DPCNN深度金字塔卷积神经网络介绍
目录
1 概述
2 模型结构
2.1 卷积(等长卷积)
2.2 池化(Downsampling and polling)
2.3 近路连接(shortcut connect)
2.4 Text region embedding
1 概述
DPCNN(Deep Pyramid Convolutional Neural Networksfor Text Categorization),是RieJohnson等提出的一种深度卷积神经网络,可以称之为"深度金字塔卷积神经网络"。
在DPCNN的工作之前,研究者们认为,word-level词级embedding优于char-level字级(严格意义上来说,elmo、gpt-2、bert、xlnet等是字(char)、词(word)和句子(sentence)级别的混合体,所以不算);CNN在图像领域的成功也表明,深度卷积神经网络能够提取更加复杂和高级的特征,尤其是深度残差网络(ResNet)等的流行。那么,深度卷积神经网络在自然语言处理NLP领域,究竟有没有优势呢?
elmo、gpt-2、bert和xlNet的出现,说明深度神经网络在自然语言处理NLP领域,也是很有必要的,不过,这个主角可能不是CNN,而是Attention。
唉,还是NLP任务的字符、词等是离散的数据结构呀,这和图像连续的像素、颜色等具有本质的区别。
闲话不多说,我们还是来说说卷积神经网络CNN和DPCNN吧。
通过TextCNN、DCNN、Bi-LSTM,我们已经知道,句子顺序对于自然语言处理NLP任务具有很非常重要的作用,从直观上看,道理也是这样子的,尤其是对于短文本来说。
在DPCNN之前,研究者们已经证明在char-level的深度卷积神经网络中,更深的模型效果更好,不过,由于word词太多、深度网络太复杂,常常会导致模型过大、参数太多、运行较慢、梯度爆炸和消失等问题。
2 模型结构
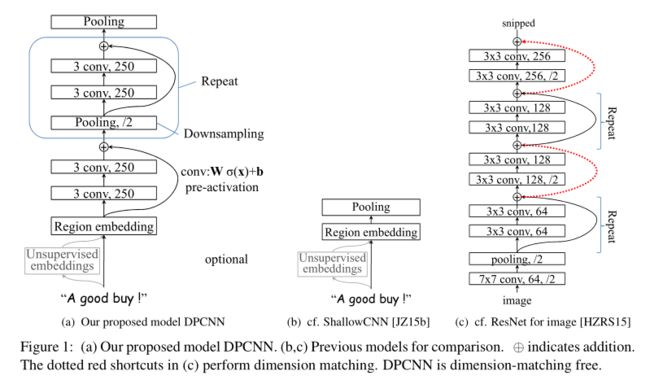
DPCNN主要由 A. Redion embedding层(文本区域嵌入层)、
B. 两个convolution block(每层block由两个固定卷积核为3的conv卷积函数构成)(两个block构建的层可以通过pre-activation直接连接)、
C. Repeat结构,与B很相似,只不过在conv之前、pre-activate之后加了个Max-polling层
2.1 卷积(等长卷积)
不同于TextCNN的窄卷积(VALID),也不同于DCNN中的宽卷积(wide),DPCNN中的卷积使用等长卷积(SAME),顾名思义,就是输出的卷积长度与输入的一样,步长一样是1,不同的是padding补零,为两端补零pad_size=(m-1)/2 ,m为卷积核尺寸。
为什么要固定feature maps的数量呢? 许多模型每当执行池化操作时,增加feature maps的数量,导致总计算复杂度是深度的函数。与此相反,作者对feature map的数量进行了修正,他们实验发现增加feature map的数量只会大大增加计算时间,而没有提高精度。
固定了feature map的数量,每当使用一个size=3和stride=2进行maxpooling进行池化时,每个卷积层的计算时间减半(数据大小减半),从而形成一个金字塔。
2.2 池化(Downsampling and polling)
等长卷积后,再固定feature maps的数量(减少计算量等),再进行池化。池化,在每个卷积块后(block)结束之后,对特征合集做一个池化,池化用的是最大池化(pool_size=3, stride=2),使每个卷积核的维度减半,形成一个金字塔结构。你可以发现,很多文本匹配相似度计算也是会用到该方法。因为这种压缩式的Downsampling,可以拼接等实现文本远距离信息匹配于对应,还是有一定效果的。

2.3 近路连接(shortcut connect)
网络太深会有以下问题:
初始化CNN的时,往往各层权重都初始化为很小的值,这导致了最开始的网络中,后续几乎每层的输入都是接近0,这时的网络输出没有意义;
小权重阻碍了梯度的传播,使得网络的初始训练阶段往往要迭代好久才能启动;
就算网络启动完成,由于深度网络中仿射矩阵(每两层间的连接边)近似连乘,训练过程中网络也非常容易发生梯度爆炸或弥散问题。
所以, 论文参考ResNet, 采用Shorcut connection, 这样就可以极大的缓解了梯度消失问题.
另外, 在做卷积运算时, 作者采用了pre-activation的做法.也就是说, 卷积运算是![]() , 而不是通常用的
, 而不是通常用的![]() , 直观上,这种“线性”简化了深度网络的训练.
, 直观上,这种“线性”简化了深度网络的训练.
2.4 Text region embedding
从图中的a和c的对比可以看出,DPCNN与ResNet差异还是蛮大的。同时DPCNN的底层貌似保持了跟TextCNN一样的结构,这里作者将TextCNN的包含多尺寸卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对一个文本区域/片段(比如3gram)进行一组卷积操作后生成的embedding。
对一个3gram进行卷积操作时可以有两种选择,一种是保留词序,也就是设置一组size=3*D的二维卷积核对3gram进行卷积(其中D是word embedding维度);还有一种是不保留词序(即使用词袋模型),即首先对3gram中的3个词的embedding取均值得到一个size=D的向量,然后设置一组size=D的一维卷积核对该3gram进行卷积。显然TextCNN里使用的是保留词序的做法,而DPCNN使用的是词袋模型的做法,DPCNN作者argue前者做法更容易造成过拟合,后者的性能却跟前者差不多
References
Deep Pyramid Convolutional Neural Networks for Text Categorization阅读笔记
从DPCNN出发,撩一下深层word-level文本分类模型