最详细的Storm入门教程(二)
Storm入门例子详解-单词计数器
概念
Storm 分布式计算结构称为 topology(拓扑),由 stream(数据流), spout(数据流的生成者), bolt(运算)组成。
Storm 的核心数据结构是 tuple。 tuple是 包 含 了 一 个 或 者 多 个 键 值 对 的 列 表,Stream 是 由 无 限 制 的 tuple 组 成 的 序 列。
spout 代表了一个 Storm topology 的主要数据入口,充当采集器的角色,连接到数据源,将数据转化为一个个 tuple,并将 tuple 作为数据流进行发射。
bolt 可以理解为计算程序中的运算或者函数,将一个或者多个数据流作为输入,对数据实施运算后,选择性地输出一个或者多个数据流。 bolt 可以订阅多个由 spout 或者其他bolt 发射的数据流,这样就可以建立复杂的数据流转换网络。

本例子单词计数 topology 的数据流大概是这样:

项目搭建
新建类SentenceSpout.java(数据流生成者)
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
/**
* 向后端发射tuple数据流
* @author soul
*
*/
public class SentenceSpout extends BaseRichSpout {
//BaseRichSpout是ISpout接口和IComponent接口的简单实现,接口对用不到的方法提供了默认的实现
private SpoutOutputCollector collector;
private String[] sentences = {
"my name is soul",
"im a boy",
"i have a dog",
"my dog has fleas",
"my girl friend is beautiful"
};
private int index=0;
/**
* open()方法中是ISpout接口中定义,在Spout组件初始化时被调用。
* open()接受三个参数:一个包含Storm配置的Map,一个TopologyContext对象,提供了topology中组件的信息,SpoutOutputCollector对象提供发射tuple的方法。
* 在这个例子中,我们不需要执行初始化,只是简单的存储在一个SpoutOutputCollector实例变量。
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
}
/**
* nextTuple()方法是任何Spout实现的核心。
* Storm调用这个方法,向输出的collector发出tuple。
* 在这里,我们只是发出当前索引的句子,并增加该索引准备发射下一个句子。
*/
public void nextTuple() {
//collector.emit(new Values("hello world this is a test"));
// TODO Auto-generated method stub
this.collector.emit(new Values(sentences[index]));
index++;
if (index>=sentences.length) {
index=0;
}
Utils.sleep(1);
}
/**
* declareOutputFields是在IComponent接口中定义的,所有Storm的组件(spout和bolt)都必须实现这个接口
* 用于告诉Storm流组件将会发出那些数据流,每个流的tuple将包含的字段
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("sentence"));//告诉组件发出数据流包含sentence字段
}
}新建类SplitSentenceBolt.java(单词分割器)
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 订阅sentence spout发射的tuple流,实现分割单词
* @author soul
*
*/
public class SplitSentenceBolt extends BaseRichBolt {
//BaseRichBolt是IComponent和IBolt接口的实现
//继承这个类,就不用去实现本例不关心的方法
private OutputCollector collector;
/**
* prepare()方法类似于ISpout 的open()方法。
* 这个方法在blot初始化时调用,可以用来准备bolt用到的资源,比如数据库连接。
* 本例子和SentenceSpout类一样,SplitSentenceBolt类不需要太多额外的初始化,
* 所以prepare()方法只保存OutputCollector对象的引用。
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector=collector;
}
/**
* SplitSentenceBolt核心功能是在类IBolt定义execute()方法,这个方法是IBolt接口中定义。
* 每次Bolt从流接收一个订阅的tuple,都会调用这个方法。
* 本例中,收到的元组中查找“sentence”的值,
* 并将该值拆分成单个的词,然后按单词发出新的tuple。
*/
public void execute(Tuple input) {
// TODO Auto-generated method stub
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
this.collector.emit(new Values(word));//向下一个bolt发射数据
}
}
/**
* plitSentenceBolt类定义一个元组流,每个包含一个字段(“word”)。
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("word"));
}
}
新建类WordCountBolt.java(单词计数器)
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 订阅 split sentence bolt的输出流,实现单词计数,并发送当前计数给下一个bolt
* @author soul
*
*/
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
//存储单词和对应的计数
private HashMap counts = null;//注:不可序列化对象需在prepare中实例化
/**
* 大部分实例变量通常是在prepare()中进行实例化,这个设计模式是由topology的部署方式决定的
* 因为在部署拓扑时,组件spout和bolt是在网络上发送的序列化的实例变量。
* 如果spout或bolt有任何non-serializable实例变量在序列化之前被实例化(例如,在构造函数中创建)
* 会抛出NotSerializableException并且拓扑将无法发布。
* 本例中因为HashMap 是可序列化的,所以可以安全地在构造函数中实例化。
* 但是,通常情况下最好是在构造函数中对基本数据类型和可序列化的对象进行复制和实例化
* 而在prepare()方法中对不可序列化的对象进行实例化。
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
this.counts = new HashMap();
}
/**
* 在execute()方法中,我们查找的收到的单词的计数(如果不存在,初始化为0)
* 然后增加计数并存储,发出一个新的词和当前计数组成的二元组。
* 发射计数作为流允许拓扑的其他bolt订阅和执行额外的处理。
*/
public void execute(Tuple input) {
// TODO Auto-generated method stub
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;//如果不存在,初始化为0
}
count++;//增加计数
this.counts.put(word, count);//存储计数
this.collector.emit(new Values(word,count));
}
/**
*
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
//声明一个输出流,其中tuple包括了单词和对应的计数,向后发射
//其他bolt可以订阅这个数据流进一步处理
declarer.declare(new Fields("word","count"));
}
} 新建类ReportBolt.java(报告生成器)
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
/**
* 生成一份报告
* @author soul
*
*/
public class ReportBolt extends BaseRichBolt {
private HashMap counts = null;//保存单词和对应的计数
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.counts = new HashMap();
}
public void execute(Tuple input) {
// TODO Auto-generated method stub
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
this.counts.put(word, count);
//实时输出
System.out.println("结果:"+this.counts);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
//这里是末端bolt,不需要发射数据流,这里无需定义
}
/**
* cleanup是IBolt接口中定义
* Storm在终止一个bolt之前会调用这个方法
* 本例我们利用cleanup()方法在topology关闭时输出最终的计数结果
* 通常情况下,cleanup()方法用来释放bolt占用的资源,如打开的文件句柄或数据库连接
* 但是当Storm拓扑在一个集群上运行,IBolt.cleanup()方法不能保证执行(这里是开发模式,生产环境不要这样做)。
*/
public void cleanup(){
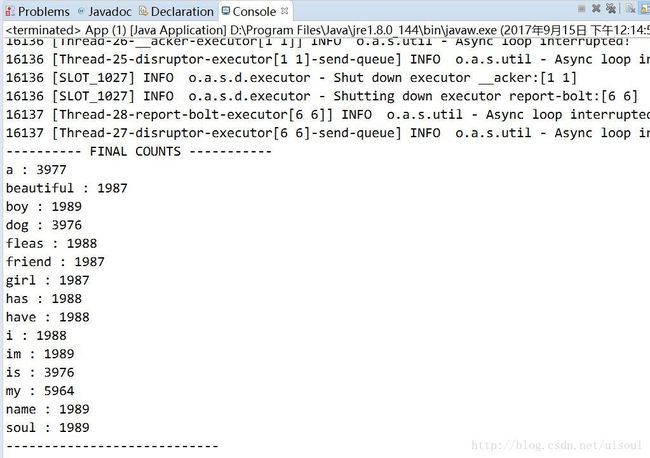
System.out.println("---------- FINAL COUNTS -----------");
ArrayList keys = new ArrayList();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for(String key : keys){
System.out.println(key + " : " + this.counts.get(key));
}
System.out.println("----------------------------");
}
} 修改程序主入口App.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.utils.Utils;
/**
* 实现单词计数topology
*
*/
public class App
{
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main( String[] args ) //throws Exception
{
//System.out.println( "Hello World!" );
//实例化spout和bolt
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();//创建了一个TopologyBuilder实例
//TopologyBuilder提供流式风格的API来定义topology组件之间的数据流
//builder.setSpout(SENTENCE_SPOUT_ID, spout);//注册一个sentence spout
//设置两个Executeor(线程),默认一个
builder.setSpout(SENTENCE_SPOUT_ID, spout,2);
// SentenceSpout --> SplitSentenceBolt
//注册一个bolt并订阅sentence发射出的数据流,shuffleGrouping方法告诉Storm要将SentenceSpout发射的tuple随机均匀的分发给SplitSentenceBolt的实例
//builder.setBolt(SPLIT_BOLT_ID, splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
//SplitSentenceBolt单词分割器设置4个Task,2个Executeor(线程)
builder.setBolt(SPLIT_BOLT_ID, splitBolt,2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
//fieldsGrouping将含有特定数据的tuple路由到特殊的bolt实例中
//这里fieldsGrouping()方法保证所有“word”字段相同的tuuple会被路由到同一个WordCountBolt实例中
//builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping( SPLIT_BOLT_ID, new Fields("word"));
//WordCountBolt单词计数器设置4个Executeor(线程)
builder.setBolt(COUNT_BOLT_ID, countBolt,4).fieldsGrouping( SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
//globalGrouping是把WordCountBolt发射的所有tuple路由到唯一的ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();//Config类是一个HashMap的子类,用来配置topology运行时的行为
//设置worker数量
//config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
//本地提交
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}运行程序,可看到单词计数实时输出效果
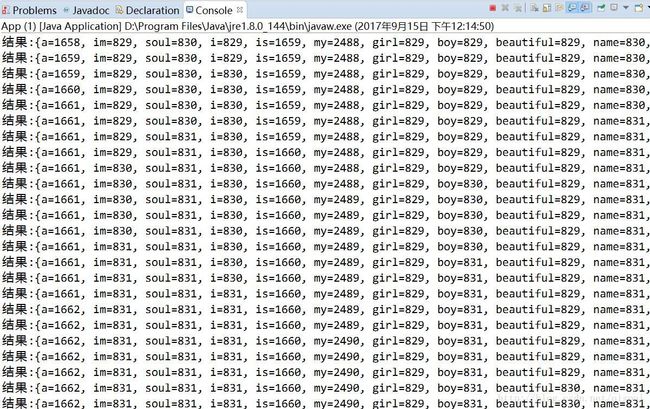
运行10秒后生成报告