HashMap集合中的put()和putIfAbsent()的理解
序言
关于Map集合大家都不陌生,最常用的无非就是HashMap,TreeMap,大家都知道,Map是用于键值对key->value的形式来保存数据的,所以我们最熟悉的方法莫过于map的put方法,map的put方法有好几个,可能会有一些人会搞不懂,我就把自己的对这些put方法的理解记录一下,如果有哪里不对的还请各位大神帮忙提出来,在这我先谢谢各位了,不喜欢,请不要骂我,毕竟我也是自己学习的,下面开始就带大家一起来了解一下,这些put方法都是干啥的。
方法
-
put方法
V put(K key, V value) -
putIfAbsent方法
V putIfAbsent(K key, V value)
概述
首先,HashMap基于Map接口实现,元素以键值对的方式存储并且允许使用null 建和null,但是Map的Key不允许重复,所以只能有一个Key为null,这两个方法其实都是像map中添加数据,那有朋友可能会说了,我们都有put方法了,为什么还要有putIfAbsent方法呢,这不是多此一举么?其实我们再想想,怎么会无缘无故新增加几个方法呢,肯定是有目的的,那么我们来深入理解一下他们两个之间的区别,首先我们知道Map底层的实现是通过采用数组+链表+红黑树实现来实现的,HashMap在之前的时候是数据结构的存储由数组+链表的方式,后来在jdk1.8中变化为数组+链表+红黑树的存储方式,当链表长度超过阈值(8)时,将链表转换为红黑树(图是借鉴了网上的,大家不要介意):

源码
看了上面的数据结构,应该能明白Map是怎么来保存数据的了,可能刚开始我自己还没有弄清楚,如果能明白上面的存储方式,我们再来看一下它的源码,这样就能加快我们的理解,不明白上面的数据结构也不要紧,大家可以自己查查资料,我们来看下他们两个的源码,然后在进行下一步分析:
- put():
@Override
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
- putIfAbsent
@Override
public V putIfAbsent(K key, V value) {
return putVal(hash(key), key, value, true, true);
}
目前这么一看,两个方法都调用了putval(),好像没啥区别,等等,貌似第四个参数不一样,恩,我们看一下putval()这个方法都做了些什么?
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
//如果onlyIfAbsent为false并且oldValue为null,我们便对我们的value进行保存
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
你们看到了什么,put()和putIfAbsent() 都是通过这个方法实现了数据的存储,我们来看下,putval() 的第四个参数做了什么样的判断:
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
我们可以看到putval() 的第四个参数在这段代码里面的第二个if语句里面做了判断,如果onlyIfAbsent 为false并且oldValue 为null的情况下,就对我们当前传进来的value进行保存,这是为什么呢?上面这段代码的e.value 其实就是Node的value,可能大家觉得这块不太好理解,我们再来看下这两个方法运行的结果,来进行辅助理解。
###代码示例
public class Main {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("1", "1");
System.out.println(map.putIfAbsent("1", "2"));
System.out.println(map.get("1"));
System.out.println(map.put("1", "3"));
System.out.println(map.get("1"));
}
}
这段代码很简单,我们在map里面保存了一组数据,1->1,然后我们在用System.out.println 分别输出一下put和putIfAbsent之后的key=1所对应的value的值,我们看下运行结果:
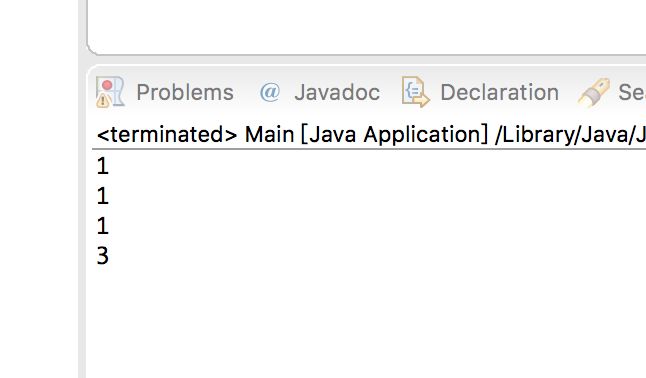
我们看到运行结果,是不是我们所期望的结果呢?首先putIfAbsent() 并没有将value的1替换掉为2,还是为1,但是我们用put() 方法却把value的1替换为3了,说明什么,说明我们如果用putIfAbsent()保存数据的时候,如果该链表中保存的有相同key的值,那么就不会对我们当前的value进行保存,如果用put()存储数据的时候,不管是该链表中是否有当前需要存储的key都会保存,我们所要保存的当前key所对应的value,看注释就很明白了。
也会有朋友说,那既然这样,还不如put方法来得快呢,我们来看下,官方的解释:
/**
* If the specified key is not already associated with a value (or is mapped
* to {@code null}) associates it with the given value and returns
* {@code null}, else returns the current value.
*
* @implSpec
* The default implementation is equivalent to, for this {@code
* map}:
*
* {@code
* V v = map.get(key);
* if (v == null)
* v = map.put(key, value);
*
* return v;
* }
*
* The default implementation makes no guarantees about synchronization
* or atomicity properties of this method. Any implementation providing
* atomicity guarantees must override this method and document its
* concurrency properties.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with the specified key, or
* {@code null} if there was no mapping for the key.
* (A {@code null} return can also indicate that the map
* previously associated {@code null} with the key,
* if the implementation supports null values.)
* @throws UnsupportedOperationException if the {@code put} operation
* is not supported by this map
* (optional)
* @throws ClassCastException if the key or value is of an inappropriate
* type for this map
* (optional)
* @throws NullPointerException if the specified key or value is null,
* and this map does not permit null keys or values
* (optional)
* @throws IllegalArgumentException if some property of the specified key
* or value prevents it from being stored in this map
* (optional)
* @since 1.8
*/
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
这段代码是map里面关于putIfAbsent() 方法的定义,官方的解释就是:
If the specified key is not already associated with a value (or is mapped to null) associates it with the given value and returns null, else returns the current value.
如果指定的键未与某个值关联(或映射到null),则将其与给定值关联并返回null,否则返回当前值。
官方还有这样一句话:默认的实现对该方法的同步或原子性质没有保证。提供原子性的保证任何的实现必须重写此方法和文件的并发性能。
这里说的很清楚,如果要实现并发,则必须重写该方法,这样的话,其用法就很明白了。
###结语
好了,今天的介绍就到这里,我想这两个方法,大家都有所了解了,他们的作用也了然于心了,有什么不懂得可以留言讨论,我会及时给大家解答。