Flume + Kafka基本是日志实时采集的标准搭档了。
本篇文章基于Flume-ng-1.6.0-cdh5.7.0 + CentOS6.7 + JDK1.6+
-
下载,安装JDK
1.解压到 ~/app
2.将java配置系统环境变量中: vi ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
export PATH=$JAVA_HOME/bin:$PATH
3.source ~/.bash_profile下让其配置生效,
4.检测是否安装JDK成功:java -version
-
下载,安装Flume
1.下载,解压到 ~/app
2.将flume配置到系统环境变量中: ~/.bash_profile
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
3.source ~/.bash_profile让其配置生效,
4.修改flume-env.sh的配置:
cd $FLUME_HOME/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_144
5.检测: flume-ng version:
Flume 1.6.0-cdh5.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 8f5f5143ae30802fe79f9ab96f893e6c54a105d1
Compiled by jenkins on Wed Mar 23 11:38:48 PDT 2016
From source with checksum 50b533f0ffc32db9246405ac4431872e
-
从指定的网络端口采集数据输出到控制台
A single-node Flume configuration
1.使用Flume的关键就是写配置文件
A) 配置Source
B) 配置Channel
C) 配置Sink
D) 把以上三个组件串起来
a1: agent名称
r1: source的名称
k1: sink的名称
c1: channel的名称
2.下面是一个简单的配置文件范例,该例子通过netcat产生日志,
持续输出到console中。
-
example.conf配置:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
1个source可以指定多个channels,而1个sink只能接收来自1个channel的数据。
3.启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/example.conf \
-Dflume.root.logger=INFO,console
4.另开窗口,使用telnet进行测试: telnet hadoop 44444
5.输入测试文字,在flume-ng agent启动窗口看到telnet窗口输入的文字,以Event形式显示:
Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是FLume数据传输的基本单元
Event = 可选的header + byte array
-
监控一个文件实时采集增量数据输出到控制台
1.首先新增exec-memory-logger.conf配置:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command=tail -f /home/feiyue/data/flume-data.log
a1.sources.r1.shell=/bin/sh -c
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动agent
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-logger.conf \
-Dflume.root.logger=INFO,console
3.新开窗口echo hello >> flume-data.log,在flume-ng agent窗口看到监视的日志文件内容。
-
监控一个文件实时采集增量数据输出到HDFS
与上面的做法类似,只是配置信息有些变化:
type – The component type name, needs to be hdfs
hdfs.path – HDFS directory path (eg hdfs://namenode/flume/webdata/)
-
服务器A(Web APP)上的日志实时采集到服务器B(HDFS)上
1.技术选型:
日志服务器A:exec source + memory channel + avro sink
HDFS服务器B:avro source + memory channel + logger sink
跨节点以 avro文件形式传输较为普遍。
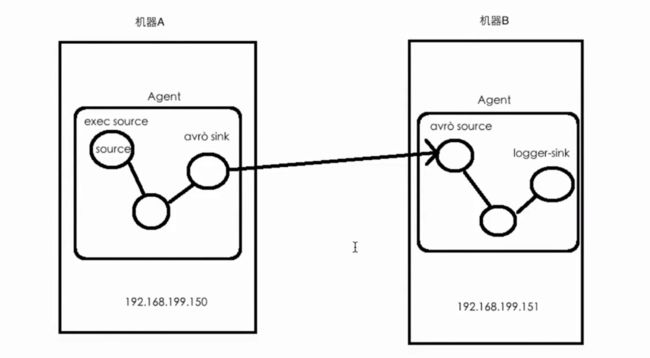
2.新增配置文件exec-memory-avro.conf并修改内容
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
exec-memory-avro.sinks.avro-sink.type = avro
# send to the configured hostname/port pair
exec-memory-avro.sinks.avro-sink.hostname = 192.168.199.151
exec-memory-avro.sinks.avro-sink.port = 44444
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel
3.新增配置文件avro-memory-logger.conf并修改内容
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
avro-memory-logger.sources.avro-source.type = avro
# Listens on Avro IP and port
avro-memory-logger.sources.avro-source.bind = 192.168.199.151
avro-memory-logger.sources.avro-source.port = 44444
avro-memory-logger.sinks.logger-sink.type = logger
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel
4.先启动avro-memory-logger,注意顺序
flume-ng agent \
--name avro-memory-logger \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/avro-memory-logger.conf \
-Dflume.root.logger=INFO,console
5.再启动exec-memory-avro,注意顺序
flume-ng agent \
--name exec-memory-avro \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/exec-memory-avro.conf \
-Dflume.root.logger=INFO,console
6.在服务器A上开启一个窗口,人工模拟往日志文件里输入内容
➜ echo ccccc >> flume-data.log
➜ echo 123456789 >> flume-data.log
7.在服务器B的flume-ng agent窗口将会看到Event形式的内容输出,可能略有延迟(内存缓存有关)
参考:
http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0/FlumeUserGuide.html