看
5、run example
run-example SparkPi 10
需要启动hdfs、spark;同时检查二者的安装是否正确
启动Spark集群
cd $SPARK_HOME/sbin
使用start-all.sh、stop-all.sh命令来启动/停止Spark集群
启动之后在master主节点运行的Spark守护进程为:
Master(一个)
在slaves从节点运行的守护进程为:
Worker
每个从节点运行的worker进程个数根据设置的SPARK_WORKER_INSTANCES=3 实例个数决定,集群中的worker个数为从节点的数量乘以worker实例的个数,此处为 2 * 3共6个,相应的cores的个数,根据SPARK_WORKER_CORES=2 就是:6 * 2 共12个。
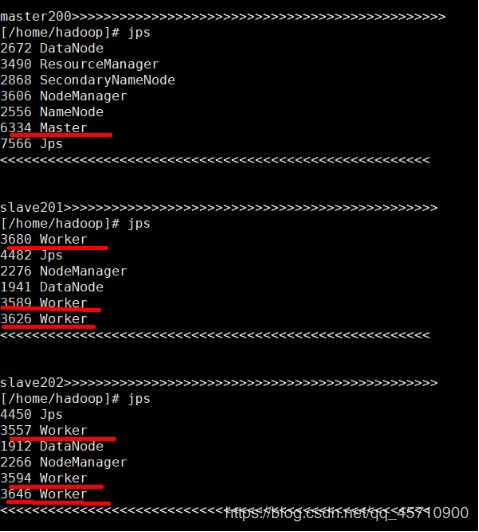
此处注意:
因为启动Spark集群之前,已经启动了Hadoop集群,hadoop集群的启停命令也有start-all.sh / stop-all.sh,所以启动了hadoop之后需要再启动Spark需要切换到Spark的主目录的sbin路径下运行相应的启停命令,防止对hadoop集群造成影响。
七.spark shell
进入spark-shell
启动Spark集群之后,可以使用spark-shell命令进入Spark的交互式窗口进行Spark的操作。
启动spark-shell命令
spark-shell --master 模式名称
--name application的名字
......
与submit参数类似
模式分为:local[Tasknum]
yarn
spark://master:7077
1、spark-shell本地单机模式
spark-shell --master local[2]
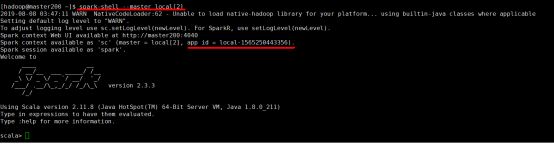
相当于使用spark-submit命令提交了一个spark进程,使用jps命令可以看到,开启了一个SparkSubmit的守护进程。

2、spark-shell sparkalone模式
spark-shell --master spark://master200:7077
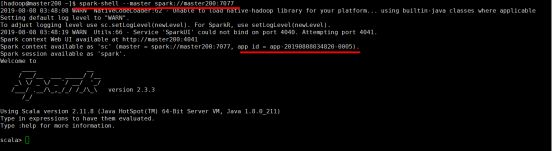
3、spark-shell on yarn模式
spark-shell --master yarn
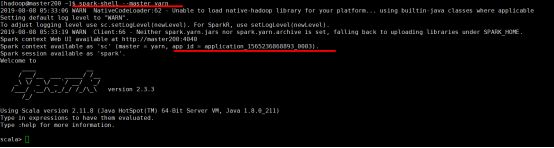
4、spark-shell操作练习
shell:交互式运行spark代码,类似于scala交互式终端
可用于快速体验spark,查看程序运行结果.
// 在使用spark-shell进入的时候就创建的SparkContext的实例对象sc、SparkSession实例对象spark
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@54f69311
scala> spark
res0: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@663622b1
// 使用sc.parallelize()方法将一般的数据类型转为RDDs的数据集
scala> val nums = sc.parallelize(List(1,2,3,4,5))
nums: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at < console>:24
scala> nums.count()
res1: Long = 5
scala> nums.take(3)
res2: Array[Int] = Array(1, 2, 3)
scala> val words = sc.parallelize(List(“Hello, this is my spark shell program.”, “Hello, this is my book”, “spark shell”))
words: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at < console > : 24
scala> words.flatMap(.split(" ")).map((,1)).reduceByKey(+).collect()
res14: Array[(String, Int)] = Array((this,2), (program.,1), (is,2), (my,2), (shell,2), (Hello,2), (book,1), (spark,2))
4.1读取HDFS文件系统
val rdd2 = sc.textFile("hdfs://master:9000/words.txt")
读取本地文件
val rdd2 = sc.textFile(“file:///root/words.txt”)
//在哪存储二进制格式
.saveAsSequenceFile("存储路径")
.saveAsTextFile("存储路径") //txt格式





