分布式深度学习(I):分布式训练神经网络模型的概述
原文: Distributed Deep Learning, Part 1: An Introduction to Distributed Training of Neural Networks
作者: Alex Black、Vyacheslav Kokorin
翻译: KK4SBB责编:何永灿,关注人工智能,投稿请联系[email protected]或微信号289416419
转自:http://geek.csdn.net/news/detail/105793
本文是分布式训练神经网络模型三篇系列文章的第一篇。
首先了解一下如何使用GPU分布式计算来显著提高深度学习模型的训练速度,以及会讨论其中面临的一些挑战和当前的研究方向。我们还会讨论在何种场景下适合(或不适合)采用分布式算法来训练神经网络模型。
概述
在大数据集上训练的现代神经网络模型在许许多多领域都取得了显著的效果,从语音和图像识别到自然语言处理,再到工业界的应用,比如欺诈检测和推荐系统。但是这些神经网络的训练过程非常耗时。尽管近些年GPU的硬件技术、网络模型结构和训练方法均取得了很大的突破,但是单机训练耗时过久的事实仍无法回避。好在我们并不局限于单机训练:人们投入了大量的工作和研究来提升分布式训练神经网络模型的效率。
我们首先介绍两种并行化/分布式训练的方法。
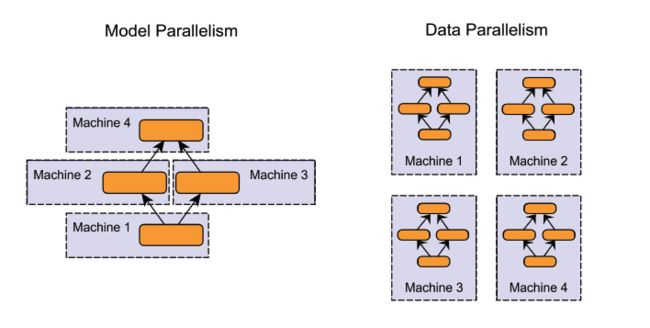
在模型并行化( model parallelism )方法里,分布式系统中的不同机器负责单个网络模型的不同部分 —— 例如,神经网络模型的不同网络层被分配到不同的机器。
在数据并行化( data parallelism )方法里,不同的机器有同一个模型的多个副本,每个机器分配到数据的一部分,然后将所有机器的计算结果按照某种方式合并。
当然,这些方法并不是完全互斥的。假设有一个多GPU集群系统。我们可以在同一台机器上采用模型并行化(在GPU之间切分模型),在机器之间采用数据并行化。
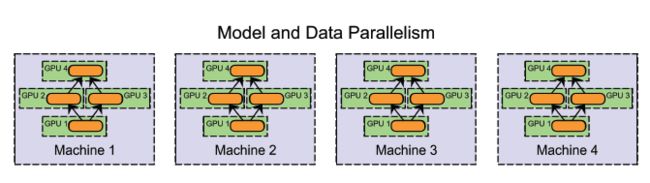
尽管在实际应用中模型并行化的效果还不错,数据并行化却是多数分布式系统的首选,后者投入了大量的研究。一方面,数据并行化在实现难度、容错率和集群利用率方面都优于模型并行化。分布式系统背景下的模型并行化挺有意思,有不少优势(例如扩展性),但在本文中我们主要讨论数据并行化。
数据并行化
数据并行化式的分布式训练在每个工作节点上都存储一个模型的备份,在各台机器上处理数据集的不同部分。数据并行化式训练方法需要组合各个工作节点的结果,并且在节点之间同步模型参数。文献中讨论了各种方法,各种方法之间的主要区别在于:
- 参数平均法 vs. 更新式方法
- 同步方法 vs. 异步方法
- 中心化同步 vs. 分布式同步
目前Deeplearning4j实现的方式是同步的参数平均法。
参数平均
参数平均是最简单的一种数据并行化。若采用参数平均法,训练的过程如下所示:
- 基于模型的配置随机初始化网络模型参数
- 将当前这组参数分发到各个工作节点
- 在每个工作节点,用数据集的一部分数据进行训练
- 将各个工作节点的参数的均值作为全局参数值
- 若还有训练数据没有参与训练,则继续从第二步开始
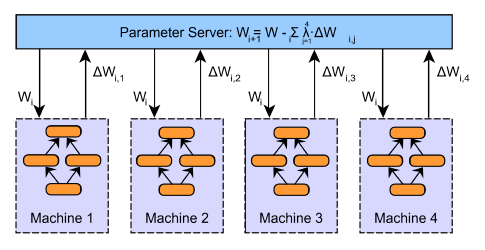
上述第二步到第四步的过程如下图所示。在图中,W表示神经网络模型的参数(权重值和偏置值)。下标表示参数的更新版本,需要在各个工作节点加以区分。
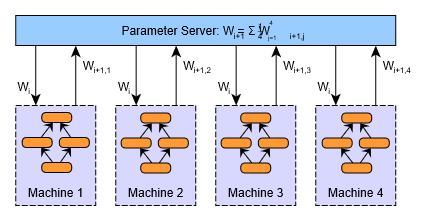
事实上,很容易证明参数平均法的结果在数学意义上等同于用单个机器进行训练;每个工作节点处理的数据量是相等的。数学的证明过程如下。
假设该集群有n个工作节点,每个节点处理m个样本,则总共是对nxm个样本求均值。如果我们在单台机器上处理所有nxm个样本,学习率设置为α,权重更新的方程为:
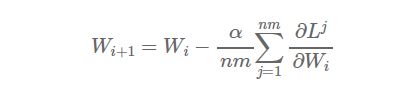
现在,假设我们把样本分配到n个工作节点,每个节点在m个样本上进行学习(节点1处理样本1,……,m,节点2处理样本m+1,……,2m,以此类推),则得到:
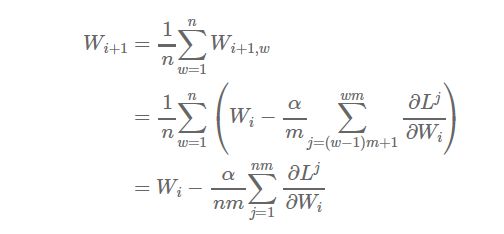
当然,上述结果在实际应用中可能并不严格一致(从性能和收敛性的角度来说,对所有minibatch进行平均和不采用诸如momentum和RMSProp之类的updater的建议都较为偏颇),但是它从直觉上告诉了我们为啥参数平均法是一种可行的做法,尤其是当参数被频繁的求均值。
参数平均法听上去非常简单,但事实上并没有我们看上去这么容易。
首先,我们应该如何求平均值?最简单的办法就是简单地将每轮迭代之后的参数进行平均。一旦这样实现了,我们会发现此方法在计算之外的额外开销非常巨大;网络通信和同步的开销也许就能抵消额外机器带来的效率收益。因此,参数平均法通常有一个大于1的平均周期averaging period(就每个节点的minibatch而言)。如果求均值太频繁,那么每个节点得到的局部参数更多样化,求均值之后的模型效果非常差。我们的想法是N个局部最小值的均值并不保证就是局部最小:
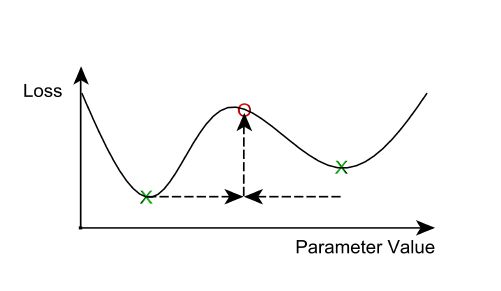
什么样的平均的周期算是过高呢?这个问题还没有结论性的回答,和其它超参数搅和在一起之后变得更为复杂,比如学习率、minibatch的大小,和工作节点的数量。有些初步的研究结论(比如[8])建议平均的周期为每10~20个minibatch计算一次(每个工作节点)能够取得比较好的效果。随着平均的周期延长,模型的准确率则随之下降。
另一类额外的复杂度则是与优化算法相关,比如adagrad,momentum和RMSProp。这些优化方法(即Deeplearning4j中的updater)在神经网络的训练过程中能够显著提升收敛的特性。然而,这些updater都有中间状态(通常每个模型参数有1或2个状态值)—— 我们也需要对这些状态值求均值吗?对每个节点的中间状态求均值可以加快收敛的速度,而牺牲的代价则是两倍(或者多倍)增加网络的传输数据量。有些研究在参数服务器的层面应用类似的“updater”机制,而不仅仅在每个工作节点([1])。
异步随机梯度下降
有另一种与参数平均概念类似的方法,我们称之为‘基于更新’的数据并行化。两者的主要区别在于相对于在工作节点与参数服务器之间传递参数,我们在这里只传递更新信息(即梯度和冲量等等)。参数的更新形式变为了:
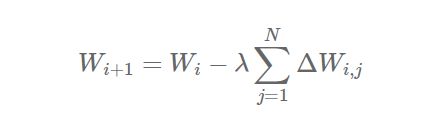
其中 λ 是一个缩放因素(类似于学习率这类的超参数)。
它从结构上来看与参数平均法非常相似:
熟悉神经网络模型训练过程的数学原理的读者也许已经注意到了参数平均法与基于更新的方法之间的相似点。如果我们定义损失函数为L,学习率为α,那么权值向量W在SGD训练过程的第i+1次迭代的结果为
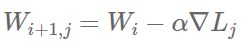
其中
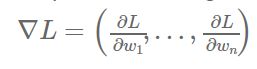
如果我们按照上述的权重更新规则,并且设置
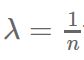
权重值的更新量为
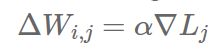
(简单期间,仅用学习率为α的SGD算法),于是得到
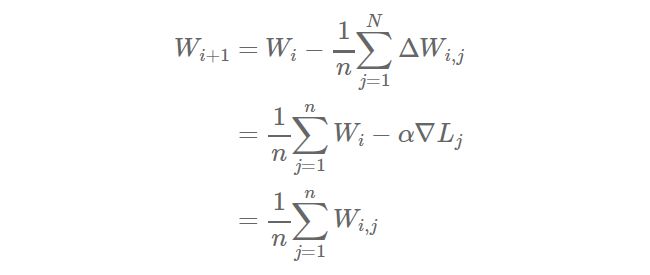
最终,当参数时同步方式更新时,参数平均法等价于基于更新的数据并行化。这个等价关系对多个平均步骤以及其它updater都成立(不仅限于简单版SGD)。
当我们松绑同步更新的条件之后,基于更新的数据并行化方法变得更有意思了。也就是说,一旦计算得到?Wi,j,就立即将其应用于参数向量(而不是等待N ≥ 1 轮迭代),我们因此得到了异步随机梯度下降算法。异步SGD有两个主要优势:
- 首先,我们能够增加分布式系统的数据吞吐量:工作节点能把更多的时间用于数据计算,而不是等待参数平均步骤的完成
- 其次,相比于同步更新的方式(每隔N步),各个节点能够更快地从其它节点获取信息(参数的更新量)。
但是,这些优势也不是没带来开销。随着引入参数向量的异步更新,我们带来了一个新的问题,即梯度值过时问题。梯度值过时问题也很简单:计算梯度(更新量)需要消耗时间。当某个节点算完了梯度值并且将其与全局参数向量合并时,全局参数可能已经被刷新了多次。用图片来解释这个问题就是如下:
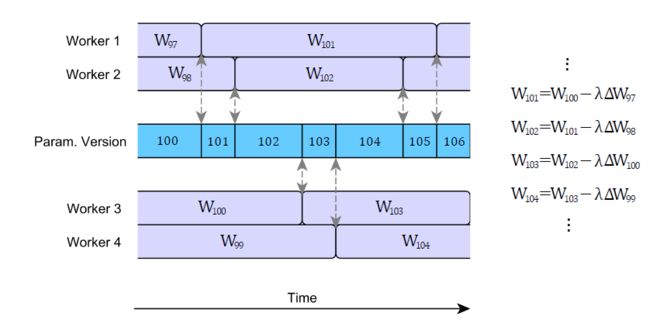
异步SGD的简单实现可能会导致非常严重的梯度值过时。举个例子,Gupta et al. 2015 [3]证明了梯度值的平均过时量等于执行单元的个数。假设有N个执行单元,也就是说梯度值被用于计算全局参数向量时,平均会延迟N个计算步骤。这会在现实场景中带来问题:严重的梯度值过时会明显减慢网络模型的收敛速度,甚至完全停止了收敛。早期的异步SGD实现(例如Google的DistBelief系统[2])并没有考虑到这些问题,因此学习的效率远不如它原本应有状态。
异步随机梯度下降方法还有多种形式的变种,但采取了各种策略来减弱梯度过时所造成的影响,同时保持集群的高可用率。解决梯度值过时的方法包括以下几种:
- 基于梯度值的过时量,对每次更新?Wi,j 分别缩放λ的值
- 采用‘软’的同步策略soft synchronization([9])
- 使用同步策略来限制过时量。例如,[4]提到的系统在必要时会延迟速度较快的节点,以保证最大的过时量控制在某个阈值以下。
所有这些方法相比简单的异步SGD算法都本证明能提升收敛的性能。尤其是前两条方法效果更为显著。soft synchronization的方法很简单:相对于立即更新全局参数向量,参数服务器等待收集n个节点产生的s次更新?Wj(1 ≤ s ≤ n)。参数随之进行更新:
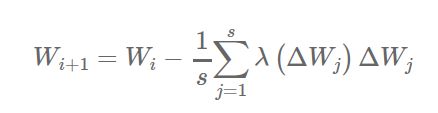
其中 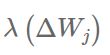
表示缩放因子。
注意,我们设置s=1并且λ(·) = 常数,就得到了简单版的异步SGD算法([2]);同样的,若设置s = n,我们得到了类似(不完全相同)同步参数平均的算法。
去中心化异步随机梯度下降
文献[7]给出了一种分布式训练神经网络模型的方法。我将这种方法称为去中心化的异步随机梯度下降算法(尽管作者并不使用这一术语)。这篇文章有两大特色:
- 系统中不存在位于中心地位的参数服务器(而是采用平等的通信方式在节点之间传递模型更新量)
- 更新量被高度压缩,网络通信的数据量可以减少大约3个数量级。
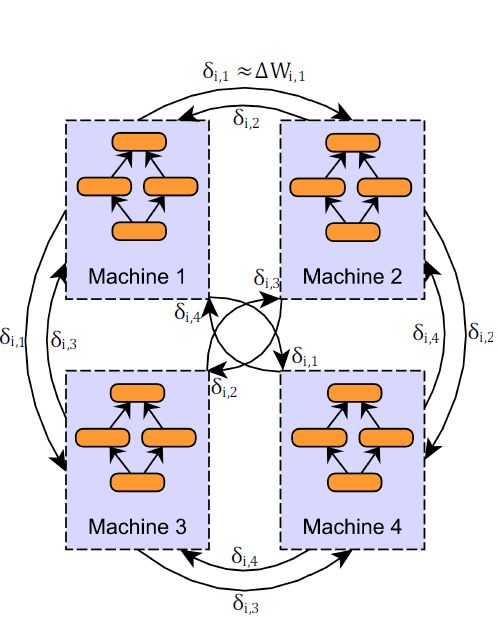
在标准的数据并行化实现中(采用参数平均或者异步SGD),网络的传输量等于参数向量的大小(因为我们要不传输整个参数向量的副本,要不每个向量的梯度值)。尽管压缩参数或者更新量的想法并不算很新,它的实现方法比其它简单的压缩机制更胜一筹(例如采用压缩编码或是转换为16位浮点数表示)。
这个设计的优点在于更新向量δi,j 是:
- 稀疏向量:在每个向量δi,j 中只有一部分梯度值需要传播(剩余的值默认为0)—— 使用整数索引来对稀疏元素进行编码
- 量化为一个比特:稀疏更新向量的每一个元素取值+τ 或 ?τ。τ的值对向量的所有元素都相同,因此只需要用一个bit来区分这两种取值。
- 整数索引值(用于识别稀疏向量中的元素索引)也可以采取熵编码来进一步降低数据量(作者提到增加这些额外的计算之后还能压缩三倍,尽管换来的收益并不值这些额外的开销)
这里引出了两个问题:(a)这些工作对减少网络传输究竟有多大的帮助?(b)它对准确率有何影响?答案分别是很大和比你想象的要少。
举个例子,假设一个模型有14.6个参数,如Strom的论文中所描述的:

可以尝试取值更大的τ,压缩率会随之增加(例如, 若τ=15,则update size只有4.5KB),但是模型的准确率会有明显的下降。
尽管这种方法的结果很吸引眼球,但是它也存在三个主要的弊端。
- Strom提到在训练的早期阶段收敛就会遇到问题(减少计算节点似乎能有帮助)
- 压缩和量化数据也需要开销:这些过程导致了给每个minibatch增加额外计算开销,以及每个执行单元的少量内存开销。
- 整个过程中引入了两个额外的超参数:τ的取值和是否使用熵编码(显然参数平均和异步SGD都会引入额外的超参数)
最后,就作者所知,目前并没有异步SGD与去中心化的异步SGD的实践比较。
分布式训练神经网络模型:哪种方法最好?
我们已经看到了许多种训练分布式神经网络的方法,每种方法又有多个变种。那么我们在实际应用中究竟应该选择哪一种呢?很不幸,我们并不能找到一个简单的答案。按照下面罗列的准则,我们可以将不同的方法定义为最优方法:
- 训练速度最快(每秒钟处理样本数量最多,或者每个epoch消耗时间最少)
- 当nepochs → ∞时,最大化模型预测的准确率
- 当给定训练时间时,最大化模型预测的准确率
- 当给定epoch时,最大化模型预测的准确率
另外,那个问题的答案也与许多因素有关,例如神经网络模型的类型和规模,集群的硬件配置,所选用的特性(如压缩算法),以及训练方法的特殊实现逻辑和配置。
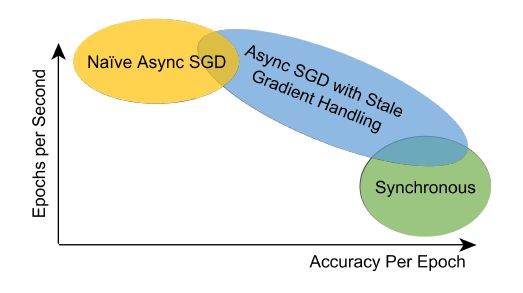
我们从研究文献中可以总结出一些结论:
同步式参数平均方法(或者同步更新方法)就每一轮epoch的准确率,以及全局的准确率来说更胜一筹,尤其是当平均周期选的较小的时候。当N=1平均周期与单机训练的过程非常类似。然而,额外的同步开销也意味着这个方法每个epoch的速度更慢;也就是说,诸如InfiniBand的快速网络连接能极大地提高同步方法的竞争力(见文献[5]的例子)。然而,即使是普通商用硬件,我们在实践中用DL4J实现的同步参数平均方法也看到了较好的集群利用率。使用压缩还能进一步减小网络的开销。
也许参数平均法(以及普遍的同步方法)的最大问题在于所谓的“last executor”效应:即同步系统需要等待最慢的处理单元结束之后才能完成一次迭代。结果导致随着工作节点的增加,同步系统变得越来越不灵活。
异步随机梯度下降算法是训练模型的好方法,在实际使用中也被证明有效,只要控制好梯度过时的问题。有些实现方法是介于异步SGD和同步实现之间,取决于超参数的使用。
带有中心参数服务器的异步SGD可能存在通讯的瓶颈(而同步的方法可以采用tree-reduce或是类似的算法来避免这类通讯瓶颈),使用N个参数服务器,每个参数服务器负责一部分参数,这是一种直截了当的解决方式。
最后,去中心化异步随机梯度下降法是一个好方向,但是还需要进一步研究的支持用它替代‘标准’的异步SGD。
何时使用分布式深度学习
分布式的深度学习并不总是最佳的选择,需要视情况而定。
分布式训练并不是免费 —— 由于同步、数据和参数的网络传输等,分布式系统相比单机训练要多不少额外的必要开销。若要采用分布式系统,我们则希望增添机器带来的收益能够抵消那些必要开销。而且,分布式系统的初始化(比如搭建系统和加载数据)和超参数调优也比较耗时。因此,我们的建议非常简单:继续用单机训练网络模型,直到训练时间过长。
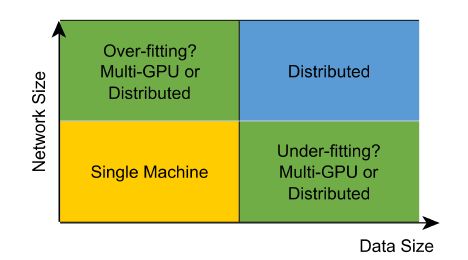
有两种原因可能导致网络模型的训练时间过长:网络规模太大或是数据量太大。事实上,若这两者不匹配(大模型配小数据,小模型配大数据)这可能导致欠拟合和过拟合 —— 都将导致最终训练得到的模型缺少泛化能力。
在某些情况下,应该首先考虑多GPU系统(如Deeplearning4j的Parallel-Wrapper就能很方便地在单机上实现以数据并行化方式训练模型)。
另一个需要考虑的因素是网络传输与计算量的比值。当传输与计算的比值较低时,分布式训练的效率往往较高。小的、浅层的网络由于每次迭代的计算量较小,并不适合分布式训练。带有参数共享的网络(比如CNN和RNN)是分布式训练的理想对象:因为它们每个参数的计算机远远大于多层感知机或是自编码器。
第二篇提要:在Apache Spark上使用Deeplearning4j进行分布式深度学习
在我们分布式深度学习系列文章的第二、第三篇中,我们会介绍使用Apache Spark的Deeplearning4j的参数平均法实现,以及借用一个端到端的例子讲解如何用它在Spark集群上训练神经网络模型。
参考文献
[1] Kai Chen and Qiang Huo. Scalable training of deep learning machines by incremental block training with intra-block parallel optimization and blockwise model-update filtering. In 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5880–5884. IEEE, 2016.
[2] Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior, Paul Tucker, Ke Yang, Quoc V Le, et al. Large scale distributed deep networks. In Advances in Neural Information Processing Systems, pages 1223–1231, 2012.
[3] Suyog Gupta, Wei Zhang, and Josh Milthrope. Model accuracy and runtime tradeoff in distributed deep learning. arXiv preprint arXiv:1509.04210, 2015.
[4] Qirong Ho, James Cipar, Henggang Cui, Seunghak Lee, Jin Kyu Kim, Phillip B. Gibbons, Garth A Gibson, Greg Ganger, and Eric P Xing. More effective distributed ml via a stale synchronous parallel parameter server. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger, editors, Advances in Neural Information Processing Systems 26, pages 1223–1231. Curran Associates, Inc., 2013.
[5] Forrest N Iandola, Khalid Ashraf, Mattthew W Moskewicz, and Kurt Keutzer. Firecaffe: near-linear acceleration of deep neural network training on compute clusters. arXiv preprint arXiv:1511.00175, 2015.
[6] Augustus Odena. Faster asynchronous sgd. arXiv preprint arXiv:1601.04033, 2016.
[7] Nikko Strom. Scalable distributed dnn training using commodity gpu cloud computing. In Sixteenth Annual Conference of the International Speech Communication Association, 2015. http://nikkostrom.com/publications/interspeech2015/strom_interspeech2015.pdf.
[8] Hang Su and Haoyu Chen. Experiments on parallel training of deep neural network using model averaging. arXiv preprint arXiv:1507.01239, 2015.
[9] Wei Zhang, Suyog Gupta, Xiangru Lian, and Ji Liu. Staleness-aware async-sgd for distributed deep learning. IJCAI, 2016.