吴恩达 第四章第1课 Tensorflow构建手势识别
安装Tensorflow,可参考https://www.cnblogs.com/lvsling/p/8672404.html
下载相关库文件,链接:https://pan.baidu.com/s/1y09QPMBK0EmbWBqru5Qddg
提取码:0pks
1 导入相关库文件(楼主这一段代码报警告,某些库以后将被移除,如果版本过高可能有些库不一样,可自行查阅对应版本,楼主用的python是3.7.3版本)
import math #用于数学运算
import numpy as np #numpy库,用于科学计算
import tensorflow as tf #tensorflow库
import h5py #用于读写数据
import matplotlib.pyplot as plt #matlab绘图
import matplotlib.image as mping #图像显示
from tensorflow.python.framework import ops
import cnn_utils #数据库函数
np.random.seed(1)
2 对训练集与测试集数据进行处理,主要是独热编码

(train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes)=cnn_utils.load_dataset()
"""
此段可用于查看训练集内图像
index=6
plt.imshow(train_set_x_orig[index])
print("y="+str(np.squeeze(train_set_y_orig[:,index])))
"""
X_train=train_set_x_orig/255
X_test=test_set_x_orig/255
Y_train=cnn_utils.convert_to_one_hot(train_set_y_orig,6).T
Y_test=cnn_utils.convert_to_one_hot(test_set_y_orig,6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
结果为:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
3 创建占位符,使用tensorflow之前我们需要先建立占位符,可以理解为先声明变量类型再使用。主要作用就是占位,系统会给它分配内存,等到Session运行时再通过feed_dict进行传值。其中X的维度为[None,n_H0,n_W0,n_C0],Y的维度为[None,n_y]
#创建占位符
def create_placeholders(n_H0,n_W0,n_C0,n_y):
#X维度为[none,n_H0,n_W0,n_C0] =维度为[数据量,高,宽,层数]
#Y维度为[none,n_y] =维度为[数据量,输出float]
X=tf.placeholder(tf.float32,(None,n_H0,n_W0,n_C0),name='X')
Y=tf.placeholder(tf.float32,(None,n_y),name='Y')
return X,Y
测试程序
X,Y=create_placeholders(64,64,3,5)
print("X="+str(X))
print("Y="+str(Y))
结果
X=Tensor("X:0", shape=(?, 64, 64, 3), dtype=float32)
Y=Tensor("Y:0", shape=(?, 5), dtype=float32)
4 参数进行初始化
可以通过tf.contrib.layers.xavier_initializer(seed = 0)对W1,W2进行初始化
#初始化权值矩阵
def initialize_parameters():
"""初始化W1,W2
W1:[4,4,3,8]
W2:[2,2,8,16]
返回字典parameters{"W1":W1,
"W2":W2}
"""
tf.set_random_seed(1)
W1=tf.get_variable("W1",[4,4,3,8],initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2=tf.get_variable("W2",[2,2,8,16],initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters={"W1":W1,
"W2":W2}
return parameters
测试程序:
tf.reset_default_graph()#清除默认图形堆栈并重置全局默认图形
with tf.Session() as sess:
parameters=initialize_parameters()
sess.run(tf.global_variables_initializer())
print("W1="+str(parameters["W1"].eval()[1,1,1]))
print("W2="+str(parameters["W2"].eval()[1,1,1]))
sess.close()
结果
W1=[ 0.00131723 0.1417614 -0.04434952 0.09197326 0.14984085 -0.03514394
-0.06847463 0.05245192]
W2=[-0.08566415 0.17750949 0.11974221 0.16773748 -0.0830943 -0.08058
-0.00577033 -0.14643836 0.24162132 -0.05857408 -0.19055021 0.1345228
-0.22779644 -0.1601823 -0.16117483 -0.10286498]
5 接下来我们搭建前向传播
CONV2D→RELU→MAXPOOL→CONV2D→RELU→MAXPOOL→FULLCONNECTED
使用tensorflow自带的函数
CONV2D:tf.nn.conv2d(X,W1,strides=[1,s,s,1],padding='SAME')输入X,维度为[m,n_H0,n_W0,n_C0] ,W1为卷积核,strides为步长;输出Z1,具体可参考点这里
RELU:tf.nn.relu(Z1),具体可参考。点这里
MAXPOOL:tf.nn.max_pool(A, ksize = [1,f,f,1], strides = [1,s,s,1], padding = 'SAME'),以步伐strides滑动取[f,f]内的最大值。点这里
压缩层:tf.contrib.layers.flatten(P1),将数据变为一维向量,然后返回一个tensor变量,其维度为(batch_size,k) 点这里
FC: tf.contrib.layers.fully_connected(P,num_outputs),全连接层,作用相当于之前的logit回归。详情点这里
代码
def forward_propagation(X,parameters):
W1=parameters["W1"]
W2=parameters["W2"]
#第一次卷积
Z1=tf.nn.conv2d(X,W1,strides=[1,1,1,1],padding="SAME")
#第一次RELU
A1=tf.nn.relu(Z1)
#MAX POOL 窗口大小为8x8
P1=tf.nn.max_pool(A1,ksize=[1,8,8,1],strides=[1,8,8,1],padding="SAME")
#第二次卷积
Z2=tf.nn.conv2d(P1,W2,strides=[1,1,1,1],padding="SAME")
#RELU
A2=tf.nn.relu(Z2)
#MAX POOL 窗口大小为4x4
P2=tf.nn.max_pool(A2,ksize=[1,4,4,1],strides=[1,4,4,1],padding="SAME")
#一维化
P=tf.contrib.layers.flatten(P2)
#全连接
Z3=tf.contrib.layers.fully_connected(P,6)
return Z3
测试程序
tf.reset_default_graph()
np.random.seed(1)
with tf.Session() as sess:
X,Y=create_placeholders(64,64,3,6)
parameters=initialize_parameters()
Z3=forward_propagation(X,parameters)
init=tf.global_variables_initializer()#初始化
sess.run(init)
a=sess.run(Z3,feed_dict={X:np.random.randn(2,64,64,3),Y:np.random.randn(2,6)})
print("Z3="+str(a))
sess.close()
结果
Z3=[[ 1.4416987 -0. 5.450499 -0. -0. 1.3654671]
[ 1.4070845 -0. 5.0892797 -0. -0. 1.2624857]]
6 定义损失函数
tf.nn.softmax_cross_entropy_with_logits(logits = Z3 , lables = Y)点这里
tf.reduce_mean(),求平均点这里
代码
def compute_cost(Z3,Y):
cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3,labels=Y))
return cost
测试程序
tf.reset_default_graph()
np.random.seed(1)
with tf.Session() as sess:
X,Y=create_placeholders(64,64,3,6)
parameters=initialize_parameters()
Z3=forward_propagation(X,parameters)
cost=compute_cost(Z3,Y)
init=tf.global_variables_initializer()
sess.run(init)
a=sess.run(cost,feed_dict={X:np.random.randn(2,64,64,3),Y:np.random.randn(2,6)})
print("cost="+str(a))
sess.close()
结果
cost=15.007429
7 构建模型
- 创建占位符
- 获得维度和初始化参数
- 前向传播
- 计算成本
- 反向传播
- 优化
优化函数自带反向传播,所以不需要计算反向传播
代码:
def model(X_train,Y_train,X_test,Y_test,learning_rate=0.005,
num_epochs=100,minibatch_size=64,print_cost=True,isPlot=True)
#CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FC
#X_train.Y_train,X_test,Y_test 训练集与测试集
#learning_rate 学习速率
#num_epochs 训练次数
#minibatch_size 最小块尺寸
#print_cost 是否打印成本
#isPlot 是否画cost图
#输出
#train_accuracy 训练集准确度
#test_accuracy 测试集准确度
#parameters 训练后参数值
ops.reset_default_graph()
seed = 3
(m,n_H0,n_W0,n_C0)=X_train.shape
n_y=Y_train.shape[1]
costs=[]
#X,Y占位
X,Y=create_placeholders(n_H0,n_W0,n_C0,n_y)
#初始化权值矩阵
parameters=initialize_parameters()
#前向传播
Z3=forward_propagation(X,parameters)
#计算损失函数
cost=compute_cost(Z3,Y)
#Adam优化
optimizer=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost=0
num_minibatches=int(m/minibatch_size)
seed=seed+1
minibatches=cnn_utils.random_mini_batches(X_train,Y_train,minibatch_size,seed)
for minibatch in minibatches:
(X_batch,Y_batch)=minibatch
#计算最小值
_,temp_cost=sess.run([optimizer,cost],feed_dict={X:X_batch,Y:Y_batch})
#累加损失函数
minibatch_cost+=temp_cost/num_minibatches
if print_cost == True:
if epoch%5 ==0:
print("当前是"+str(epoch)+"次,cost="+str(minibatch_cost))
if epoch % 1 == 0:
costs.append(minibatch_cost)
#绘制cost曲线
if isPlot:
plt.plot(np.squeeze(costs))
plt.xlabel("训练次数")
plt.ylabel("costs")
plt.title("learning_rate="+str(learning_rate))
plt.show
#预测准确率
predict_op=tf.arg_max(Z3,1)
correct_predict=tf.equal(predict_op,tf.arg_max(Y,1))
accuracy=tf.reduce_mean(tf.cast(correct_predict,"float"))
train_accuracy=accuracy.eval({X:X_train,Y:Y_train})
test_accuracy=accuracy.eval({X:X_test,Y:Y_test})
print("train_accuracy="+str(train_accuracy))
print("test_accuracy="+str(test_accuracy))
return (train_accuracy,test_accuracy,parameters)
测试
_, _, parameters = model(X_train, Y_train, X_test, Y_test,num_epochs=200)
结果
当前是0次,cost=1.9077872559428215
当前是5次,cost=1.8801930770277977
当前是10次,cost=1.7014926299452782
当前是15次,cost=1.5355006903409958
当前是20次,cost=1.4654902592301369
当前是25次,cost=1.4315431490540504
当前是30次,cost=1.4229949489235878
当前是35次,cost=1.4088741391897202
当前是40次,cost=1.3891217187047005
当前是45次,cost=1.3837406635284424
当前是50次,cost=1.3614463731646538
当前是55次,cost=1.3588715195655823
当前是60次,cost=1.3570115268230438
当前是65次,cost=1.3472109586000443
当前是70次,cost=1.3432847559452057
当前是75次,cost=1.3300637751817703
当前是80次,cost=1.332325056195259
当前是85次,cost=1.3283755891025066
当前是90次,cost=1.32537142932415
当前是95次,cost=1.317672960460186
当前是100次,cost=1.3297589495778084
当前是105次,cost=1.3149463906884193
当前是110次,cost=1.3129008114337921
当前是115次,cost=1.3173474222421646
当前是120次,cost=1.3659051060676575
当前是125次,cost=1.3370265737175941
当前是130次,cost=1.3129153326153755
当前是135次,cost=1.3106976449489594
当前是140次,cost=1.3092973306775093
当前是145次,cost=1.3130952939391136
当前是150次,cost=1.3110962882637978
当前是155次,cost=1.3181017190217972
当前是160次,cost=1.310841552913189
当前是165次,cost=1.3091500103473663
当前是170次,cost=1.3119462877511978
当前是175次,cost=1.3201691135764122
当前是180次,cost=1.3277232386171818
当前是185次,cost=1.3104218989610672
当前是190次,cost=1.3092177659273148
当前是195次,cost=1.3169310092926025
train_accuracy=0.3148148
test_accuracy=0.29166666
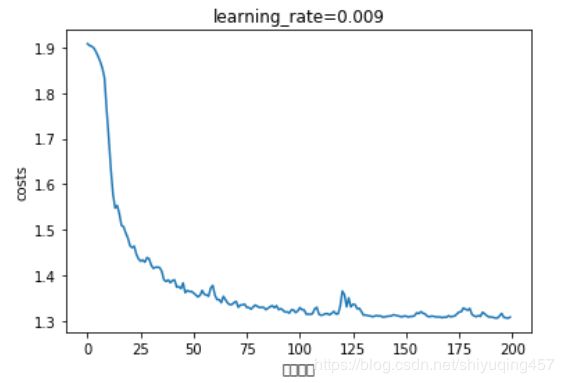
博主的训练结果很差,查阅资料说是版本不一样,可以从初始化和优化函数进行优化,如果有大神知道该怎么修改,欢迎留言指导,如果有什么问题可以留言提问,博主看见后会第一时间回复,大家有什么意见也可以提出来
本文参考博客:[https://blog.csdn.net/koala_tree/article/details/78525220](https://blog.csdn.net/koala_tree/article/details/78525220)
[https://blog.csdn.net/u013733326/article/details/80086090](https://blog.csdn.net/u013733326/article/details/80086090)