透彻理解RPN: 从候选区域搜索到候选区域提取网络
在目标检测、目标跟踪领域,提取region proposal都是最基本环节。本文概述了从 sliding window 到 selective search, 然后升级到 region proposal network的过程。 核心在于理解 selective search算法 和 region proposal network的设计思想。
1. 从sliding window 到 selective search 的候选区域提取
- 目标检测 vs. 目标识别
 直接作为图像识别算法的输入
直接作为图像识别算法的输入
目标识别算法是指在一张给定的图像中识别出给定的物体。他将整张图像作为输入,然后输出类别的标签并给出图像中出现物体的概率。如上图,直接输入objection recognition算法中,算法会反馈图像的类别dog, confident score 0.9987.
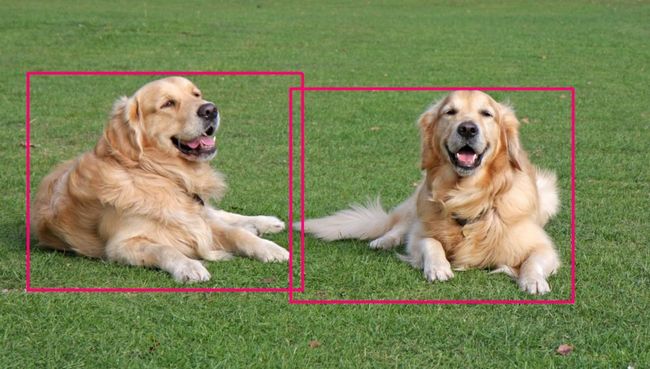 目标检测返回类别和边界框
目标检测返回类别和边界框
目标检测任务不仅仅要返回图像中主要包含那些物体,而且还要返回该图像中包含了多少物体? 他们在哪里(一般用BoundingBox进行标注)?
目标识别算法是所有目标检测算法的核心。假设我们已经拥有了非常强大的目标识别算法,但是该算法也仅仅能够告诉我们目标(如狗)是什么, 却不能告诉我们目标在哪里? 有多少个目标?
为了完成目标检测任务,我们需要选择一个更小的区域(sub-regions,patches),然后利用目标识别算法去识别各个patches是否包含high confident score的objections。
因此,一个非常基础但很重要的环节在于:如何从一张图像中又快又好地提取出这样的patches?其实最直接的方法提取region proposal(候选区域)的方式就是采用滑窗方法。但是sliding window方法非常消耗时间,因此研究学者提出了基于selective search策略的区域候选算法。
note1:提取patches算法更学术一点叫做region proposal algorithm
note2:好,指的是patches中尽可能恰好包括objects
note3:快,指的是有效速度。因为不同目标之前存在位置和尺度差异,如果采用遍历法,明显就是不合理的。
- Sliding window 滑窗技术
使用sliding window方法中,我们使用window对整幅图像进行遍历,然后利用目标识别算法所有的patches进行检查。这实际上就是一个穷举的过程。此外,在遍历搜索过程中,我们不仅仅要遍历单个尺度的window,还有对多尺度的window进行检测。 因此,sliding window策略是非常消耗时间的。还有就是,sliding window算法对固定比例patches提取非常适合,但是由于projection的时间原因,固定的比例是很难保证的。 如果要将不同比例考虑进去,sliding window的时间效益又将大打折扣。
- region proposal algorithm
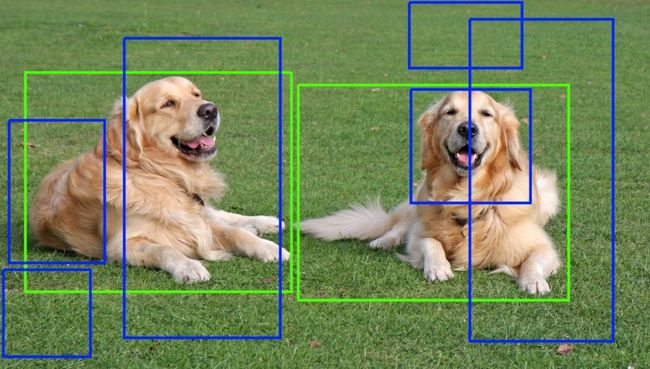 候选区域提取。绿框:真阳性 true positive 蓝框:假阳性 false positive
候选区域提取。绿框:真阳性 true positive 蓝框:假阳性 false positive
sliding window (受平移、尺度、比例影响)存在的根本问题就是漫无目的性的搜索, 恰恰region proposal algorithm就是为了解决这个问题。候选区域提取算法将图像作为输入,并输出边界框BoundingBox,该边界框对应于图像中最有可能是对象的所有patches。这些BoundingBox可能存在噪声、重叠,也可能偏离了目标,但是大多数候选区域应该与图像中的目标非常接近。这样,我们在后面直接对这些BoundingBox进行目标识别就好了。 在所有的region proposal algorithms中, selective search based 非常有代表性(快,有很高的召回率recall),进而提取BoundingBox。
- selective search
 原始的输入图像 采用graph-based适当分割结果 采用graph-based过分割结果
原始的输入图像 采用graph-based适当分割结果 采用graph-based过分割结果
selective search最核心的点在于通过颜色、文理、形状或者大小等 将原始的输入图像划分成等级区域(实质就是分割,如上图所示)。但是直接分割的图片不能用来做物体检测,原因有二:
1 大多数物体包含俩种以上的颜色(尤其受到光照影响,一个物体可能包含更丰富的颜色信息)
2 如果物体之间有重叠,这种方法无法处理,比如杯子放在盘子上的情况
为了更好地解决上面的两个问题,自然而然的我们想到了使用更好的分割方法,但是这并不是我们的目标(图像分割本来就是一个非常大的领域)。 我们这里需要的是一个不错的分割结果就好,至少需要满足分割后的区域可以尽可能的覆盖原图像中的物体。所以,selective search中使用了[1]中的分割算法进行过分割(如上图所示)。selective search将过分割图像作为初始输入,并执行以下步骤:
step 1:根据论文[1]分割的图片画出多个框,把所有框放入列表Region中
step 2:根据相似程度(颜色,纹理,大小,形状等),计算Region中框之间的俩俩形似度,把相似度放入列表A中
step 3:从列表A中找出相似度最大的俩个框a,b并且合并
Step 4:把合并的框加入列表Region中,从A中删除和a,b相关的相似度,重复步骤2,直至清空A
最终只需要对Region中的框进行图片分类,就可以得到原图的检测结果。候选框从数十万降到几千(R-CNN中俩千左右)。
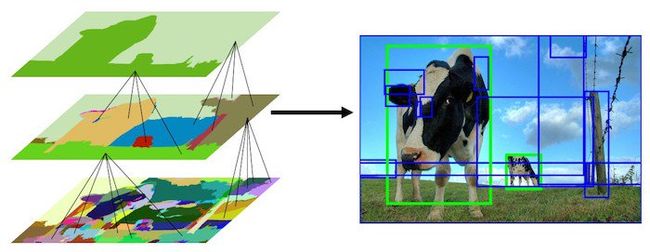 graph-base过分割后形成Hierarchy - bottom-up 策略。它显示了等级分割过程的初始、中间和最后一步
graph-base过分割后形成Hierarchy - bottom-up 策略。它显示了等级分割过程的初始、中间和最后一步
绿框:生成的真阳性边界框 true positive BoundingBox 蓝框:生成的假阳性边界框 false positive BoundingBox
- selective search 区域归并
那么如何计算两个区域之间的相似性? selective search运用了基于颜色、文理、形状、大小进行相似性度量。
颜色相似性:A color histogram of 25 bins is calculated for each channel of the image and histograms for all channels are concatenated to obtain a color descriptor resulting into a 25×3 = 75-dimensional color descriptor. 对于图像的每一个通道我们需要计算25bin的颜色直方图,然后每一个颜色通道的直方图拼接在一起,形成颜色描述子(75维)。
纹理相似性:对于图像的每个通道,利用高斯差分对8个方向进行计算提取纹理特征。对于每个颜色通道的每个方向,利用10-bin直方图进行表示,这样便形成了纹理描述子(10*8*3=240维)。
尺寸相似性:尺度相似性鼓励更小的区域早日合并。它确保在图像的所有部分形成所有尺度的候选区域。如果没有考虑这个相似度测度,那么一个区域会一个一个地吞噬所有较小的相邻区域,那么,多个比例的候选区域将只在特定的位置产生。
形状兼容性相似性:两个区域重合比例程度。
两个区域之间的最终相似度定义为上述4个相似点的线性组合。
Python+OpenCV的代码实现:https://download.csdn.net/download/shenziheng1/10751868。示例结果如下:
 selective search采用graph-based过分割生成的候选区域(region proposal): 降低了时间消耗,提升了候选区域的质量
selective search采用graph-based过分割生成的候选区域(region proposal): 降低了时间消耗,提升了候选区域的质量
 selective search采用graph-based过分割生成的候选区域(region proposal): 降低了时间消耗,提升了候选区域的质量
selective search采用graph-based过分割生成的候选区域(region proposal): 降低了时间消耗,提升了候选区域的质量
2. 从selective search 到 region proposal network的候选区域提取
- CNN对目标识别算法的革新
2012年论文[6]再次引燃神经网络并且开启以深度学习为主导的人工智能时代。[6]提出的AlexNet网络结构在ImageNet ILSVRC图片分类的比赛中夺得冠军,top-1的准确率达到57.1%,top-5 达到80.2%,突然之间手工设计的特征提取方法显得羸弱不堪,用卷积神经网络(CNN)来做特征提取成了大家的共识。 受到AlexNet影响[7]把CNN引入物体检测的领域,为了方便,研究学者把[7]方法简称为regions with CNN features,也就是R-CNN。
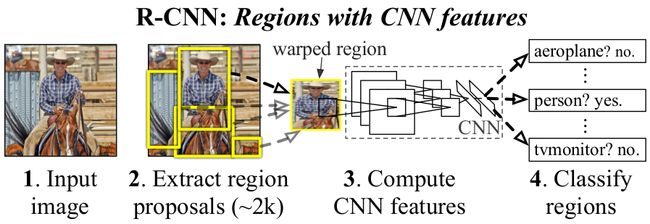 Region-CNN 目标检测框架示意图
Region-CNN 目标检测框架示意图
对输入的图片进行区域提取,文中用selective search。然后对每一块提取出来的区域缩放到统一的大小,输出CNN特征向量,用分类器(SVM,讨论了softmax的可行性)判断该区域是不是某类物体,接着对选出的区域做了框回归(bounding box regression)处理得到最后的结果:物体种类和框的位置。
这篇论文在当时也引起了轰动,主要在于两个方面:
1.利用CNN代替传统的手工特征,并证明了不同的CNN结构对检测效果很非常大的影响。如VGG-16的检测性能要比AlexNet效果好得多。
2.加入了根据CNN特征对边界框进行回归的方法。对比表明在SVM分类的结果上做框回归之后会把mAP再提高4个百分点。
网络训练采用的还是分段训练(这为后来的fast-RCNN 和 faster-RCNN提供了研究方向):
1.在ImageNet上pre-train一个图片分类的CNN(也可以用别人提供的比如AlexNet)
2.替换训练好的CNN分类层,比如从AlexNet的1000 类物体换成VOC的20+1类,继续fine tune训练
3.针对每一类目标物体训练一个one vs rest的SVM
4.使用CNN的输出做输入,训练一组参数做bounding-box regressor修正位置
关于为什么用SVM而不是直接采用Softmax进行分类?作者是利用大量的实验进行证明,但是由于起初训练没有关注正负样本均衡,所以在后面的Fast-RCNN算法中,直接又用Softmax替代了SVM,性能更好。
- BoundingBox回归
这里可能会好奇,讲了RCNN变更了目标识别算法,又讲到了BoundingBox回归网络,怎么还不讲Region Proposal Network? 其实,算法领域都是基于一个baseline进行一步一步改进的。所以非常有必要理解一下BoundingBox优化。
如果不BoundingBox Regression,输出的位置就是selective search选出的那个区域的位置,实际中是会存在偏差的如下图所示:
 红框: selective search 提供的 候选区域,该区域经过目标识别算法得到的置信值最大。 绿框:我们期待的结果,也是真实标注与selective search之间的差别。 改图说明了BoundingBox Regression模块的重要性。
红框: selective search 提供的 候选区域,该区域经过目标识别算法得到的置信值最大。 绿框:我们期待的结果,也是真实标注与selective search之间的差别。 改图说明了BoundingBox Regression模块的重要性。
selective search选出的可能是红色的框,ground truth是绿色的框,判断是否正确是用IoU的值来判断,输出红色框会影响到结果判断,但是已经把飞机检测出来了只要对红色框做线性变换(缩放+平移),就可以了。[7]认为,CNN输出的特征向量里包含了信息,所以在CNN输出的特征向量上做了一个loss计算,调整原来框的位置(相当于对原来的框加上缩放和平移操作)。所以每一个种类都设计了边界框回归BoundingBox Regression,只要设计一个好的loss函数,能学习到一组参数使loss收敛就可以啊。因此,loss的设计是关键。对于BoundingBox Regression 回归的具体做法,会单独研究。
- RCNN的弊端和改进方案
通过上面分析,我们就会发现,RCNN和之前的目标检测方法相比已经取得了长足的发展,但是仍然存在模型训练不合理、检测速度慢弊端。对于这样一个新奇的策略,必定会引起很多研究学者跟进。紧跟着就出现了SSPNet和Fast-RCNN的改进算法。
SSPnet:很好的解决了不同尺寸图像的训练问题,但是很可惜,该网络不能反向传播,所以前面的特征提取层和后圈的全连接分类层都需要单独训练。所以,SPP Net的设计让特征提取的时间成百上千倍的加快,缺点就是训练步骤麻烦。
Fast R-CNN:主要在训练步骤上做了优化,主要是俩个方面: 根据SPPNet 中的spp层改进设计了RoI Pooling,使用muti-task loss同时训练物体种类和位置。之前提到spp层不能进行反向传播,是由于金字塔的结构,Fast R-CNN就化用了SPPNet的方法,使用RoI Pooling,其实就是只用spp中金字塔的一层做池化,这样也能产生固定长度的特征向量,用来做分类。而且只用金字塔的一层做池化,就是一个池化操作了,那就可以做反向传播了。Fast R-CNN最大的贡献在于将目标分类和边界框回归一起做,用作者的观点就是:multi-task 。 核心还在如何设计 multi-task loss。 分类直接在原来CNN的基础上加入FC层和softmax即可; 框回归是让CNN的输出直接是bounding box regressor需要的4个比例。
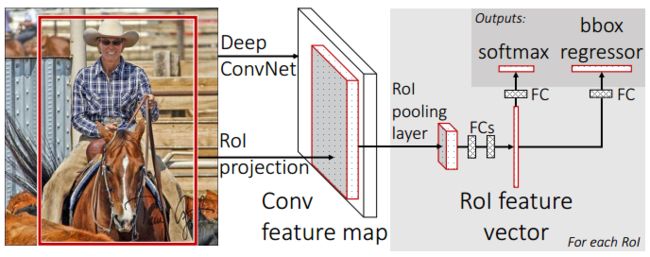 Fast R-CNN 检测:分类与位置同时执行的多任务框架
Fast R-CNN 检测:分类与位置同时执行的多任务框架
做到这里了,其实感觉已经很完美了。但是2015年,很多学者意识到 Most algorithms can benefit from end-to-end training. 其实这是很好理解的,深度学习本身就是基于数据驱动完成了算法的性能提升。如果算法框架是End-to-End的,那么各组分(诸如区域候选提取、特征提取、边界框回归等)应该耦合的更紧密。
回头看看,无论是SSP net 还是 Fast R-CNN改进,都没有对区域候选环节Region Proposal进行改变,都不约而同的采用了Selective search算法。以现在的眼光去比喻,有点像造好了一辆汽车(CNN),但是在用马(selective search)拉着跑的感觉。因为selective search的计算太慢了,想让物体检测达到实时,就得改造候选框提取的方法。 这都是Faster CNN要做的,统一区域候选提取、分类和边界框回归,实现检测算法的End-to-End.
- 锚点机制和区域候选网络设计
Faster RCNN[10]提出了一种方法,在网络中设计一个模块来提取候选框(region proposal networks),为什么要用网络实现?因为最初作者就抱着和分类网络共用部分CNN的目的。[10]有个很重要的概念:锚点。理解RPN的关键也就在锚点上。
锚点,字面理解就是标定位置的固定的点。在提框机制中,是预先设定好一些固定的点(anchor)和框(anchor box)的意思。如下图所示:
 Faster R-CNN中anchor的解释:假设图像上设定4个锚点(2x2),那么就可以看作2x2的格子,每个格子的中心叫做锚点。以锚点为中心,给定俩个宽高比(1:2, 2:1),画俩个框。绿色和红色的框就是锚点框(anchor box)。也就是说,每一个锚点都可以产生俩个锚点框,这些框就是固定在这里存在的,不会变也不会动。
Faster R-CNN中anchor的解释:假设图像上设定4个锚点(2x2),那么就可以看作2x2的格子,每个格子的中心叫做锚点。以锚点为中心,给定俩个宽高比(1:2, 2:1),画俩个框。绿色和红色的框就是锚点框(anchor box)。也就是说,每一个锚点都可以产生俩个锚点框,这些框就是固定在这里存在的,不会变也不会动。
当模型输出的预测位置是棕色虚线框时,计算预测框和每一个锚点框的误差。方法是:首先用bounding box regression的方法计算每一个anchor box 到真值框的偏移量 t1,每一个scale的anchor box都需要bounding box regressor; 再计算预测框到每一个anchor box的偏移量 t2 , 最后使回归损失L1(t1-t2)最小。
这里可能会产生一个问题,为什么不直接计算预测框和真值框的误差,而是要通过anchor作为中间传导呢?这和模型的输出有关系,RPN的输出位置信息并不是框的位置 (x, y, w, h),而是锚点框的偏移量 t2。因此需要学习 t2和 t1的误差最小。以上图为例,全图共4个锚点,每个锚点产生2个锚点框。所以一张图产生4×2=8个锚点框,RPN的输出是对每一个锚点框输出种类(前景后景)置信度 + 位置偏移量 t2,共8×(2+4)个值。
所以整个Fast R-CNN的算法流程为:
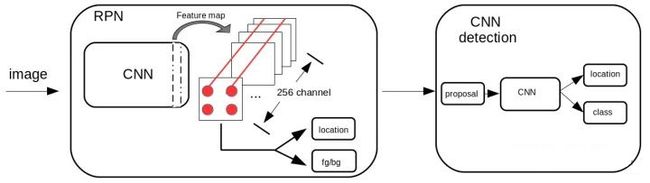 Faster R-CNN检测框架流图: 整个网络分为两个部分RPN + Detection。1. 输入图像,用CNN提特征,在CNN输出的特征图(feature map)上做anchor处理。2. 假设特征图通道数是256。那么特征图的尺寸就相当于设定了多少个锚点。例如,特征图长宽是13x13, 那就有169个锚点,每一个锚点按照论文中的说法可以产生9个锚点框,这9个锚点框共用一组1×256的特征,即锚点所在位置上所有通道的数据,接一个1×1的卷积核控制维度,
做位置回归和前后景判断,这就是RPN的输出。3. 在RPN的输出基础上,对所有anchor box的前景置信度排序,
挑选出前top-N的框作为预选框proposal, 继续CNN做进一步特征提取,最后再进行位置回归和物体种类判断。
Faster R-CNN检测框架流图: 整个网络分为两个部分RPN + Detection。1. 输入图像,用CNN提特征,在CNN输出的特征图(feature map)上做anchor处理。2. 假设特征图通道数是256。那么特征图的尺寸就相当于设定了多少个锚点。例如,特征图长宽是13x13, 那就有169个锚点,每一个锚点按照论文中的说法可以产生9个锚点框,这9个锚点框共用一组1×256的特征,即锚点所在位置上所有通道的数据,接一个1×1的卷积核控制维度,
做位置回归和前后景判断,这就是RPN的输出。3. 在RPN的输出基础上,对所有anchor box的前景置信度排序,
挑选出前top-N的框作为预选框proposal, 继续CNN做进一步特征提取,最后再进行位置回归和物体种类判断。
Faster R-CNN的训练方法有好几种,主要分为拆分训练和端到端训练。
拆分训练:先训练RPN,从所有anchor box中随机挑选256个,保持正样本负样本比例1:1(正样本不够时用负样本补);再从RPN的输出中,降序排列所有anchor box的前景置信度,挑选top-N个候选框叫做proposal, 做分类训练。
端到端训练:理论上可以做端到端的训练,但是由于anchor box提取的候选框中负样本占大多数,有的图中负样本和正样本的比例可以是1000:1, 导致直接训练难度很大。真正的端到端的目标检测网络还是有的,例如one-stage中代表的YOLO、SSD算法。速度很快,但是精度差了点。
Faster R-CNN最核心的工作在于在提取特征的过程中完成候选框提取的操作,大大加快了物体检测的速度。
3. 参考资料
1. 基于图的高效分割算法:Efficient Graph-Based Image Segmentation | IJCV2004
- http://cs.brown.edu/people/pfelzens/segment/
2. selective search 策略用于目标识别:Selective Search for Object Recognition | IJCV2013
- https://ivi.fnwi.uva.nl/isis/publications/2013/UijlingsIJCV2013/UijlingsIJCV2013.pdf
3. selective search策略用于目标检测:Selective Search for Object Detection | LearnOpenCV2017
- https://www.learnopencv.com/selecti-search-for-object-detection-cpp-python/
4. sliding window策略用于目标检测:Sliding Windows for Object Detection | PyimageSearch2015
5. 其他常用的region proposal algorithms:
- Objectness measure:http://groups.inf.ed.ac.uk/calvin/objectness/
- CPMC: Constrained Parametric Min-Cuts for Automatic Object Segmentation: http://www.maths.lth.se/matematiklth/personal/sminchis/code/cpmc/index.html
- Category Independent Object Proposals:http://vision.cs.uiuc.edu/proposals/
6. 神经网络迈向深度学习的大作:ImageNet Classification with Deep Convolution Neural Network | NIPS2012
- http://dblp.uni-trier.de/db/conf/nips/nips2012.html#KrizhevskySH12
7. RCNN用于目标检测论文:Rich features hierarchies for accurate object detection and semantic segmentation | CVPR2014
- http://128.84.21.199/abs/1311.2524
8. BoundingBox Regression:http://caffecn.cn/?/question/160
9. RCNN的第一批改进算法:
- SSPNet: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition | ECCV2014 + PAMI2015
- Fast R-CNN | ICCV2015 https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=7410526
10. End-to-End检测框架: Faster R-CNN | NIPS2016
- https://dl.acm.org/citation.cfm?id=2969239.2969250
- YOLO v1: You Only Look Once: Unified, Real-Time Object Detection | CVPR2016
- YOLO v2: YOLO9000: Better, Faster, Stronger | CVPR2017
- YOLO v3: YOLOv3: An Incremental Improvement | CVPR2018
- SSD: SSD: Single Shot MultiBox Detector | ECCV2016
- FPN: Feature Pyramid Networks for Object Detection | CVPR2017