sklearn.feature_extraction.text 中的 TfidfVectorizer 实现过程
对于NLP,已经学习一年了,可是一直有一个问题困扰着我,终于忍无可忍,决定将问题解决掉。
首先,介绍一下我的问题:
对于TFIDF算法,当利用训练集训练完成分类器,利用分类器进行训练时,如果测试集中只有一个文档,TFIDF数据是如何生成的?
这个问题可能对于很多人来说,很简单。但是对于我来说着实很纠结。
1. TFIDF算法基础知识
TF-IDF(Term Frequency-InversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。
- TF(Term Frequency)表示某个关键词在整篇文章中出现的频率。
- IDF(InversDocument Frequency)表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
计算方法:通过将局部分量(词频)与全局分量(逆文档频率)相乘来计算tf-idf,并将所得文档标准化为单位长度。文件中的文档中的非标准权重的公式,如图:
![]()
知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
分开的步骤
- (1)计算词频

- (2)计算逆文档频率

- (3)计算TF-IDF
![]()
2. sklearn.feature_extraction.text 中的 TFIDF(TfidfVectorizer )实现
2.1 训练集和测试集均含有一个以上的文件
- (1)代码实现
from sklearn.feature_extraction.text import TfidfVectorizer
train_document = ["The flowers are beautiful.","The name of these flowers is rose, they are very beautiful.", "Rose is beautiful", "Are you like these flowers?"]
test_document = ["The flowers are mine.", "My flowers are beautiful"]
#利用函数获取文档的TFIDF值
print("计算TF-IDF权重")
transformer = TfidfVectorizer()
X_train = transformer.fit_transform(train_document)
X_test = transformer.transform(test_document)
#观察各个值
#(1)统计词列表
word_list = transformer.get_feature_names() # 所有统计的词
print("统计词列表")
print(word_list)
#(2)统计词字典形式
print("统计词字典形式")
print(transformer.fit(test_document).vocabulary_)
#(3)TFIDF权重
weight_train = X_train.toarray()
weight_test = X_test.toarray()
print("train TFIDF权重")
print(weight_train)
print("test TFIDF权重")
print(weight_test)
#(4)查看逆文档率(IDF)
print("train idf")
print(transformer.fit(train_document).idf_)
下图为上述代码输出的相应结果:

- (2)计算步骤
此处以第一个文档为例,探讨sklearn中 TFIDF 是如何计算的。
![]()
首先,计算词频(TF )。此处的 tf 是词在一个文本出现的次数。
对于第一个文档中,其词频矩阵为:
词表:are beautiful flowers is like name of rose the these they very you
词频: 1 1 1 0 0 0 0 0 1 0 0 0 0
其次,计算逆文档率(IDF)。idf 指一个词在所有文本出现的值,其中idf在scikit-learn用下式计算:
![]()
其中,![]() 为总的文档数,
为总的文档数,![]() 是包含词 t 的文档数。
是包含词 t 的文档数。
对于上述代码,训练集中共有4个文档,分别为:
- "The flowers are beautiful."
- "The name of these flowers is rose, they are very beautiful."
- "Rose is beautiful"
- "Are you like these flowers?"
对于字符 “are”,其存在于 3 个文档中,则字符 “are”的 idf 为:
![]()
对于字符 “beautiful”,其存在于 3 个文档中,则字符 “are”的 idf 为:
![]()
对于字符 “flowers”,其存在于 3 个文档中,则字符 “are”的 idf 为:
![]()
对于字符 “the”,其存在于 2 个文档中,则字符 “are”的 idf 为:
![]()
对照上述代码中的输出结果,我们计算的结果是正确的。代码中的对数是以e为底进行计算的。
之后,计算TFIDF值。TFIDF = 频率 * 逆文档率。
字符 “are”的 tf-idf 为:
![]()
字符 “beautiful”的 tf-idf 为:
![]()
字符 “flowers”的 tf-idf 为:
![]()
字符 “the”的 tf-idf 为:
![]()
最后,进行归一化。在计算完文档中每个字符的tfidf之后,使用 Euclidean norm 对其进行归一化,将值保留在0-1之间。
![TFIDF('document1')=\frac{[1.22314355, 1.22314355, 1.22314355, 1.51082562]}{\sqrt{1.22314355^2+1.22314355^2+1.22314355^2+1.51082562^2}} =[0.4700632841717594, 0.4700632841717594, 0.4700632841717594, 0.5806216725381333]](http://img.e-com-net.com/image/info8/235e9f3f1d834db394355cbe037def04.gif)
计算过程的python代码其实很简单:
import math
idf1 = math.log(5/4) + 1
idf2 = math.log(5/3) + 1
print(idf1)
print(idf2)
v = math.sqrt(idf*idf*3 + idf2*idf2)
t1 = idf/v
t2 = idf2/v
print(t1, t2)2.2 测试集含有一个文件
- (1)代码实现
from sklearn.feature_extraction.text import TfidfVectorizer
train_document = ["The flowers are beautiful.","The name of these flowers is rose, they are very beautiful.", "Rose is beautiful", "Are you like these flowers?"]
test_document = ["The flowers are mine."]
#利用函数获取文档的TFIDF值
print("计算TF-IDF权重")
transformer = TfidfVectorizer()
X_train = transformer.fit_transform(train_document)
X_test = transformer.transform(test_document)
#观察各个值
#(1)统计词列表
word_list = transformer.get_feature_names() # 所有统计的词
print("统计词列表")
print(word_list)
#(2)统计词字典形式
print("统计词字典形式")
print(transformer.fit(test_document).vocabulary_)
#(3)TFIDF权重
weight_train = X_train.toarray()
weight_test = X_test.toarray()
print("train TFIDF权重")
print(weight_train)
print("test TFIDF权重")
print(weight_test)
#(4)查看逆文档率(IDF)
print("train idf")
print(transformer.fit(train_document).idf_)
print("test idf")
print(transformer.fit(test_document).idf_) 输出结果:

对于测试集,按照上述介绍的计算过程,由于词频与逆文档率均相同,则计算出来的结果其值应该均相等:
![]()
(注:由于词 mine 并不在词表中,所以在进行统计时并没有此词,所以这里测试集中的值均为3个,而非4个)。
但是,程序输出的结果却并不是如上计算出的结果。
如果认真看待代码,你就会发现:
同样是求TFIDF,训练集使用的是 fit_transform 函数,而测试集使用的是 transform 函数。
这就是导致算出的结果与程序中给出的不同的原因。
- (2)sklearn模块中fit_transform()函数和transform()函数之间的区别
先说结论
- fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式,一般应用在训练集中。
- tranform()的作用是通过找中心和缩放等实现标准化,一般用在测试集中。
我们先来看一下这两个函数的API以及参数含义:
1、fit_transform()函数
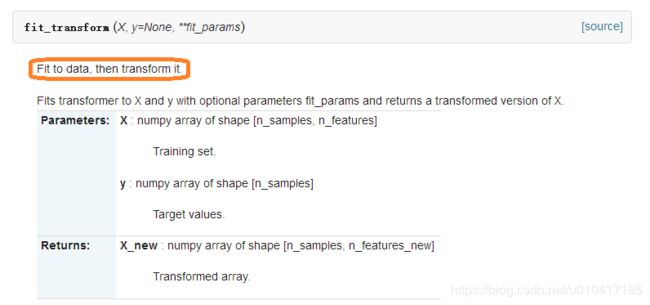
即fit_transform()的作用就是先拟合数据,然后转化它将其转化为标准形式
2、transform()函数
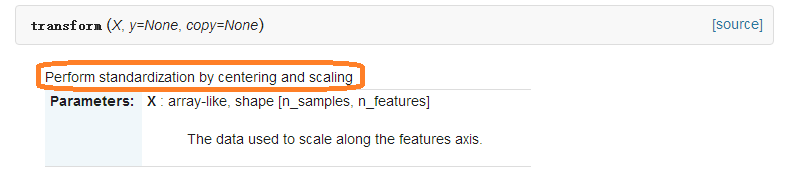
即tranform()的作用是通过找中心和缩放等实现标准化
到了这里,我们似乎知道了两者的一些差别,就像名字上的不同,前者多了一个fit数据的步骤,那为什么在标准化数据的时候不适用fit_transform()函数呢?
原因如下:
为了数据归一化(使特征数据方差为1,均值为0),我们需要计算特征数据的均值 和方差
和方差 ,再使用下面的公式进行归一化:
,再使用下面的公式进行归一化:

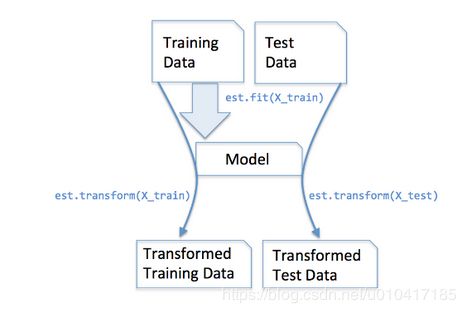
我们在训练集上调用fit_transform(),其实找到了均值和方差,即我们已经找到了转换规则,我们把这个规则利用在训练集上,同样,我们可以直接将其运用到测试集上(甚至交叉验证集),所以在测试集上的处理,我们只需要标准化数据而不需要再次拟合数据。用一幅图展示如下: