Go语言学习笔记---函数的详细用法
文章目录
- 函数
- 声明函数
- 参数类型的简写
- 函数的返回值
- 函数变量---把函数作为值保存在变量中
- 匿名函数---没有函数名字的函数
- 在定义时调用匿名函数
- 将匿名函数赋值给变量
- 用作回调函数
- 使用匿名函数实现操作封装
- 函数实现接口---把函数作为接口调用
- 结构体实现接口
- 函数体实现接口
- 闭包---引用了外部变量的匿名函数
- 可变参数---参数数量不固定的函数形式
- 获得可变参数类型---获得每一个参数的类型
- 在多个可变参数函数中传递参数
- 延迟执行语句---defer
- 多个defer语句的处理顺序
- defer和匿名函数和闭包相见
- 使用延迟执行语句在函数退出时释放资源
- 使用延迟并发解锁
- 使用延迟释放文件句柄
- 处理运行时发生的错误
- 宕机(panic)---程序终止运行
- 宕机恢复(recover)---防止程序崩溃
函数
函数是组织好的、可重复使用的,实现单一或者相关功能的代码段,其可以提高应用的模块性和代码的重复利用率。
- 函数本身可以作为值进行传递
- 支持匿名函数和闭包
- 函数可以作为接口
声明函数
func 函数名(参数列表)(返回参数列表){
函数体
}
参数类型的简写
在参数列表中,如有多个参数变量,则以逗号分隔:如果相邻变量是同类型,则可以省略,如:
func add(a,b int) int{
return a+b
}
函数的返回值
Go语言支持多返回值,经常使用多返回值中的最后一个返回参数返回函数执行中可能发生的错误。示例:
conn,err := connectToNetwork()
返回值有几种类型:
同一种类型的返回值:
func typeTwoValues() (int,int){
return 1,2
}
带有变量名的返回值:
//对两个整型返回值命名,分别为a和b
func namedRetValues() (a,b int){
a=1
b=2
return
}
注意:
- 返回值的默认值为类型的默认值,即数值为0,字符串为空字符串,布尔为false,指针为nil等
- 同一种类型的返回值和命名返回值只能二选一
如func namedRetValues() (a,b int,int)是错误的。
3.调用函数,格式如下:
返回值变量列表 =函数名(参数列表)
result := add(1,2)
函数变量—把函数作为值保存在变量中
因为在GO语言中,函数也是一种类型,可以和其他类型一样被保存在变量中。
示例:
package main
import (
"fmt"
)
func fire() {
fmt.Println("fire")
}
func main() {
var f func()
f = fire
f()
}
匿名函数—没有函数名字的函数
匿名函数没有函数名,只有函数体,函数可以被作为一种类型被赋值给函数类型的变量,匿名函数也往往以变量方式被传递。
应用场景:经常被用于实现回调函数,闭包等。
定义格式:
func(参数列表) (返回参数列表){
}
匿名函数的调用方法有以下几种:
在定义时调用匿名函数
func(data int){
fmt.Println("hello",data)
}(100)
//这个(100)表示对匿名函数进行调用,传递参数100
将匿名函数赋值给变量
匿名函数体可以被赋值,例如:
f :=func(data int){
fmt.Println("hello",data)
}
f(100)
用作回调函数
下面代码实现对切片遍历中访问每个元素的操作,使用匿名函数来实现。
package main
import (
"fmt"
)
//遍历切片的每个元素,通过给定函数进行元素访问
func visit(list []int, f func(int)) {
for _, v := range list {
f(v)
}
}
func main() {
//使用匿名函数打印切片内容
visit([]int{1, 2, 3, 4}, func(v int) {
fmt.Println(v)
})
}
使用匿名函数实现操作封装
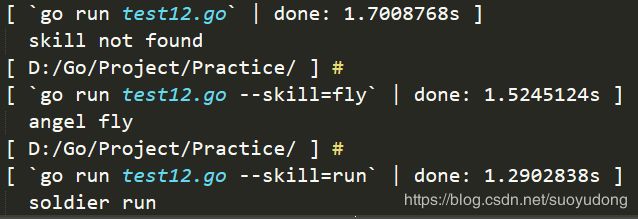
将匿名函数作为map的键值,通过命令行参数动态调用匿名函数,代码如下:
package main
import (
"flag"
"fmt"
)
var skillParam = flag.String("skill", "", "skill to perform")
func main() {
flag.Parse()
//map[string]func()类型
var skill = map[string]func(){
//初始化
"fire": func() {
fmt.Println("chicken fire")
},
"run": func() {
fmt.Println("soldier run")
},
"fly": func() {
fmt.Println("angel fly")
},
}
//将解析出的skillparam里的命令行通过map中的键值获取相应的函数
if f, ok := skill[*skillParam]; ok {
f()
} else {
fmt.Println("skill not found")
}
}
函数实现接口—把函数作为接口调用
结构体实现接口
package main
import (
"fmt"
)
//调用器接口
type Invoker interface {
Call(interface{})
}
//定义结构体Invoker接口
type Struct struct {
}
//实现Invoker方法,p为接口,可以是任意类型
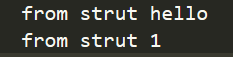
func (s *Struct) Call(p interface{}) {
fmt.Println("from strut", p)
}
func main() {
var invoker Invoker
//实例化结构体
s := new(Struct)
//将实例化的结构体赋值到接口上
invoker = s
invoker.Call("hello")
invoker.Call(1)
}
输出:
函数体实现接口
package main
import (
"fmt"
)
//调用器接口
type Invoker interface {
Call(interface{})
}
//函数定义为类型
type FuncCaller func(interface{})
//实现Invoker的call
func (f FuncCaller) Call(p interface{}) {
f(p)
}
func main() {
var invoker Invoker
//将匿名函数转为FuncCaller类型,再赋值给接口
invoker = FuncCaller(func(v interface{}) {
fmt.Println("from function", v)
})
invoker.Call("hello")
}
闭包—引用了外部变量的匿名函数
闭包:引用了自由变量的函数,被引用的自由变量和函数一同存在,即使已经离开了自由变量的环境也不会被释放或者删除,在闭包中可以继续使用这个自由变量.
简单的说:
闭包=函数+引用环境

闭包在其他的编程环境里叫Lambda表达式。
闭包的用法:
闭包在它作用域上部变量的引用可以进行修改,修改引用的变量就会对变量进行实际修改。例如:
//准备一个字符串
str :="hello world"
//创建一个匿名函数
foo := func(){
//在匿名函数中访问str
str ="hello dude"
}
//调用匿名函数
foo()
输出:hello dude
闭包的记忆效应:被捕获到闭包中的变量让闭包本身拥有了记忆效应,闭包中的逻辑可以修改闭包捕获的变量,变量会跟随闭包生命周期一直存在。
示例:累加器
package main
import (
"fmt"
)
//提供一个值,每次调用函数会指定对值进行累加
func Accumulate(value int) func() int {
//返回一个闭包
return func() int {
//累加
value++
//返回一个累加值
return value
}
}
func main() {
//创建一个累加器,初始化值为1
accumulator := Accumulate(1)
//累加1并打印
fmt.Println(accumulator())
//创建一个累加器,初始化值为10
accumulator2 := Accumulate(10)
//累加1并打印
fmt.Println(accumulator2())
}
输出:2 11
示例2:闭包实现生成器
package main
import (
"fmt"
)
//创建一个玩家生成器,输入名称,输出生成器
func playerGen(name string) func() (string, int) {
//血量一直为150
hp := 150
//返回创建的闭包
return func() (string, int) {
//将变量引用到闭包中
return name, hp
}
}
func main() {
//创建一个玩家生成器
generator := playerGen("high noon")
//返回玩家的名字和血量
name, hp := generator()
fmt.Println(name, hp)
}
输出:high noon 150
可变参数—参数数量不固定的函数形式
Go语言支持可变参数特性,函数声明和调用时没有固定数量的参数,同时也提供了一套方法进行可变参数的多级传递。
可变参数格式如下:
func 函数名(固定参数列表, v …T) (返回参数列表){
}
特性如下:
- 可变参数一般放置在函数列表的末尾,前面是固定参数列表,当没有固定参数时,所有变量就将是可变参数.
- v为可变参数变量,类型为[]T,也就是拥有多个T元素的T类型切片,v和T之间由"…"即3个点组成。
- T为可变参数的类型,当T为interface{}时,传入的可以是任意类型。
遍历可变参数列表—获取每一个参数的值
可变参数列表的数量不固定,参数列表是切片类型。如果需要获得每一个参数的具体值时,可以对可变参数变量进行遍历。
package main
import (
"bytes"
"fmt"
)
//定义一个函数,参数是0-n,类型约束为字符串,返回string类型
func joinString(slist ...string) string {
//定义一个字节缓冲,快速的连接字符串
var b bytes.Buffer
//遍历可变参数列表slist,类型为[]string,每一个参数类型为string 类型
for _, s := range slist {
//将遍历的字符串连续写入字节数组
b.WriteString(s)
}
//将连接好的字节数组转换为字符串进行输出
return b.String()
}
func main() {
//输入3个字符串,将它们连成一个字符串
fmt.Println(joinString("pig ", "and ", "rat "))
}
输出: ping and rat
如果要获得可变参数列表的长度,可以使用len()函数。
获得可变参数的类型—获得每一个参数的类型
获得可变参数类型—获得每一个参数的类型
当可变参数为interface{}类型时,可以传入任何类型的值。此时,如果需要获得变量的类型,可以通过switch类型分支获得变量的类型。
示例:打印变量类型和值
package main
import (
"bytes"
"fmt"
)
func printTypeValue(slist ...interface{}) string {
//字节缓冲作为快速字符串连接
var b bytes.Buffer
//遍历参数
for _, s := range slist {
//将interface{}类型格式化为字符串
str := fmt.Sprintf("%v", s)
//类型的字符串描述
var typestring string
//对s进行类型描述
switch s.(type) {
case bool:
typestring = "bool"
case string:
typestring = "string"
case int:
typestring = "int"
}
//写值字符串前缀
b.WriteString("value: ")
//写入值
b.WriteString(str)
b.WriteString("type: ")
b.WriteString(typestring)
b.WriteString("\n")
}
return b.String()
}
func main() {
fmt.Println(printTypeValue(100, "str", true))
}
输出:

在多个可变参数函数中传递参数
可变参数变量是一个包含所有参数的切片。
如果要在多个可变参数中传递参数,可以在传递时在可变参数变量中默认添加"…",将切片中的元素进行传递,而不是传递可变参数变量本身。
示例:可变参数传递
package main
import (
"fmt"
)
func rawprint(rawList ...interface{}) {
//遍历可变参数
for _, s := range rawList {
//打印
fmt.Println(s)
}
}
func print(slist ...interface{}) {
//传递可变参数,使用...进行传递与切片间使用append是一个特性
rawprint(slist...)
}
func main() {
print(1, 2, 3)
}
输出:
1
2
3
延迟执行语句—defer
作用:Go语言defer语句会将其后面跟随的语句进行延迟处理。
顺序:逆序执行,即先被defer的语句最后被执行,最后被defer的语句,最先被执行。
多个defer语句的处理顺序
示例:
package main
import (
"fmt"
)
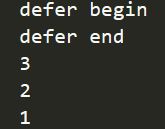
func main() {
//没有加defer第一个被执行
fmt.Println("defer begin")
//将defer放入延迟调用栈
defer fmt.Println(1)
defer fmt.Println(2)
//最后一个放入,位于栈顶,最先调用
defer fmt.Println(3)
//没有加defer,第二个被执行
fmt.Println("defer end")
}
输出:
defer和匿名函数和闭包相见
看这样一个例子:
package main
import (
"fmt"
)
func main() {
for i := 0; i < 3; i++ {
defer func() {
fmt.Println(i)
}()
}
}
在这种情况下会输出什么呢?
答案是:
3 3 3
上述代码中defer后面的语句可能看起来有些奇怪,其实完全可以把它看成这个样子:
defer a()
将匿名函数可以看成一个变量,这样看就不奇怪了。
为什么是3呢?
是因为闭包在引用i,而后面如果没有()的话是作为参数传递进去的,运行到defer的时候进行拷贝,会输出2 1 0。而后面加上()时是作为地址在引用这个局部变量,所以它在退出循环体的时候,这个变量已经变成了3,而在main函数return的时候,我们开始执行defer,这时我们3次打印出来都是3.
使用延迟执行语句在函数退出时释放资源
应用场景:处理业务或逻辑中涉及成对操作是一件比较繁琐的事情,比如打开和关闭文件、接收请求和回复请求、加锁和解锁等。在这些操作中,最容易忽略的就是在每个函数退出处正确的释放和关闭资源。
defer语句正好是在函数退出时执行的语句,所以使用defer能非常方便的处理资源释放问题。
使用延迟并发解锁
在函数中并发使用map,为防止竞态,使用sync.Mutex进行加锁,比如
var (
// 一个演示用的映射
valueByKey = make(map[string]int)
// 保证使用映射时的并发安全的互斥锁
valueByKeyGuard sync.Mutex
)
// 根据键读取值
func readValue(key string) int {
// 对共享资源加锁
valueByKeyGuard.Lock()
// 取值
v := valueByKey[key]
// 对共享资源解锁
valueByKeyGuard.Unlock()
// 返回值
return v
}
使用Go中的defer就能对其进行简化:
func readValue(key string) int {
valueByKeyGuard.Lock()
// defer后面的语句不会马上调用, 而是延迟到函数结束时调用
defer valueByKeyGuard.Unlock()
return valueByKey[key]
}
使用延迟释放文件句柄
只需要在打开文件之后使用defer 后面调用close,之后defer后的语句将会在函数返回前被调用,自动释放资源。
如:
f,err :=os.Open(filename)
defer f.close()
处理运行时发生的错误
Go语言的错误处理思想设计包含以下特征:
- 一个可能造成错误的函数,需要返回值中返回一个错误接口(error)。如果调用时成功的,错误接口将返回nil,否则返回错误。
- 在函数调用之后需要检查错误,如果发生错误,进行必要的错误处理。
错误接口的定义格式:
type error interface{
Error() string
}
所有符合Error()string格式的方法,都可以实现错误接口。
Error()方法返回错误的具体描述,使用者可以通过这个字符串知道发生了什么错误。
除0错误示例代码:
package main
import (
"errors"
"fmt"
)
//定义除数为0的错误
var errDivisionByZero = errors.New("division by zero")
func div(dividend, division int) (int, error) {
//判断除数为0的情况并返回
if division == 0 {
return 0, errDivisionByZero
}
//正常计算,返回空错误
return dividend / division, nil
}
func main() {
fmt.Println(div(1, 0))
}
在解析中使用自定义错误:示例
内容:实现一个解析错误,这种错误包含两个内容:文件名和行号。解析错误的结构还实现了error接口的Error()方法,返回错误时,就需要将文件名和行号返回。
package main
import (
"fmt"
)
//声明一个解析错误
type ParseError struct {
Filename string //文件名
Line int //行号
}
//实现error接口,返回错误描述
func (e *ParseError) Error() string {
return fmt.Sprintf("%s:%d", e.Filename, e.Line)
}
//创建一些解析错误
func newParseError(filename string, line int) error {
return &ParseError{filename, line}
}
func main() {
var e error
//创建一个错误实例,包含文件名和行号
e = newParseError("main.go", 1)
//通过error接口查看错误描述
fmt.Println(e.Error())
//根据错误接口的具体类型,获取详细的错误信息
switch detail := e.(type) {
case *ParseError:
fmt.Printf("Filename:%s Line:%d\n", detail.Filename, detail.Line)
default:
fmt.Println("other error")
}
}
输出:

宕机(panic)—程序终止运行
panic的意义:宕机可能造成体验停止,服务中断,所以给用户的体验感非常不好,但是宕机有时候也是一种合理的止损方法。
1.手动触发宕机
如何触发宕机?用内建函数panic()就可以造成崩溃,panic声明如下
func panic(v interface{})
//例如:
func main(){
panic("crash")
}
手动宕机进行报错的方式不是一种偷懒的行为,反而能够迅速报错,终止程序继续运行,防止更大的错误产生。
2.运行依赖的必备资源缺失时主动触发宕机
编译正则表达式函数有两种:
第一种:
func Compile(expr string) (*Regexp,error)
发生错误时返回编译错误,Regexp为nil。
第二种:
func MustComplie(str string) *Regexp{
regexp,err :=Compile(str)
if err !=nil{
panic('regexp:Complie('+quote(str)+'):'+error.Error())
}
return regexp
}
使用panic触发宕机。
3.在宕机时触发延迟执行语句
panic()函数前面已经运行的defer语句依然会在宕机发生时发生作用。
宕机恢复(recover)—防止程序崩溃
- 无论是代码运行错误由Runtime层抛出的panic崩溃,还是主动触发的panic崩溃,都可以配合defer和recover实现错误捕捉和恢复,让代码在发生崩溃后允许继续运行。
让程序在崩溃时继续运行:
使用defer和recover函数,它们两的关系
- 有panic没有recover,程序宕机
- 有panic也有recover捕获,程序不会宕机。执行完对应的defer之后,从宕机点退出当前函数后继续执行。
- panic可以在任何地方引发,但recover只有在defer调用的函数中有效。
一个示例看清楚:
package main
import (
"fmt"
)
func A() {
fmt.Println("FuncA")
}
//在函数B这块使用panic
func B() {
panic("FuncB")
}
func C() {
fmt.Println("FuncC")
}
func main() {
A()
B()
C()
}
在这种情况下当运行到函数B的时候就会宕机,输出如下:
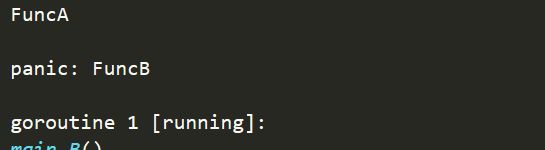
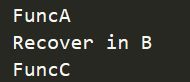
那么怎样让函数能进行一个正常恢复运行呢?答案就是运用recover
package main
import (
"fmt"
)
func A() {
fmt.Println("FuncA")
}
//在函数B这块使用panic
func B() {
//提前使用defer进行延迟执行,然后进行判断,如果发现panic信息进行recover
defer func() {
if err := recover(); err != nil {
fmt.Println("Recover in B")
}
}()
panic("FuncB")
}
func C() {
fmt.Println("FuncC")
}
func main() {
A()
B()
C()
}
输出如下: