D004 复制粘贴玩大数据之Dockerfile安装Zookeeper集群
教程目录
- 0x00 教程内容
- 0x01 Dockerfile文件的编写
- 1. 编写Dockerfile文件
- 2. 编写Dockerfile文件的关键点
- 3. 完整的Dockerfile文件参考
- 0x02 校验zk集群前准备工作
- 1. 环境及资源准备
- 2. 添加zk配置文件及启动zk指令信息
- 0x03 校验是否zk安装成功
- 1. 生成镜像
- 2. 生成容器并初始化zk集群
- 3. 启动集群并查看进程
- 0xFF 总结
0x00 教程内容
- Dockerfile文件的编写
- 校验zk集群前准备工作
- 校验是否zk安装成功
0x01 Dockerfile文件的编写
1. 编写Dockerfile文件
为了方便,我复制了一份spark集群的文件,取名zk_sny_all:

a. zk集群安装步骤
参考文章:D003 复制粘贴玩大数据之安装与配置Zookeeper集群
| 常规安装 | Dockerfile安装 |
|---|---|
| 1.将安装包放于容器 | 1.添加安装包并解压 |
| 2.解压并配置zk | 2.添加环境变量 |
| 3.添加环境变量 | 3.添加配置文件与创建文件夹 |
| 4.启动zk | 4.启动zk(启动前设置一下myid) |
- 其实安装内容都是一样的,这里只是就根据我写的步骤整理了一下
2. 编写Dockerfile文件的关键点
与D001.8 Docker搭建Spark集群(实践篇)的“0x01 2. c. Dockerfile参考文件”相比较,不同点体现在:
具体步骤:
a. 添加安装包并解压(ADD指令会自动解压)
#添加zookeeper
ADD ./zookeeper-3.4.10.tar.gz /usr/local/
b. 添加环境变量(ZK_HOME、PATH)
#zk环境变量
ENV ZK_HOME /usr/local/zookeeper-3.4.10
#PATH里面追加内容
$ZK_HOME/bin:
c. 添加配置文件与创建文件夹(注意给之前的语句加“&& \”,表示未结束)
&& \
mkdir -p /usr/local/zookeeper-3.4.10/datadir && \
mkdir -p /usr/local/zookeeper-3.4.10/log && \
mv /tmp/zoo.cfg $ZK_HOME/conf/zoo.cfg
3. 完整的Dockerfile文件参考
a. 安装hadoop、spark、zookeeper
FROM ubuntu
MAINTAINER shaonaiyi [email protected]
ENV BUILD_ON 2019-01-28
RUN apt-get update -qqy
RUN apt-get -qqy install vim wget net-tools iputils-ping openssh-server
#添加JDK
ADD ./jdk-8u161-linux-x64.tar.gz /usr/local/
#添加hadoop
ADD ./hadoop-2.7.5.tar.gz /usr/local/
#添加scala
ADD ./scala-2.11.8.tgz /usr/local/
#添加spark
ADD ./spark-2.2.0-bin-hadoop2.7.tgz /usr/local/
#添加zookeeper
ADD ./zookeeper-3.4.10.tar.gz /usr/local/
ENV CHECKPOINT 2019-01-28
#增加JAVA_HOME环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_161
#hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop-2.7.5
#scala环境变量
ENV SCALA_HOME /usr/local/scala-2.11.8
#spark环境变量
ENV SPARK_HOME /usr/local/spark-2.2.0-bin-hadoop2.7
#zk环境变量
ENV ZK_HOME /usr/local/zookeeper-3.4.10
#将环境变量添加到系统变量中
ENV PATH $ZK_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$PATH
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
#复制配置到/tmp目录
COPY config /tmp
#将配置移动到正确的位置
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/profile /etc/profile && \
mv /tmp/masters $SPARK_HOME/conf/masters && \
cp /tmp/slaves $SPARK_HOME/conf/ && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/master $HADOOP_HOME/etc/hadoop/master && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mkdir -p /usr/local/hadoop2.7/dfs/data && \
mkdir -p /usr/local/hadoop2.7/dfs/name && \
mkdir /usr/local/zookeeper-3.4.10/datadir && \
mkdir /usr/local/zookeeper-3.4.10/log && \
mv /tmp/zoo.cfg $ZK_HOME/conf/zoo.cfg
RUN echo $JAVA_HOME
#设置工作目录
WORKDIR /root
#启动sshd服务
RUN /etc/init.d/ssh start
#修改start-hadoop.sh权限为700
RUN chmod 700 start-hadoop.sh
#修改root密码
RUN echo "root:shaonaiyi" | chpasswd
CMD ["/bin/bash"]
0x02 校验zk集群前准备工作
1. 环境及资源准备
a. 安装Docker
请参考:D001.5 Docker入门(超级详细基础篇)的“0x01 Docker的安装”小节
b. 准备资源
安装Spark集群时的文件:D001.8 Docker搭建Spark集群(实践篇)
c. 准备zk安装包(zookeeper-3.4.10.tar.gz),像其他安装包一样
d. 准备zk的配置文件zoo.cfg(放于config目录下)
cd /home/shaonaiyi/docker_bigdata/zk_sny_all/config
vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.4.10/datadir
dataLogDir=/usr/local/zookeeper-3.4.10/log
# the port at which the clients will connect
clientPort=2181
server.0=hadoop-master:8880:7770
server.1=hadoop-slave1:8881:7771
server.2=hadoop-slave2:8882:7772
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
2. 添加zk配置文件及启动zk指令信息
a. 配置环境变量文件
vi profile
- 在config/profile中添加zk的环境变量
export ZK_HOME=/usr/local/zookeeper-3.4.10 - 在export PATH=后面添加
$ZK_HOME/bin:
b. 在config/start-hadoop.sh添加内容:
vi start-hadoop.sh
#修改需要配置及启动zk命令的命令
ssh root@hadoop-master "source /etc/profile;/usr/local/zookeeper-3.4.10/bin/zkServer.sh start"
ssh root@hadoop-slave1 "source /etc/profile;/usr/local/zookeeper-3.4.10/bin/zkServer.sh start"
ssh root@hadoop-slave2 "source /etc/profile;/usr/local/zookeeper-3.4.10/bin/zkServer.sh start"
echo -e "\n"
0x03 校验是否zk安装成功
1. 生成镜像
a. 删除之前的spark集群容器(节省资源),如已删可省略此步
cd /home/shaonaiyi/docker_bigdata/spark_sny_all/config/
chmod 700 stop_containers.sh
./stop_containers.sh
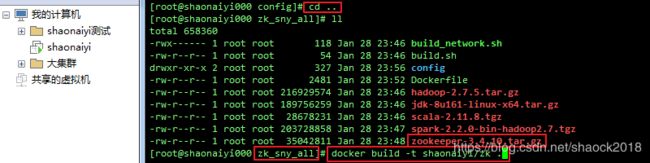
b. 生成装好hadoop、spark、zookeeper的镜像(如果之前shaonaiyi/spark未删除,则此次会快很多)
cd ..
docker build -t shaonaiyi/zk .
2. 生成容器并初始化zk集群
a. 修改start_containers.sh文件(样本镜像名称成shaonaiyi/zk、ip)
本人把里面的三个shaonaiyi/spark改为了shaonaiyi/zk,ip最后一位加了1,如:
172.21.0.2改为了172.21.0.12等等~
./start_containers.sh
ps:当然,你可以新建一个新的网络,换ip,这里偷懒,用了旧的网络,只换了ip
b. 进入master容器(不明白请参考:便捷配置)
sh ~/master.sh
c. 初始化zk集群,给各节点添加myid:
vi init_zk.sh
#!/bin/bash
ssh root@hadoop-master "echo '0' >> $ZK_HOME/datadir/myid"
ssh root@hadoop-slave1 "echo '1' >> $ZK_HOME/datadir/myid"
ssh root@hadoop-slave2 "echo '2' >> $ZK_HOME/datadir/myid"
chmod 700 init_zk.sh
ps:课后题,如何在生成镜像时自动将此步写好,思考一下?!
3. 启动集群并查看进程
a. 初始化zk配置,启动集群
./init_zk.sh

./start-hadoop.sh
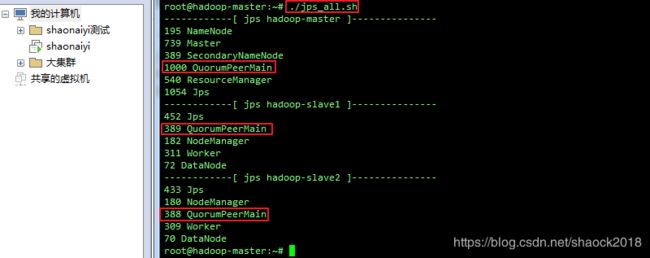
b. 执行查看进程
./jps_all.sh
请参考:D002 复制粘贴玩大数据之便捷配置的“0x03 1. jps_all.sh脚本”
0xFF 总结
- 最好自己备份好安装spark集群时的Dockerfile与start_containers.sh等文件,也可以自己备份一份之前spark集群的环境,免得出问题了,无法回溯
- Dockerfile常用指令,请参考文章:D004.1 Dockerfile例子详解及常用指令
- 本章节还有很多优化的地方,包括各脚本文件的一件生成,取代机械操作,学习一下Dockerfile的常用指令,自己就可以完成了,非常简单
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
本系列课均为本人:邵奈一原创,如转载请标明出处