解释一下关系数据库的第一第二第三范式?(转自知乎
首先要明白”范式(NF)”是什么意思。按照教材中的定义,范式是“符合某一种级别的关系模式的集合,表示一个关系内部各属性之间的联系的合理化程度”。很晦涩吧?实际上你可以把它粗略地理解为 一张数据表的表结构所符合的某种设计标准的级别。就像家里装修买建材,最环保的是E0级,其次是E1级,还有E2级等等。数据库范式也分为1NF,2NF,3NF,BCNF,4NF,5NF。一般在我们设计关系型数据库的时候,最多考虑到BCNF就够。符合高一级范式的设计,必定符合低一级范式,例如符合2NF的关系模式,必定符合1NF。
接下来就对每一级范式进行一下解释,首先是 第一范式(1NF)。
符合1NF的关系(你可以理解为数据表。“关系”和“关系模式”的区别,类似于面向对象程序设计中”类“与”对象“的区别。”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构。 1NF的定义为:符合1NF的关系中的每个属性都不可再分。表1所示的情况,就不符合1NF的要求。
<img src="https://pic1.zhimg.com/24afd11455ac34a280fa83e4e8d75ccc_b.jpg" data-rawwidth="743" data-rawheight="157" class="origin_image zh-lightbox-thumb" width="743" data-original="https://pic1.zhimg.com/24afd11455ac34a280fa83e4e8d75ccc_r.jpg">表1
 表1
表1
实际上, 1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。如果我们要在RDBMS中表现表中的数据,就得设计为 表2的形式:
<img src="https://pic3.zhimg.com/6b735fb9503b0930e741faa474fed28e_b.jpg" data-rawwidth="881" data-rawheight="136" class="origin_image zh-lightbox-thumb" width="881" data-original="https://pic3.zhimg.com/6b735fb9503b0930e741faa474fed28e_r.jpg">表2
 表2
表2
但是仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如对于 表3中的设计:
<img src="https://pic3.zhimg.com/5b16f655b57a957bfa340d0a996a0eea_b.jpg" data-rawwidth="661" data-rawheight="349" class="origin_image zh-lightbox-thumb" width="661" data-original="https://pic3.zhimg.com/5b16f655b57a957bfa340d0a996a0eea_r.jpg">表3
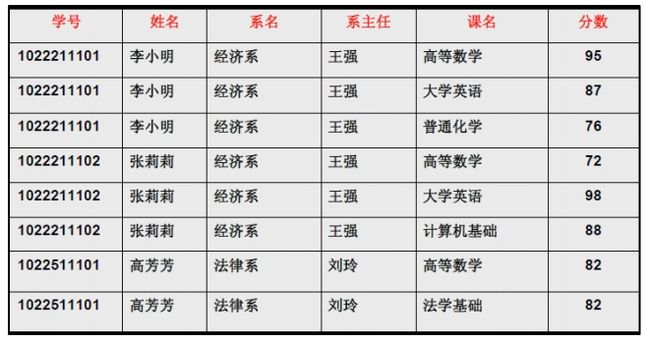 表3
表3
- 每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大
- 假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的 (注1)——插入异常
注1:根据三种关系完整性约束中实体完整性的要求,关系中的码(注2)所包含的任意一个属性都不能为空,所有属性的组合也不能重复。为了满足此要求,图中的表,只能将学号与课名的组合作为码,否则就无法唯一地区分每一条记录。
注2:码:关系中的某个属性或者某几个属性的组合,用于区分每个元组(可以把“元组”理解为一张表中的每条记录,也就是每一行)。 - 假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。——删除异常
- 假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。——修改异常。
第二范式(2NF)在关系理论中的严格定义我这里就不多介绍了(因为涉及到的铺垫比较多),只需要了解2NF对1NF进行了哪些改进即可。其改进是, 2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。接下来对这句话中涉及到的四个概念—— “函数依赖”、 “码”、 “非主属性”、与 “部分函数依赖”进行一下解释。
函数依赖
我们可以这么理解(但并不是特别严格的定义): 若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。
例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说 姓名函数依赖于学号,写作 学号 → 姓名。但是反过来,因为可能出现同名的学生,所以有可能不同的两条学生记录,它们在姓名上的值相同,但对应的学号不同,所以我们不能说学号函数依赖于姓名。表中其他的函数依赖关系还有如:
- 系名 → 系主任
- 学号 → 系主任
- (学号,课名) → 分数
- 学号 → 课名
- 学号 → 分数
- 课名 → 系主任
- (学号,课名) → 姓名
完全函数依赖
在一张表中,若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X ' → Y 不成立,那么我们称 Y 对于 X 完全函数依赖,记作 X F→ Y。(那个F应该写在箭头的正上方,没办法打出来……,正确的写法如 图1)
<img src="https://pic3.zhimg.com/12513de20079d12b99d946072df7311a_b.jpg" data-rawwidth="98" data-rawheight="53" class="content_image" width="98">图1
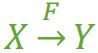 图1
图1
例如:
- 学号 F→ 姓名
- (学号,课名) F→ 分数 (注:因为同一个的学号对应的分数不确定,同一个课名对应的分数也不确定)
假如 Y 函数依赖于 X,但同时 Y 并不完全函数依赖于 X,那么我们就称 Y 部分函数依赖于 X,记作 X P→ Y,如 图2。
<img src="https://pic4.zhimg.com/10b52b39b18b8ea9fb17b46babf4d20f_b.jpg" data-rawwidth="99" data-rawheight="62" class="content_image" width="99">
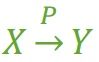
图2
例如:
- (学号,课名) P→ 姓名
传递函数依赖
假如 Z 函数依赖于 Y,且 Y 函数依赖于 X (严格来说还有一个X 不包含于Y,且 Y 不函数依赖于Z的前提条件),那么我们就称 Z 传递函数依赖于 X ,记作 X T→ Z,如 图3。
<img src="https://pic2.zhimg.com/51f8105fbbe92adaa3e343ea2db3bf49_b.jpg" data-rawwidth="124" data-rawheight="77" class="content_image" width="124">
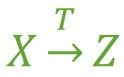
图3
码
设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为 候选码,简称为 码。在实际中我们通常可以理解为: 假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为 主码)
例如:
对于表3, (学号、课名)这个属性组就是码。该表中有且仅有这一个码。(假设所有课没有重名的情况)
非主属性
包含在任何一个码中的属性成为主属性。
例如:
对于表3,主属性就有两个, 学号 与 课名。
终于可以回过来看2NF了。首先,我们需要判断,表3是否符合2NF的要求?根据2NF的定义,判断的依据实际上就是看数据表中 是否存在非主属性对于码的部分函数依赖。若存在,则数据表最高只符合1NF的要求,若不存在,则符合2NF的要求。判断的方法是:
第一步:找出数据表中所有的 码。
第二步:根据第一步所得到的码,找出所有的 主属性。
第三步:数据表中,除去所有的主属性,剩下的就都是 非主属性了。
第四步:查看是否存在非主属性对码的 部分函数依赖。
对于表3,根据前面所说的四步,我们可以这么做:
第一步:
- 查看所有每一单个属性,当它的值确定了,是否剩下的所有属性值都能确定。
- 查看所有包含有两个属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。
- ……
- 查看所有包含了六个属性,也就是所有属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。
图4表示了表中所有的函数依赖关系:
<img src="https://pic4.zhimg.com/51e2689ac9416a91800e63101bee9db7_b.jpg" data-rawwidth="541" data-rawheight="212" class="origin_image zh-lightbox-thumb" width="541" data-original="https://pic4.zhimg.com/51e2689ac9416a91800e63101bee9db7_r.jpg">图4
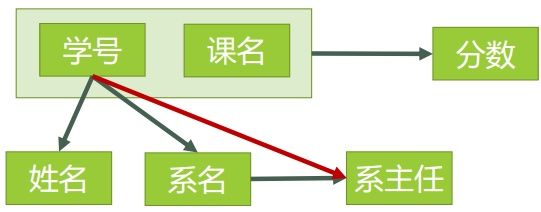 图4
图4
这一步完成以后,可以得到,表3的码只有一个,就是 (学号、课名)。
第二步:
主属性有两个: 学号 与 课名
第三步:
非主属性有四个: 姓名、 系名、 系主任、 分数
第四步:
对于 (学号,课名) → 姓名,有 学号 → 姓名,存在非主属性 姓名 对码 (学号,课名)的部分函数依赖。
对于 (学号,课名) → 系名,有 学号 → 系名,存在非主属性 系 名 对码 (学号,课名)的部分函数依赖。
对于 (学号,课名) → 系主任,有 学号 → 系主任,存在非主属性 对码 (学号,课名)的部分函数依赖。
所以表3存在非主属性对于码的部分函数依赖,最高只符合1NF的要求,不符合2NF的要求。
为了让表3符合2NF的要求,我们必须消除这些部分函数依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表,在拆分的过程中,要达到更高一级范式的要求,这个过程叫做”模式分解“。模式分解的方法不是唯一的,以下是其中一种方法:
选课(学号,课名,分数)
学生(学号,姓名,系名,系主任)
我们先来判断以下, 选课表与 学生表,是否符合了2NF的要求?
对于 选课表,其码是 (学号,课名),主属性是 学号和 课名,非主属性是 分数, 学号确定,并不能唯一确定 分数, 课名确定,也不能唯一确定 分数,所以不存在非主属性 分数对于码 (学号,课名)的部分函数依赖,所以此表符合2NF的要求。
对于 学生表,其码是 学号,主属性是 学号,非主属性是 姓名、系名和 系主任,因为码只有一个属性,所以不可能存在非主属性对于码 的部分函数依赖,所以此表符合2NF的要求。
图5表示了模式分解以后的新的函数依赖关系
<img src="https://pic4.zhimg.com/2f4b4a887f6a61674a49d03d79e3fe17_b.jpg" data-rawwidth="961" data-rawheight="467" class="origin_image zh-lightbox-thumb" width="961" data-original="https://pic4.zhimg.com/2f4b4a887f6a61674a49d03d79e3fe17_r.jpg">图5
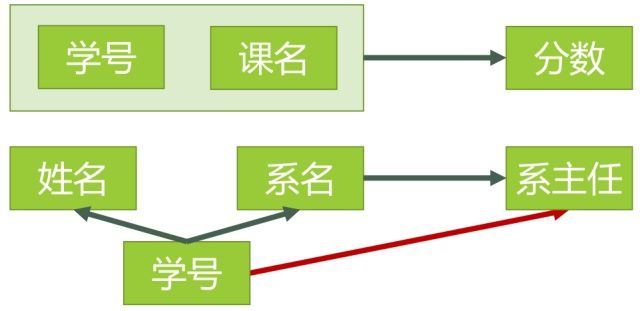 图5
图5
表4表示了模式分解以后新的数据
<img src="https://pic2.zhimg.com/44af74509a4e21372ed372be8560539d_b.jpg" data-rawwidth="478" data-rawheight="314" class="origin_image zh-lightbox-thumb" width="478" data-original="https://pic2.zhimg.com/44af74509a4e21372ed372be8560539d_r.jpg">
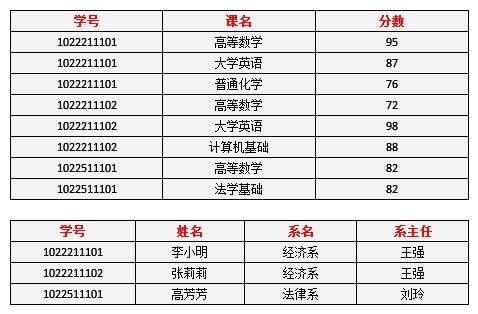
表4
(这里还涉及到一个如何进行模式分解才是正确的知识点,先不介绍了)
现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?
- 李小明转系到法律系
只需要修改一次李小明对应的系的值即可。——有改进 - 数据冗余是否减少了?
学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进 - 删除某个系中所有的学生记录
该系的信息仍然全部丢失。——无改进 - 插入一个尚无学生的新系的信息。
因为学生表的码是学号,不能为空,所以此操作不被允许。——无改进
第三范式(3NF)
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。
接下来我们看看表4中的设计,是否符合3NF的要求。
对于 选课表,主码为(学号,课名),主属性为 学号和 课名,非主属性只有一个,为分数,不可能存在传递函数依赖,所以 选课表的设计,符合3NF的要求。
对于 学生表,主码为 学号,主属性为 学号,非主属性为 姓名、 系名和 系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性 系主任对于码 学号的传递函数依赖,所以 学生表的设计,不符合3NF的要求。。
为了让数据表设计达到3NF,我们必须进一步进行模式分解为以下形式:
选课(学号,课名,分数)
学生(学号,姓名,系名)
系(系名,系主任)
对于 选课表,符合3NF的要求,之前已经分析过了。
对于 学生表,码为 学号,主属性为 学号,非主属性为 系名,不可能存在非主属性对于码的传递函数依赖,所以符合3NF的要求。
对于 系表,码为 系名,主属性为 系名,非主属性为 系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),所以符合3NF的要求。。
新的函数依赖关系如图6
<img src="https://pic1.zhimg.com/5b20707ff3d9afb51ef7bfda726c3e34_b.jpg" data-rawwidth="783" data-rawheight="388" class="origin_image zh-lightbox-thumb" width="783" data-original="https://pic1.zhimg.com/5b20707ff3d9afb51ef7bfda726c3e34_r.jpg">图6
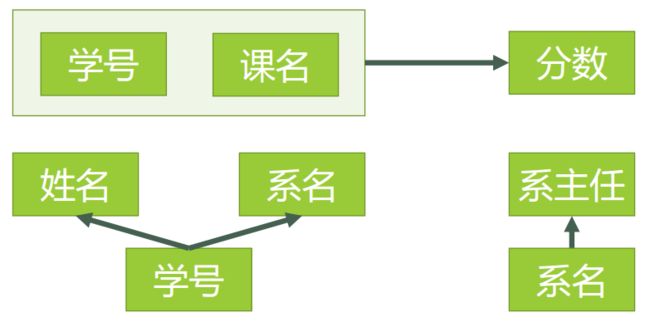 图6
图6
新的数据表如表5
<img src="https://pic3.zhimg.com/8bca802bcff92a8945bf808d18d7ec62_b.jpg" data-rawwidth="470" data-rawheight="419" class="origin_image zh-lightbox-thumb" width="470" data-original="https://pic3.zhimg.com/8bca802bcff92a8945bf808d18d7ec62_r.jpg">
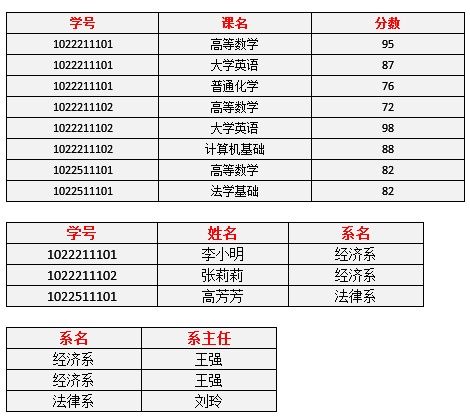
表5
现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?
- 删除某个系中所有的学生记录
该系的信息不会丢失。——有改进 - 插入一个尚无学生的新系的信息。
因为系表与学生表目前是独立的两张表,所以不影响。——有改进 - 数据冗余更加少了。——有改进
结论
由此可见,符合3NF要求的数据库设计, 基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。当然,在实际中,往往为了性能上或者应对扩展的需要,经常 做到2NF或者1NF,但是作为数据库设计人员,至少应该知道,3NF的要求是怎样的。
==============时隔半年,终于决定把这个坑填上,来晚了 ===========
BCNF范式
要了解 BCNF 范式,那么先看这样一个问题:
若:
- 某公司有若干个仓库;
- 每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;
- 一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。
答:已知函数依赖集:仓库名 → 管理员,管理员 → 仓库名,(仓库名,物品名)→ 数量
码:(管理员,物品名),(仓库名,物品名)
主属性:仓库名、管理员、物品名
非主属性:数量
∵ 不存在非主属性对码的部分函数依赖和传递函数依赖。∴ 此关系模式属于3NF。
基于此关系模式的关系(具体的数据)可能如图所示:
<img src="https://pic3.zhimg.com/68d080d437732aad8cfe451b427849d6_b.jpg" data-rawwidth="625" data-rawheight="296" class="origin_image zh-lightbox-thumb" width="625" data-original="https://pic3.zhimg.com/68d080d437732aad8cfe451b427849d6_r.jpg">
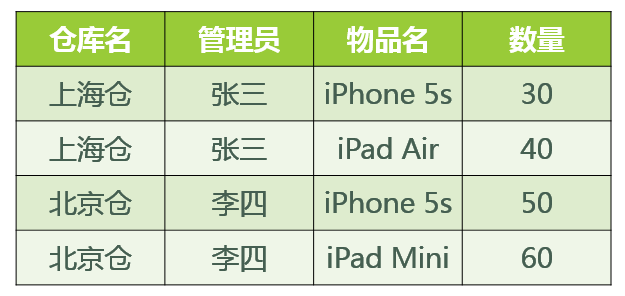
好,既然此关系模式已经属于了 3NF,那么这个关系模式是否存在问题呢?我们来看以下几种操作:
- 先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。
- 某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。
- 如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。
造成此问题的原因:存在着 主属性对于码的部分函数依赖与传递函数依赖。(在此例中就是存在主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。
解决办法就是要在 3NF 的基础上消除 主属性对于码的部分与传递函数依赖。
仓库(仓库名,管理员)
库存(仓库名,物品名,数量)
这样,之前的插入异常,修改异常与删除异常的问题就被解决了。
以上就是关于 BCNF 的解释。
最近身体不太舒服,写不动了。有空再放几个典型习题及其解答吧。
===============================
问题1:
李德竹 :老师您好,我看了您关于数据库范式的回答,有一点不太理解,就是关于码的定义,如果除K之外的所有属性都完全函数依赖于K时才能称K为码,那么在判断2NF时又怎么会存在非主属性对码的部分函数依赖这种情况?希望老师有时间能指点一下,谢谢
我 :在“码”的定义中,除 K 之外的所有属性应该看成是一个集合 U(也就是一个整体),也就是说,只有 K 能够完全函数决定 U 中的每一个属性,那么 K 才是码。如果 K 只是能够完全函数决定 U 中的一部分属性,而不能完全函数决定另外一部分属性,那么 K 不是码。
比如有关系模式 R (Sno, Sname, Cno, Cname, Sdept, Sloc, Grade),其中函数依赖集为 F= {
Sno → Sname, Sno → Sdept, Sdept → Sloc,Sno → Sloc, Cno → Cname, (Sno, Cno) → Grade }
那么 R 中的码只能是 (Sno, Cno),Sno 或 Cno 并不能完全函数决定除 Sno / Cno 之外的所有其他属性(其实就是不能决定 Grade ),所以单独的 Sno 与 Cno 并不能作为码。
所以可得到主属性:Sno, Cno
非主属性:Sname, Cname, Sdept, Sloc, Grade
R 中存在非主属性 Cname 对于码 (Sno, Cno) 的部分函数依赖 (Cno → Cname) 。(还有很多别的例子就不一一列举了)。所以 R 不符合 2NF 的要求。
NF(normal form)作为一个数据库设计里经常会提到的概念,是每一个初学者都应该了解并掌握的。复习数据库的时候发现 Database System Concepts 这本书里讲的过于抽象,而且网上也没有特别好的讲解,于是自己重新整理一份,有需者自取。
NF的意义Normal form作为设计的标准范式,其最大的意义就是为了避免数据的冗余和插入/删除/更新的异常。举个例子
表1
school(stu-id,stu-name,major,dean-name,dean-telephone)
在学校这个表里面,学生的学号、姓名、专业、系主任以及系主任电话被放到了一起(典型的excel风格)。虽然这样有些时候也不是不可以,但当进行一些特定操作的时候,着实会给我们带来极大的困扰。
- 插入异常[ 输入新信息的时候,系主任电话号码输错 ] : 无法确认系主任的真正号码。
- 删除异常[ 某个系的学生全部退学了 ] : 该系对应的系主任名字和电话号码也随之丢失。
- 更新异常[ 系主任进行变更 / 系主任换手机号 ] : 我们需要把系里所有学生的行都给更新一遍,显然开销过大。
定义:所有的属性均有原子性
说人话:所有的属性均不可被再分割,国外比较喜欢拿人名来举例(first,middle,last),但跟国内国情不太符合,我就举一个商品的例子好了。
TaobaoPucharsedLog(sid, date, buyer, seller, goods,amount)
显然“商品”会有更多详细的属性,例如商品名称,商品价格,产地等等。“用户”也有昵称,年龄,住址等,“商户”也是如此。这些属性都是可以再分割的,所以并不符合1NF范式,需要将其完全拆至不可分割为止。
修改示范:
TaobaoPucharsedLog(sid, date, buyer-id, buyer-name, buyer-age, seller, goods, amount) [仅拆开了buyer]
意义:嗯.. 这个还是等我们讲完四个定理再来说吧,现在讲解比较困难。
2NF(在满足1NF的前提上)定义:如果依赖于主键,则需要依赖于所有主键,不能存在依赖部分主键的情况
说人话:对于上面那个例子,TaobaoPucharsedLog(sid, date, buyer-id, buyer-name, buyer-age, seller-id, seller-name, seller-age, goods-id, goods-name, amount)。可以看到里面有四个主键:sid, buyer-id, seller-id, goods-id。对于seller-name属性,它仅依赖于seller-id,跟buyer-id之类的没有任何关系,所以它对于主键的依赖是“部分依赖”,并不符合2NF。简单点说,就是不要把不相关的东西放到一个表里面。
修改示范:
拆解成以下四个
- TaobaoPucharsedLog(sid, buyer-id, seller-id, goods-id, amount)
- BuyerInformation(buyer-id, buyer-name, buyer-age)
- SellerInformation(seller-id, seller-name, seller-age)
- GoodsInformation(goods-id, goods-name)
意义:不相关的东西不要放在一起,用多个小表连接来代替大表,减少修改时候的负担。
3NF(在满足1NF和2NF的前提上)定义:一个数据库表中不包含已在其它表中已包含的非主关键字信息。
说人话:不得存在传递式依赖,比如对于一张数据库,里面的元素有son, person, father, grand-father,依赖关系是son -> person, person -> father, father -> grand-father,明显有一个链表式的传递,3NF中禁止此类依赖的出现。
修改示范:
依赖关系修改为
- son -> person
- son -> father
- son -> grand-father
或者是拆成三张表
(其实就是并查集里面的路径压缩)
意义:避免查询路径过长而导致询问时间过长或者更新异常。以上面的家族关系为例,如果我想查询某位同学曾曾曾曾曾……曾祖父是谁,按照非3NF的依赖,则需要进行多次查询,而对于满足3NF的依赖,只需要进行一次查询。效率大大提高。
http://www.cnblogs.com/CareySon/archive/2010/02/16/1668803.html
总结:
1NF: 字段是最小的的单元不可再分
2NF:满足1NF,表中的字段必须完全依赖于全部主键而非部分主键 (一般我们都会做到)
3NF:满足2NF,非主键外的所有字段必须互不依赖
4NF:满足3NF,消除表中的多值依赖