排序算法(01)— 三种简单排序(冒泡、插入、选择)
一、概述
排序是数据处理中十分常见且核心的操作,虽说实际项目开发中很小几率会需要我们手动实现,毕竟每种语言的类库中都有n多种关于排序算法的实现。但是了解这些精妙的思想对我们还是大有裨益的。
1.1 排序的基本概念和分类
假设含有n个记录的序列为{r1,r2,…,rn},其相应的关键字分别为{k1,k2,…,kn},需确定1,2,。。。。,n的一种排列p1,p2,…,pn,使其相应的关键字满足kp1<=kp2<=kp3…<=kpn非递减(或非递增)关系,即使得序列成为一个按关键字有序的序列,这样的操作就称为排序。
1.1.1 排序的稳定性
腾讯校招2016笔试题曾考过
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
常见稳定排序算法:
基数排序、冒泡排序、直接插入排序、折半插入排序、归并排序
常见不稳定排序算法:
堆排序、快速排序、希尔排序、直接选择排序
稳定排序算法优点:
排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就 是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
1.1.2 内排序与外排序
根据排序过程中,待排序的记录是否被全部放置在内存中,排序分为:内排序和外排序。
内排序:在排序整个过程中,待排序的所有记录全部被放置在内存中
外排序:由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进行。我们主要介绍的内排序的多种算法。
根据排序过程中借助的主要操作,我们把内排序分为:插入排序、交换排序、选择排序和归并排序。
1.2 排序用到的结构与函数
1.2.1 数据结构
为了讲清楚排序算法的代码,我们就先提供一个用于排序的顺序表结构,以后的排序算法也会用到这个结构
#define MAXSIZE 10 //用于要排序数组个数最大值,可根据需要修改
typedef struct
{
int r[MAXSIZE +1]; //用于存储要排序的数组,r[0]用于哨兵或临时变量
int length; //用于记录顺序表的长度
}SqList;
1.2.2 交换函数
由于排序最常用到的函数就是数组交换,所以我们就把它单独提出来作为一个函数
/* 交换 L 中数组r的下标为 i 和 j 的值 */
void swap(SqList *L, int i, int j)
{
int temp = L->r[i];
L->r[i] = L->r[j];
L->r[j] = temp;
}
二、冒泡排序
2.1 基本思想
冒泡排序(Bubble Sort) 是一种极其简单的排序算法,也是我所学的第一个排序算法。它重复地走访过要排序的元素,依次比较相邻两个元素,如果他们的顺序错误就把他们调换过来,直到没有元素再需要交换,排序完成。这个算法的名字由来是因为越小(或越大)的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序算法的运作如下:
1. 比较相邻的元素,如果前一个比后一个大,就把它们两个调换位置。
2. 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
3. 针对所有的元素重复以上的步骤,除了最后一个。
4. 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
假设L = { 6, 5, 3, 1, 8, 7, 2, 4 }进行冒泡排序的实现过程如下


2.2 核心实现
void BubbleSort(SqList * L)
{
int i,j;
for (i = 1; i < L->length; i ++)
{
for (j = L->length - 1; j >= i; j --) // 注意 j 是从后往前循环
{
if (L->r[j] > L->r[j + 1]) // 如果前者大于后者
{
swap(L, j, j + 1); // 进行交换
}
}
}
}
三、简单选择排序
3.1 基本思想
选择排序(Selection Sort) 也是一种简单直观的排序算法。它的工作原理很容易理解:初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
注意选择排序与冒泡排序的区别:冒泡排序通过依次交换相邻两个顺序不合法的元素位置,从而将当前最小(大)元素放到合适的位置;而选择排序每遍历一次都记住了当前最小(大)元素的位置,最后仅需一次交换操作即可将其放到合适的位置。
比如对L = { 8, 5, 2, 6, 9, 3, 1, 4, 0, 7 }进行选择排序的实现过程如下所示
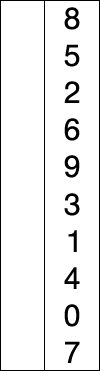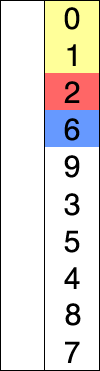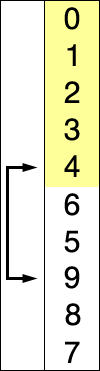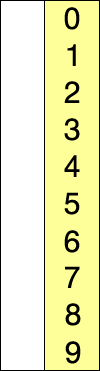
使用选择排序为一列数字进行排序的宏观过程:

选择排序是不稳定的排序算法,不稳定发生在最小元素与A[i]交换的时刻。
比如序列:{ 5, 8, 5, 2, 9 },一次选择的最小元素是2,然后把2和第一个5进行交换,从而改变了两个元素5的相对次序。
3.2 核心实现
/* 简单选择排序 */
void SelectSort(SqList * L)
{
int i,j,min;
for (i = 1; i < L->length; i ++)
{
min = i; /* 将当前下标定义为最小值下标 */
for (j = i+1; j <= L->length; j ++)
{
if (L->r[min] > L->r[j]) /* 如果有小于当前最小值的关键字*/
min = j; /* 将此关键字的下标赋值给min */
}
if (i != min) /* 若min不等于i,说明找到最小值,交换 */
swap(L, i, min);
}
}
四、插入排序
4.1 基本思想
插入排序是一种简单直观的排序算法。它的工作原理非常类似于我们抓扑克牌。
对于未排序数据(右手抓到的牌),在已排序序列(左手已经排好序的手牌)中从后向前扫描,找到相应位置并插入。
插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
具体算法描述如下:
1. 从第一个元素开始,该元素可以认为已经被排序
2. 取出下一个元素,在已经排序的元素序列中从后向前扫描
3. 如果该元素(已排序)大于新元素,将该元素移到下一位置
4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5. 将新元素插入到该位置后
6. 重复步骤2~5
插入排序不适合对于数据量比较大的排序应用。但是,如果需要排序的数据量很小,比如量级小于千,那么插入排序还是一个不错的选择。 插入排序在工业级库中也有着广泛的应用,在STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)。
假设对L = { 6, 5, 3, 1, 8, 7, 2, 4 }进行插入排序的实现过程如下:

使用插入排序为一列数字进行排序的宏观过程:

4.2 核心实现
/* 直接插入排序 */
void InsertSort(SqList * L)
{
int i,j;
for (i = 2; i <= L->length; i ++) {
if (L ->r[i] < L->r[i-1])
{
L->r[0] = L->r[i]; /* 设置哨兵 */
for (j = i-1; L->r[j] > L->r[0]; j --)
L->r[j+1] = L->r[j]; /* 记录后移 */
L->r[j+1] = L->r[0]; /* 插入到正确的位置 */
}
}
}
虽然这三个排序的时间复杂度都为 O(n2),但是,简单选择排序的性能上略优于冒泡排序,直接插入排序比冒泡和简单选择排序的性能要更好一些。
今天时间关系先给大家介绍这三种最基本也是最简单的排序算法,以后再给大家介绍希尔排序、堆排序等等
相关连接:基础算法(1) — 快速排序算法
参考文档
[1]严蔚敏、吴伟民. 数据结构(C语言版). 北京:清华大学出版社,1997
[2]程杰. 大话数据结构. 北京:清华大学出版社,2011