【机器学习实战-python3】利用SVD简化数据
本篇的数据和代码参见:https://github.com/stonycat/ML-in-Action
一、开篇:简述SVD应用
利用SVD实现,我们能够用小得多的数据集来表示原始数据集。这样做,实际上是去除了噪声和冗余信息。简而言之,SVD是一种从大量数据中提取主要关键数据的方法。
下面介绍几种应用场景:
1、隐性语义索引
最早的SVD应用之一就是信息检索。我们称利用SVD的方法为隐性语义索引(LatentSemantic Indexing,LSI)或隐性语义分析(Latent Semantic Analysis,LSA)。在LSI中,一个矩阵是由文档和词语组成的。应用SVD时,构建的SVD奇异值代表了文章的主题或者主要概念。
当我们查找一个词时,其同义词所在的文档可能并不会匹配上。如果我们从上千篇相似的文档中抽取出概念,那么同义词就会映射为同一概念。
2、推荐系统
简单版本的推荐系统能够计算项或者人之间的相似度。更先进的方法则先利用SVD从数据中构建一个主题空间,然后再在该空间下计算其相似度。
SVD是矩阵分解的一种类型,而矩阵分解是将数据矩阵分解为多个独立部分的过程。
二、矩阵分解
很多情况下,数据中的一小段携带了数据集中的大部分信息,其他信息则要么是噪声,要么就是毫不相关的信息。
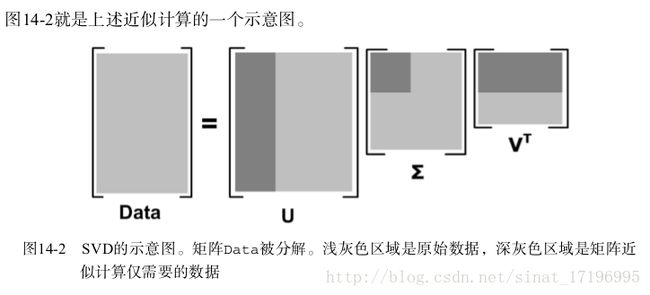
在线性代数中还有很多矩阵分解技术。矩阵分解可以将原始矩阵表示成新的易于处理的形式,这种新形式是两个或多个矩阵的乘积。
不同的矩阵分解技术具有不同的性质,其中有些更适合于某个应用,有些则更适合于其他应用。最常见的一种矩阵分解技术就是SVD。公式如下:
上述分解中会构建出一个矩阵 Σ ,该矩阵只有对角元素,其他元素均为0。另一个惯例就是,Σ 的对角元素是从大到小排列的。这些对角元素称为 奇异值(Singular Value),它们对应了原始数据集矩阵 Data 的奇异值。奇异值和特征值是有关系的。这里的奇异值就是矩阵 Data⋅DataT 特征值的平方根。
科学和工程中,一直存在这样一个普遍事实:在某个奇异值的数目( r 个)之后,其他的奇异值都置为0。这就意味着数据集中仅有 r个重要特征,而其余特征则都是噪声或冗余特征。
三、利用 Python 实现 SVD
NumPy有一个称为linalg的线性代数工具箱。接下来,我们了解一下如何利用该工具箱实现如下矩阵的SVD处理:
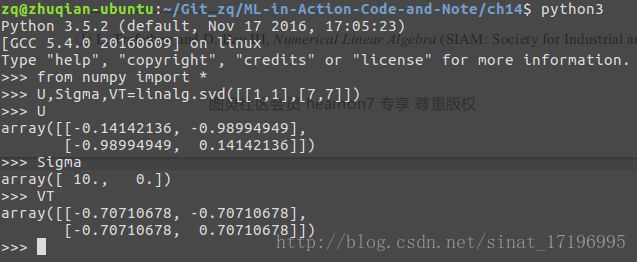
Sigma为了方便仅返回对角元素。
建立一个新文件 svdRec.py 并加入如下代码:
def loadExData():
return [[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]]测试:
>>> import svdRec
>>> Data=svdRec.loadExData()
>>> U,Sigma,VT=linalg.svd(Data)
>>> Sigma
array([ 9.64365076e+00, 5.29150262e+00, 8.36478329e-16,6.91811207e-17, 3.76946717e-34])
前 3 个数值比其他的值大了很多(如果你的最后两个值的结果与这里的结果稍有不同,也不必担心。它们太小了,所以在不同机器上产生的结果就可能会稍有不同,但是数量级应该和这里的结果差不多)。于是,我们就可以将最后两个值去掉了。数据表示为:
我们是如何知道仅需保留前 3 个奇异值的呢?确定要保留的奇异值的数目有很多启发式的策略,其中一个典型的做法就是保留矩阵中 90% 的能量信息。我们将所有的奇异值求其平方和,将平方和累加到总值的 90% 为止。
另一个启发式策略就是,当矩阵上有上万的奇异值时,那么就保留前面的 2000 或 3000 个。尽管后一种方法不太优雅,但是在实际中更容易实施。
现在我们已经通过三个矩阵对原始矩阵进行了近似。我们可以用一个小很多的矩阵来表示一个大矩阵。有很多应用可以通过 SVD 来提升性能。下面我们将讨论一个比较流行的 SVD 应用的例子 —— 推荐引擎。
四、基于协同过滤的推荐引擎
协同过滤( collaborative filtering )是通过将用户和其他用户的数据进行对比来实现推荐的,唯一所需要的数学方法就是相似度的计算。
1、相似度计算
利用用户对它们的意见来计算相似度:这就是协同过滤中所使用的方法。它并不关心物品的描述属性,而是严格地按照许多用户的观点来计算相似度。
我们希望,相似度值在 0 到 1 之间变化,并且物品对越相似,它们的相似度值也就越大。我们可以用“相似度 =1/(1+ 距离 ) ”这样的算式来计算相似度。当距离为 0 时,相似度为 1.0 。如果距离真的非常大时,相似度也就趋近于 0 。
1-距离采用欧式距离来计算(计算平方和)。
2-第二种计算距离的方法是皮尔逊相关系数( Pearson correlation )。
该方法相对于欧氏距离的一个优势在于,它对用户评级的量级并不敏感。比如某个狂躁者对所有物品的评分都是 5 分,而另一个忧郁者对所有物品的评分都是 1 分,皮尔逊相关系数会认为这两个向量是相等的。在 NumPy 中,皮尔逊相关系数的计算是由函数 corrcoef() 进行的,后面我们很快就会用到它了。皮尔逊相关系数的取值范围从 1 到 +1 ,我们通过 0.5 + 0.5*corrcoef() 这个函数计算,并且把其取值范围归一化到 0 到 1 之间。
3-余弦相似度 ( cosine similarity )
其计算的是两个向量夹角的余弦值。如果夹角为 90 度,则相似度为 0 ;如果两个向量的方向相同,则相似度为 1.0 。
其中 ∥A∥∥B∥ 为A、B的2范数。你可以定义向量的任一范数,但是如果不指定范数阶数,则都假设为 2 范数。
from numpy import *
from numpy import linalg as la
#相似度1:欧式距离
def ecludSim(inA,inB):
return 1.0/(1.0 + la.norm(inA - inB))
#相似度2:威尔逊距离
def pearsSim(inA,inB):
if len(inA) < 3 : return 1.0
return 0.5+0.5*corrcoef(inA, inB, rowvar = 0)[0][1]
#相似度3:余弦
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)#欧式距离
>>> myMat=mat(svdRec.loadExData())
>>> svdRec.ecludSim(myMat[:,0],myMat[:,4])
0.12973190755680383
>>> svdRec.ecludSim(myMat[:,0],myMat[:,0])
1.0
#威尔逊相关系数
>>> svdRec.pearsSim(myMat[:,0],myMat[:,4])
0.20596538173840329
>>> svdRec.pearsSim(myMat[:,0],myMat[:,0])
1.0
#余弦相似度
>>> svdRec.cosSim(myMat[:,0],myMat[:,4])
0.5
>>> svdRec.cosSim(myMat[:,0],myMat[:,0])
1.0
2、基于物品的相似度还是基于用户的相似度?

上图:行与行之间比较的是基于用户的相似度,列与列之间比较的则是基于物品的相似度。到底使用哪一种相似度呢?
这取决于用户或物品的数目。
基于物品相似度计算的时间会随物品数量的增加而增加,基于用户的相似度计算的时间则会随用户数量的增加而增加。
如果用户的数目很多,那么我们可能倾向于使用基于物品相似度的计算方法。对于大部分产品导向的推荐引擎而言,用户的数量往往大于物品的数量,即购买商品的用户数会多于出售的商品种类。
3、推荐引擎的评价
如何对推荐引擎进行评价呢?此时,我们既没有预测的目标值,也没有用户来调查他们对预测的满意程度。这里我们就可以采用前面多次使用的交叉测试的方法。具体的做法就是,我们将某些已知的评分值去掉,然后对它们进行预测,最后计算预测值和真实值之间的差异。
通常用于推荐引擎评价的指标是称为最小均方根误差( Root Mean Squared Error , RMSE )的指标,它首先计算均方误差的平均值然后取其平方根。
五、示例:餐馆菜肴推荐引擎
构建一个基本的推荐引擎,它能够寻找用户没有尝过的菜肴。然后,通过 SVD 来减少特征空间并提高推荐的效果。这之后,将程序打包并通过用户可读的人机界面提供给人们使用。
(1) 寻找用户没有评级的菜肴,即在用户-物品矩阵中的 0 值;
(2) 在用户没有评级的所有物品中,对每个物品预计一个可能的评级分数。这就是说,我们
认为用户可能会对物品的打分(这就是相似度计算的初衷);
(3) 对这些物品的评分从高到低进行排序,返回前N个物品。
下述代码:遍历数据行中的每个物品。如果某个物品评分值为 0 ,就意味着用户没有对该物品评分,跳过了这个物品。该循环大体上是对用户评过分的每个物品进行遍历,并将它和其他物品进行比较。
但是如果存在重合的物品,则基于这些重合物品计算相似度。随后,相似度会不断累加,每次计算时还考虑相似度和当前用户评分的乘积。最后,通过除以所有的评分总和,对上述相似度评分的乘积进行归一化。这就可以使得最后的评分值在 0 到 5 之间,而这些评分值则用于对预测值进行排序。
#遍历 计算相似度
def standEst(dataMat, user, simMeas, item):#数据矩阵、用户编号、相似度计算方法和物品编号
n = shape(dataMat)[1]
simTotal = 0.0;ratSimTotal = 0.0
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0: continue
#寻找两个用户都做了评价的产品
overLap = nonzero(logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0]
if len(overLap) == 0:
similarity = 0
else:#存在两个用户都评价的产品 计算相似度
similarity = simMeas(dataMat[overLap, item], dataMat[overLap, j])
print ('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity #计算每个用户对所有评价产品累计相似度
ratSimTotal += similarity * userRating #根据评分计算比率
if simTotal == 0:
return 0
else:
return ratSimTotal / simTotal
#推荐实现:recommend() 产生了最高的 N 个推荐结果
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user, :].A == 0)[1] #寻找用户未评价的产品
if len(unratedItems) == 0: return ('you rated everything')
itemScores = []
for item in unratedItems:
estimatedScore = estMethod(dataMat, user, simMeas, item)#基于相似度的评分
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N]recommend()函数在所有的未评分物品上进行循环。对每个未评分物品,则通过调用standEst() 来产生该物品的预测得分。该物品的编号和估计得分值会放在一个元素列表itemScores 中。最后按照估计得分,对该列表进行排序并返回。
测试:
>>> reload(svdRec)
'svdRec' from '/home/zq/Git_zq/ML-in-Action-Code-and-Note/ch14/svdRec.py'>
>>> myMat=mat(svdRec.loadExData())
>>> myMat[0,1]=myMat[0,0]=myMat[1,0]=myMat[2,0]=4
>>> myMat[3,3]=2
>>> myMat
matrix([[4, 4, 0, 2, 2],
[4, 0, 0, 3, 3],
[4, 0, 0, 1, 1],
[1, 1, 1, 2, 0],
[2, 2, 2, 0, 0],
[5, 5, 5, 0, 0],
[1, 1, 1, 0, 0]])
>>> svdRec.recommend(myMat,2)
the 1 and 0 similarity is: 1.000000
the 1 and 3 similarity is: 0.928746
the 1 and 4 similarity is: 1.000000
the 2 and 0 similarity is: 1.000000
the 2 and 3 similarity is: 1.000000
the 2 and 4 similarity is: 0.000000
[(2, 2.5), (1, 2.0243290220056256)]
这表明了用户 2 (由于我们从 0 开始计数,因此这对应了矩阵的第 3 行)对物品 2 的预测评分值为 2.5 ,对物品 1 的预测评分值为 2.05 。
下面利用 SVD 提高推荐的效果
>>> from numpy import linalg as la
>>> U,Sigma,VT=la.svd(mat(svdRec.loadExData2()))
>>> Sigma
array([ 15.77075346, 11.40670395, 11.03044558, 4.84639758,
3.09292055, 2.58097379, 1.00413543, 0.72817072,
0.43800353, 0.22082113, 0.07367823])
>>> Sig2=Sigma**2 #计算平方和
>>> sum(Sig2)
541.99999999999955
>>> sum(Sig2)*0.9 #取前90%
487.79999999999961
>>> sum(Sig2[:3]) #>90% SVD取前三个特征值
500.50028912757932下述程序中包含有一个函数 svdEst() 。在 recommend() 中,这个函数用于替换对 standEst() 的调用,该函数对给定用户给定物品构建了一个评分估计值。
#利用SVD
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0;ratSimTotal = 0.0
U, Sigma, VT = la.svd(dataMat) #不同于stanEst函数,加入了SVD分解
Sig4 = mat(eye(4) * Sigma[:4]) # 建立对角矩阵
xformedItems = dataMat.T * U[:, :4] * Sig4.I #降维:变换到低维空间
#下面依然是计算相似度,给出归一化评分
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item: continue
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
print ('the %d and %d similarity is: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
return ratSimTotal / simTotal
>>> svdRec.recommend(myMat,1,estMethod=svdRec.svdEst)
the 1 and 0 similarity is: 0.498142
the 1 and 3 similarity is: 0.498131
the 1 and 4 similarity is: 0.509974
the 2 and 0 similarity is: 0.552670
the 2 and 3 similarity is: 0.552976
the 2 and 4 similarity is: 0.217301
[(2, 3.4177569186592378), (1, 3.3307171545585641)]
构建推荐引擎面临的挑战
SVD 分解可以在程序调入时运行一次。在大型系统中, SVD 每天运行一次或者其频率更低,并且还要离线运行。
1-推荐引擎中还存在其他很多规模扩展性的挑战性问题,比如矩阵的表示方法。在上面给出的例子中有很多 0 ,实际系统中 0 的数目更多。也许,我们可以通过只存储非零元素来节省内存和计算开销?
2-一个潜在的计算资源浪费则来自于相似度得分。在我们的程序中,每次需要一个推荐得分时,都要计算多个物品的相似度得分,这些得分记录的是物品之间的相似度。因此在需要时,这些记录可以被另一个用户重复使用。在实际中,另一个普遍的做法就是离线计算并保存相似度得分。
3-推荐引擎面临的另一个问题就是如何在缺乏数据时给出好的推荐。这称为冷启动 ( cold-start )问题,冷启动问题的解决方案,就是将推荐看成是搜索问题。
为了将推荐看成是搜索问题,我们可能要使用所需要推荐物品的属性。在餐馆菜肴的例子中,我们可以通过各种标签来标记菜肴,比如素食、美式 BBQ 、价格很贵等。同时,我们也可以将这些属性作为相似度计算所需要的数据,这被称为基于内容( content-based )的推荐。可能,基于内容的推荐并不如我们前面介绍的基于协同过滤的推荐效果好,但我们拥有它,这就是个良好的开始。
六、示例:基于 SVD 的图像压缩
在代码库中,我们包含了一张手写的数字图像,该图像在第 2 章使用过。原始的图像大小是 32×32=1024 像素,我们能否使用更少的像素来表示这张图呢?如果能对图像进行压缩,那么就可以节省空间或带宽开销了。我们可以使用 SVD 来对数据降维,从而实现图像的压缩。
#实例:SVD实现图像压缩
#打印矩阵。由于矩阵包含了浮点数,因此必须定义浅色和深色。
def printMat(inMat, thresh=0.8):
for i in range(32):
for k in range(32):
if float(inMat[i,k]) > thresh:
print 1,
else: print 0,
print ('')
#压缩
def imgCompress(numSV=3, thresh=0.8):
myl = []
for line in open('0_5.txt').readlines():
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = mat(myl)
print ("****original matrix******")
printMat(myMat, thresh)
U,Sigma,VT = la.svd(myMat) #SVD分解得到特征矩阵
SigRecon = mat(zeros((numSV, numSV))) #初始化新对角矩阵
for k in range(numSV):#构造对角矩阵,将特征值填充到对角线
SigRecon[k,k] = Sigma[k]
reconMat = U[:,:numSV]*SigRecon*VT[:numSV,:]#降维
print ("****reconstructed matrix using %d singular values******" % numSV)
printMat(reconMat, thresh)imgCompress()函数基于任意给定的奇异值数目来重构图像。该函数构建了一个列表,然后打开文本文件,读入字符。
接下来就开始对原始图像进行SVD分解并重构图像。在程序中,通过将 Sigma 重新构成 SigRecon 来实现这一点。 Sigma 是一个对角矩阵,因此需要建立一个全0矩阵,然后将前面的那些奇异值填充到对角线上。最后,通过截断的 U 和 V T 矩阵,用 SigRecon 得到重构后的矩阵,该矩阵通过 printMat() 函数输出。
小结
VD 是一种强大的降维工具,我们可以利用 SVD 来逼近矩阵并从中提取重要特征。通过保留矩阵 80% ~ 90% 的能量,就可以得到重要的特征并去掉噪声。
在大规模数据集上, SVD 的计算和推荐可能是一个很困难的工程问题。通过离线方式来进行SVD 分解和相似度计算,是一种减少冗余计算和推荐所需时间的办法。
在下一章中,我们将介绍在大数据集上进行机器学习的一些工具。