微信公众号爬虫技术分享
采集方案分析对比
目前主流的抓取公众号文章及动态信息不同采集方案对比如下:

由上图可知:
如果需要长期监控公众号实时的文章,我推荐使用逆向的方式;
如果要做获取文章阅读点赞评论量或搜狗微信转永久链接等接口,推荐使用万能key的方式;
至于中间人的方式,技术门槛低,开发周期短,如果要监控的公众号不多,且实效性要求不那么高,我推荐使用这种方式。
下面将详细介绍基于中间人方式采集的原理
采集方案详解
基于中间人方式
采集原理
中间人好比中介,这里指抓包工具,大致的原理图如下

微信客户端之所以可以看到文章信息,是因为请求了微信的服务器,服务器收到请求后,将对应的文章返给客户端。这里我们通过抓包工具(中间人)拦截数据,将拦截到的文章数据解析入库,就完成了一次简单的数据抓取。
那么如何实现多个文章自动抓取,及列表页自动翻页呢。总不能人肉去点吧。那么最先想到的是自动化工具,比如大家都知道的按键精灵。但是这种自动化工具如何与抓包工具交互,是个问题。我们要保证在数据被拦截入库之后,再去点击下一个抓取的目标,又或者当网络异常时,自动化工具如何检测出来,然后重刷当前页面,发起请求。即使可以实现,应该也很麻烦,所以没采用这种方法。本人也不喜欢自动化工具,总感觉它不稳定。。。
既然微信文章界面是html的,我们可以嵌入js嘛,让他自动跳转。那么如何在文章和源代码里嵌入自己的js呢?这时中间人就派上用场了,既然他可以拦截数据,当然可以修改数据,再返回给客户端。因此这种方式是可行的。
代码解析
知道了中间人的原理,下面说说代码如何实现。这里所用语言为 python3,抓包工具为 mitmproxy. 代理地址仓库为:https://github.com/striver-ing/wechat-spider
可先下载代码,然后对照本文去看代码
本项目的目录结构为:
wechat-spider
├── config.py # 读取配置文件
├── config.yaml # 配置文件
├── core # 代码的核心
│ ├── capture_packet.py # 抓包代码(中间人)
│ ├── data_pipeline.py # 数据入库
│ ├── deal_data.py # 数据处理
│ └── task_manager.py # 任务调度
├── create_tables.py # 创建表
├── db # 数据库的封装
│ ├── mysqldb.py # mysql数据库
│ └── redisdb.py # redis数据库
├── run.py # 启动入口
└── utils # 工具包
├── log.py # 日志
├── selector.py # xpath解析工具
└── tools.py # 一些函数的封装
capture_packet.py
本模块代码用于拦截微信服务端到客户端的数据,然后将拦截到的数据交给deal_data.py 处理,再注入js返回给微信客户端。
红框框住的为拦截的数据包规则,比如返回的数据包地址中包含 /s?__biz=,那么该数据包的数据就会被拦截。具体每个规则代表什么数据包,代码中有注释说明,可对应查看

注入js的代码为

next_page 为所注入的js,值为task_manager.py中返回的,如下:
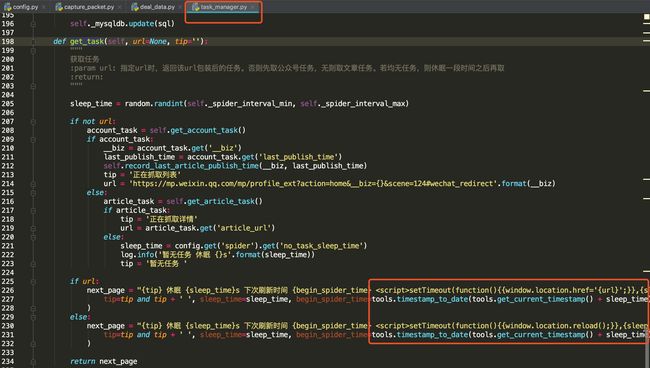
核心js为
即设置了个定时器,在一定的间隔后,跳转到指定的url。url 即为我们要抓取的下一个目标,可以为文章地址,可以为历史页面的下一页地址等。
坑
坑1:列表页第一页为html,可注入js,之后再翻页时数据包的格式为json。注入js不生效。因此需要改返回头才可以
![]()
坑2:文章页面有安全机制,外部注入的js不生效,也需要改返回的头。如下:

优化
为了使微信客户端页面加载更快,减少没必要的网络请求。我们可以去掉页面中的图片及视频,代码如下:
![]()
这部分代码是把返回给微信客户端数据里的img标签替换为空,那么客户端就自然不加载图片了,不加载视频的原理一样。
这个模块的代码为核心中的核心,也是中间人全部的代码,若第一遍没读懂,可反复理解几遍,再往下看
deal_data.py
本模块代码为数据清洗入库,代码如下:
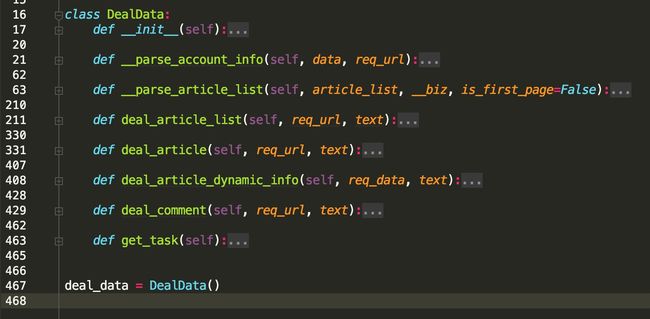
__parse_account_info:解析公众号信息
__parse_article_list与deal_article_list:解析文章列表
deal_article:解析文章
deal_article_dynamic_info:解析文章动态信息,阅读、点赞、评论量
deal_comment:解析评论信息
get_task:获取下一个任务
此处有个细节,处理完数据后,要返回需要注入的js(即接下来要抓取的页面)给capture_packet.py,以便后续自动抓取其他文章或历史列面内容。但阅读点赞评论量与评论内容这俩接口是在访问文章地址时间接请求的,因此这俩解析函数不需要返回注入的js。

具体的代码执行逻辑如上图。此处建议自己抓下数据包去分析分析,再结合代码,这样便于理解
task_manager.py
本模块为任务管理,获取任务时首先从redis中取,若redis中没有,再从mysql中取,然后添加到redis中

next_page 中 关键的跳转代码为:
跳转到下一个url
没任务时当前页面在一定时间间隔后刷新
之所以没任务时要在一定时间间隔后刷新,是为了触发微信客户端对服务端的请求,然后中间人才能抓到包,之后才能触发本模块的代码逻辑执行,重新获取任务。
data_pipeline.py
这个模块没啥说的,就是数据入库,本处省略
总结
以上为现阶段主流的微信公众号爬虫技术方案对比分析及微信公众号爬虫 https://github.com/striver-ing/wechat-spider 代码刨析。建议先抓下微信的数据包分析下,搞清楚微信公众号数据整个请求流程,对理解本代码很有帮助。目前7.0以上的手机微信貌似抓不到包了,可以抓取pc端的或者mac端的,协议是一样的。
愿本次分享对您有些许帮助,谢谢~
下期分享预告
智联-瑞数反爬破解

了解更多
欢迎加入知识星球 https://t.zsxq.com/eEmAeae

本星球专注于爬虫技术分享,通过一些案例详细讲解爬虫中遇到的问题以及解决手段。涉及的知识包括但不限于 爬虫框架刨析、js逆向、中间人、selenium 、pyppeteer、Android 逆向!期待您的加入,和我们一起探讨爬虫技术,拓展爬虫思维!