贪心法
贪心法(Greedy Approach)又称贪婪法, 在对问题求解时,总是做出在当前看来是最好的选择,或者说是:总是作出在当前看来最好的选择。也就是说贪心算法并不从整体最优考虑,它所作出的选择只是在某种意义上的局部最优选择。当然,希望贪心算法得到的最终结果也是整体最优的。虽然贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解。如单源最短路经问题,最小生成树问题等。在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似。
贪心法的设计思想
当一个问题具有以下的性质时可以用贪心算法求解:每一步的局部最优解,同事也说整个问题的最优解。
如果一个问题可以用贪心算法解决,那么贪心通常是解决这个问题的最好的方法。 贪婪算法一般比其他方法例如动态规划更有效。但是贪婪算法不能总是被应用。例如,部分背包问题可以使用贪心解决,但是不能解决0-1背包问题。
贪婪算法有时也用用来得到一个近似优化问题。例如,旅行商问题是一个NP难问题。贪婪选择这个问题是选择最近的并且从当前城市每一步。这个解决方案并不总是产生最好的最优解,但可以用来得到一个近似最优解。
让我们考虑一下任务选择的贪婪算法的问题, 作为我们的第一个例子。问题:
给出n个任务和每个任务的开始和结束时间。找出可以完成的任务的最大数量,在同一时刻只能做一个任务。
例子:
下面的6个任务:
start[] = {1, 3, 0, 5, 8, 5};
finish[] = {2, 4, 6, 7, 9, 9};
最多可完成的任务是:
{0, 1, 3, 4}贪婪的选择是总是选择下一个任务的完成时间至少在剩下的任务和开始时间大于或等于以前选择任务的完成时间。我们可以根据他们的任务完成时间,以便我们总是认为下一个任务是最小完成时间的任务。
- 1)按照完成时间对任务排序
- 2)选择第一个任务排序数组元素和打印。
- 3) 继续以下剩余的任务排序数组。
……a)如果这一任务的开始时间大于先前选择任务的完成时间然后选择这个任务和打印。
在接下来的C程序,假设已经根据任务的结束时间排序。
#include输出:
Following activities are selected
0 1 3 4贪心算法的基本要素
对于一个具体的问题,怎么知道是否可用贪心算法解此问题,以及能否得到问题的最优解呢?这个问题很难给予肯定的回答。
但是,从许多可以用贪心算法求解的问题中看到这类问题一般具有2个重要的性质:贪心选择性质和最优子结构性质。
- 1、贪心选择性质
所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到。这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别。
动态规划算法通常以自底向上的方式解各子问题,而贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题。
对于一个具体问题,要确定它是否具有贪心选择性质,必须证明每一步所作的贪心选择最终导致问题的整体最优解。
- 2、最优子结构性质
当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质。问题的最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征。
- 3、贪心算法与动态规划算法的差异
贪心算法和动态规划算法都要求问题具有最优子结构性质,这是2类算法的一个共同点。但是,对于具有最优子结构的问题应该选用贪心算法还是动态规划算法求解?是否能用动态规划算法求解的问题也能用贪心算法求解?下面研究2个经典的组合优化问题,并以此说明贪心算法与动态规划算法的主要差别。
0-1背包问题:
给定n种物品和一个背包。物品i的重量是Wi,其价值为Vi,背包的容量为C。应如何选择装入背包的物品,使得装入背包中物品的总价值最大?
在选择装入背包的物品时,对每种物品i只有2种选择,即装入背包或不装入背包。不能将物品i装入背包多次,也不能只装入部分的物品i。
背包问题:
与0-1背包问题类似,所不同的是在选择物品i装入背包时,可以选择物品i的一部分,而不一定要全部装入背包,1 <= i <= n。
这2类问题都具有最优子结构性质,极为相似,但背包问题可以用贪心算法求解,而0-1背包问题却不能用贪心算法求解。
用贪心算法解背包问题的基本步骤:
- 首先计算每种物品单位重量的价值 Vi/Wi ,
- 然后,依贪心选择策略,将尽可能多的单位重量价值最高的物品装入背包。
- 若将这种物品全部装入背包后,背包内的物品总重量未超过C,则选择单位重量价值次高的物品并尽可能多地装入背包。
- 依此策略一直地进行下去,直到背包装满为止。
伪代码:
void Knapsack(int n,float M,float v[],float w[],float x[])
{
Sort(n,v,w);
int i;
for (i = 1 ; i <= n ; i++)
x[i] = 0;
float c=M;
for (i=1;i<=n;i++) {
if (w[i] > c) break;
}
x[i]=1;
c-=w[i];
}
if (i <= n)
x[i]=c / w[i];
}算法knapsack的主要计算时间在于将各种物品依其单位重量的价值从大到小排序。因此,算法的计算时间上界为 O(nlogn)。
为了证明算法的正确性,还必须证明背包问题具有贪心选择性质。
对于0-1背包问题,贪心选择之所以不能得到最优解是因为在这种情况下,它无法保证最终能将背包装满,部分闲置的背包空间使每公斤背包空间的价值降低了。事实上,在考虑0-1背包问题时,应比较选择该物品和不选择该物品所导致的最终方案,然后再作出最好选择。由此就导出许多互相重叠的子问题。这正是该问题可用动态规划算法求解的另一重要特征。实际上也是如此,动态规划算法的确可以有效地解0-1背包问题。
贪心法的典型应用
活动安排问题
问题描述:设有 n 个活动的集合 E={1,2,…,n} ,其中每个活动都要求使用同一资源,如演讲会场等,而在同一时间内只有一个活动能使用这一资源。每个活 i 都有一个要求使用该资源的起始时间 si 和一个结束时间 fi ,且 si<fi 。如果选择了活动i,则它在半开时间区间 [si,fi) 内占用资源。若区间 [si,fi) 与区间 [sj,fj) 不相交,则称活动 i 与活动 j 是相容的。也就是说,当 si>=fj 或 sj>=fi 时,活动 i 与活动 j 相容。
由于输入的活动以其完成时间的非减序排列,所以算法 greedySelector每次总是选择具有最早完成时间的相容活动加入集合A中。直观上,按这种方法选择相容活动为未安排活动留下尽可能多的时间。也就是说,该算法的贪心选择的意义是使剩余的可安排时间段极大化,以便安排尽可能多的相容活动。
算法 greedySelector 的效率极高。当输入的活动已按结束时间的非减序排列,算法只需 O(n) 的时间安排n个活动,使最多的活动能相容地使用公共资源。如果所给出的活动未按非减序排列,可以用 O(nlogn) 的时间重排。
例:设待安排的11个活动的开始时间和结束时间按结束时间的非减序排列如下:
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| S[i] | 1 | 3 | 0 | 5 | 3 | 5 | 6 | 8 | 8 | 2 | 12 |
| f[i] | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
算法 greedySelector 的计算过程如下图所示[图来源网络]。图中每行相应于算法的一次迭代。阴影长条表示的活动是已选入集合A的活动,而空白长条表示的活动是当前正在检查相容性的活动。

若被检查的活动i的开始时间 Si 小于最近选择的活动 j 的结束时间 fi ,则不选择活动 i ,否则选择活动 i 加入集合 A 中。
贪心算法并不总能求得问题的整体最优解。但对于活动安排问题,贪心算法 greedySelector 却总能求得的整体最优解,即它最终所确定的相容活动集合A的规模最大。这个结论可以用数学归纳法证明。
活动安排问题实现:
#include 最优前缀码
Huffman 编码是一种无损压缩技术。它分配可变长度编码不同的字符。贪婪的选择是分配一点代码最常见的字符长度。哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。其压缩率通常在20%~90%之间。哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。
给出现频率高的字符较短的编码,出现频率较低的字符以较长的编码,可以大大缩短总码长。
| _ | a | b | c | d | e | f |
|---|---|---|---|---|---|---|
| 频率(千次) | 45 | 13 | 12 | 16 | 9 | 5 |
| 定长码 | 000 | 001 | 010 | 011 | 100 | 101 |
| 变长码 | 0 | 101 | 100 | 111 | 1101 | 1100 |
定长码: 3∗(45+13+12+16+9+5)=300 千位
变长码: 1∗45+3∗13+3∗12+3∗16+4∗9+4∗5=224 千位
1、前缀码
对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其它字符代码的前缀。这种编码称为前缀码。
编码的前缀性质可以使译码方法非常简单。
表示最优前缀码的二叉树总是一棵完全二叉树,即树中任一结点都有2个儿子结点。
平均码长定义为:
其中, f(c) 表示字符c出现的概率, dt(c) 表示c的码长.使平均码长达到最小的前缀码编码方案称为给定编码字符集C的最优前缀码。
2、构造哈夫曼编码
哈夫曼提出构造最优前缀码的贪心算法,由此产生的编码方案称为哈夫曼编码。哈夫曼算法以自底向上的方式构造表示最优前缀码的二叉树T。
算法以 |C| 个叶结点开始,执行 |C|−1 次的“合并”运算后产生最终所要求的树 T 。
以 f 为键值的优先队列 Q 用在贪心选择时有效地确定算法当前要合并的2棵具有最小频率的树。一旦2棵具有最小频率的树合并后,产生一棵新的树,其频率为合并的2棵树的频率之和,并将新树插入优先队列Q。经过 n-1 次的合并后,优先队列中只剩下一棵树,即所要求的树T。
算法 huffmanTree 用最小堆实现优先队列Q。初始化优先队列需要 O(n) 计算时间,由于最小堆的 removeMin 和 put 运算均需 O(logn) 时间, n-1 次的合并总共需要 O(nlogn) 计算时间。因此,关于 n 个字符的哈夫曼算法的计算时间为 O(nlogn) 。
3、哈夫曼算法的正确性
要证明哈夫曼算法的正确性,只要证明最优前缀码问题具有贪心选择性质和最优子结构性质。
- (1)贪心选择性质
- (2)最优子结构性质
实现代码(Code highlighting produced by Actipro CodeHighlighter )
#include
using namespace std ;
class HaffmanNode
{
public:
HaffmanNode (int nKeyValue,
HaffmanNode* pLeft = NULL,
HaffmanNode* pRight = NULL)
{
m_nKeyValue = nKeyValue ;
m_pLeft = pLeft ;
m_pRight = pRight ;
}
friend
bool operator < (const HaffmanNode& lth, const HaffmanNode& rth)
{
return lth.m_nKeyValue < rth.m_nKeyValue ;
}
public:
int m_nKeyValue ;
HaffmanNode* m_pLeft ;
HaffmanNode* m_pRight ;
} ;
class HaffmanCoding
{
public:
typedef priority_queue MinHeap ;
typedef HaffmanNode* HaffmanTree ;
public:
HaffmanCoding (const vector<int>& weight)
: m_pTree(NULL)
{
m_stCount = weight.size () ;
for (size_t i = 0; i < weight.size() ; ++ i) {
m_minheap.push (new HaffmanNode(weight[i], NULL, NULL)) ;
}
}
~ HaffmanCoding()
{
__destroy (m_pTree) ;
}
// 按照左1右0编码
void doHaffmanCoding ()
{
vector<int> vnCode(m_stCount-1) ;
__constructTree () ;
__traverse (m_pTree, 0, vnCode) ;
}
private:
void __destroy(HaffmanTree& ht)
{
if (ht->m_pLeft != NULL) {
__destroy (ht->m_pLeft) ;
}
if (ht->m_pRight != NULL) {
__destroy (ht->m_pRight) ;
}
if (ht->m_pLeft == NULL && ht->m_pRight == NULL) {
// cout << "delete" << endl ;
delete ht ;
ht = NULL ;
}
}
void __traverse (HaffmanTree ht,int layers, vector<int>& vnCode)
{
if (ht->m_pLeft != NULL) {
vnCode[layers] = 1 ;
__traverse (ht->m_pLeft, ++ layers, vnCode) ;
-- layers ;
}
if (ht->m_pRight != NULL) {
vnCode[layers] = 0 ;
__traverse (ht->m_pRight, ++ layers, vnCode) ;
-- layers ;
}
if (ht->m_pLeft == NULL && ht->m_pRight == NULL) {
cout << ht->m_nKeyValue << " coding: " ;
for (int i = 0; i < layers; ++ i) {
cout << vnCode[i] << " " ;
}
cout << endl ;
}
}
void __constructTree ()
{
size_t i = 1 ;
while (i < m_stCount) {
HaffmanNode* lchild = m_minheap.top () ;
m_minheap.pop () ;
HaffmanNode* rchild = m_minheap.top () ;
m_minheap.pop () ;
// 确保左子树的键值大于有子树的键值
if (lchild->m_nKeyValue < rchild->m_nKeyValue) {
HaffmanNode* temp = lchild ;
lchild = rchild ;
rchild = temp ;
}
// 构造新结点
HaffmanNode* pNewNode =
new HaffmanNode (lchild->m_nKeyValue + rchild->m_nKeyValue,
lchild, rchild ) ;
m_minheap.push (pNewNode) ;
++ i ;
}
m_pTree = m_minheap.top () ;
m_minheap.pop () ;
}
private:
vector<int> m_vnWeight ; // 权值
HaffmanTree m_pTree ;
MinHeap m_minheap ;
size_t m_stCount ; // 叶结点个数
} ;
int main()
{
vector<int> vnWeight ;
vnWeight.push_back (45) ;
vnWeight.push_back (13) ;
vnWeight.push_back (12) ;
vnWeight.push_back (16) ;
vnWeight.push_back (9) ;
vnWeight.push_back (5) ;
HaffmanCoding hc (vnWeight) ;
hc.doHaffmanCoding () ;
return 0 ;
} 单源最短路径
给定带权有向图 G=(V,E) ,其中每条边的权是非负实数。另外,还给定 V 中的一个顶点,称为源。现在要计算从源到所有其它各顶点的最短路长度。这里路的长度是指路上各边权之和。这个问题通常称为单源最短路径问题。
1、算法基本思想
Dijkstra算法是解单源最短路径问题的贪心算法。
其基本思想是,设置顶点集合S并不断地作贪心选择来扩充这个集合。一个顶点属于集合S当且仅当从源到该顶点的最短路径长度已知。
初始时,S中仅含有源。设u是G的某一个顶点,把从源到u且中间只经过S中顶点的路称为从源到u的特殊路径,并用数组dist记录当前每个顶点所对应的最短特殊路径长度。Dijkstra算法每次从V-S中取出具有最短特殊路长度的顶点u,将u添加到S中,同时对数组dist作必要的修改。一旦S包含了所有V中顶点,dist就记录了从源到所有其它顶点之间的最短路径长度。
例如,对下图中的有向图,应用Dijkstra算法计算从源顶点1到其它顶点间最短路径的过程列在下表中。
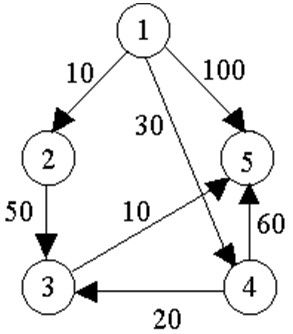
Dijkstra算法的迭代过程:
| 迭代 | s | u | dist[2] | dist[3] | dist[4] | dist[5] |
|---|---|---|---|---|---|---|
| 初始 | {1} | - | 10 | maxint | 30 | 100 |
| 1 | {1,2} | 2 | 10 | 60 | 30 | 100 |
| 2 | {1,2,4} | 4 | 10 | 50 | 30 | 90 |
| 3 | {1,2,4,3} | 3 | 10 | 50 | 30 | 60 |
| 4 | {1,2,4,3,5} | 5 | 10 | 50 | 30 | 60 |
2、算法的正确性和计算复杂性
(1)贪心选择性质
(2)最优子结构性质
(3)计算复杂性
对于具有n个顶点和e条边的带权有向图,如果用带权邻接矩阵表示这个图,那么 Dijkstra 算法的主循环体需要 O(n) 时间。这个循环需要执行 n−1 次,所以完成循环需要 O(n) 时间。算法的其余部分所需要时间不超过 O(n2) 。
实现:
#include 最小生成树
设 G=(V,E) 是无向连通带权图,即一个网络。E中的每一条边 (v,w) 的权为 c[v][w] 。如果G的子图G’是一棵包含G的所有顶点的树,则称G’为G的生成树。生成树上各边权的总和称为生成树的耗费。在G的所有生成树中,耗费最小的生成树称为G的最小生成树。最小生成树的性质:设G = (V,E)是连通带权图,U是V的真子集。如果(u,v)∈E,且u∈U,v∈V-U,且在所有这样的边中,(u,v)的权c[u][v]最小,那么一定存在G的一棵最小生成树,它意(u,v)为其中一条边。这个性质有时也称为MST性质。
构造最小生成树的两种方法:Prim算法和Kruskal算法。Kruskal最小生成树(MST):在Kruskal算法中,我们通过逐个的选取最优边来获得一个MST。每次选择最小权重并且不构成环的边。Prim小生成树算法:在prim算法中,我们也是逐个的选取最优边来获得一个MST。我们维持两组:已经包含在MST的顶点和顶点的集合不包括在内的。贪婪的选择是选择最小的重量边缘连接两组。
Prim算法
设G = (V,E)是连通带权图,V = {1,2,…,n}。构造G的最小生成树Prim算法的基本思想是:首先置S = {1},然后,只要S是V的真子集,就进行如下的贪心选择:选取满足条件i ∈S,j ∈V – S,且c[i][j]最小的边,将顶点j添加到S中。这个过程一直进行到S = V时为止。在这个过程中选取到的所有边恰好构成G的一棵最小生成树。
如下带权图:

生成过程:
1 -> 3 : 1
3 -> 6 : 4
6 -> 4: 2
3 -> 2 : 5
2 -> 5 : 3
实现:
/* 最小生成树(Prim)*/
#include Kruskal算法
当图的边数为e时,Kruskal算法所需的时间是O(eloge)。当 e=Ω(n2) 时,Kruskal算法比Prim算法差;但当 e=o(n2) 时,Kruskal算法比Prim算法好得多。给定无向连同带权图 G=(V,E) , V={1,2,…,n} 。Kruskal算法构造G的最小生成树的基本思想是:
(1)首先将G的n个顶点看成n个孤立的连通分支。将所有的边按权从小大排序。
(2)从第一条边开始,依边权递增的顺序检查每一条边。并按照下述方法连接两个不同的连通分支:当查看到第k条边(v,w)时,如果端点v和w分别是当前两个不同的连通分支T1和T2的端点是,就用边(v,w)将T1和T2连接成一个连通分支,然后继续查看第k+1条边;如果端点v和w在当前的同一个连通分支中,就直接再查看k+1条边。这个过程一个进行到只剩下一个连通分支时为止。
此时,已构成G的一棵最小生成树。
Kruskal算法的选边过程:
1 -> 3 : 1
4 -> 6 : 2
2 -> 5 : 3
3 -> 4 : 4
2 -> 3 : 5
实现:
/* Kruskal算法)*/
#include (cout, " "));
// cout << endl ;
}
else
{
m_nvFather[jfather] = ifather ;
// copy (m_nvFather.begin(), m_nvFather.end(), ostream_iterator (cout, " "));
// cout << endl ;
return true ;
}
}
private:
// 初始化并查集
int __init()
{
m_nvFather.resize (m_nSetEleCount) ;
for (vector<int>::size_type i = 0 ;
i < m_nSetEleCount;
++ i )
{
m_nvFather[i] = static_cast<int>(i) ;
// cout << m_nvFather[i] << " " ;
}
// cout << endl ;
return 0 ;
}
// 查找index元素的父亲节点 并且压缩路径长度
int __find (int nIndex)
{
if (nIndex == m_nvFather[nIndex])
{
return nIndex;
}
return m_nvFather[nIndex] = __find (m_nvFather[nIndex]);
}
private:
vector<int> m_nvFather ; // 父亲数组
vector<int>::size_type m_nSetEleCount ; // 集合中结点个数
} ;
class MST_Kruskal
{
typedef priority_queue MinHeap ;
public:
MST_Kruskal (const vector<vector<int> >& graph)
{
m_nNodeCount = static_cast<int>(graph.size ()) ;
__getMinHeap (graph) ;
}
void DoKruskal ()
{
UnionSet us (m_nNodeCount) ;
int k = 0 ;
while (m_minheap.size() != 0 && k < m_nNodeCount - 1)
{
TreeNode tn = m_minheap.top () ;
m_minheap.pop () ;
// 判断合理性
if (us.Union (tn.m_nVertexIndexA, tn.m_nVertexIndexB))
{
m_tnMSTree.push_back (tn) ;
++ k ;
}
}
// 输出结果
for (size_t i = 0; i < m_tnMSTree.size() ; ++ i)
{
cout << m_tnMSTree[i].m_nVertexIndexA << "->"
<< m_tnMSTree[i].m_nVertexIndexB << " : "
<< m_tnMSTree[i].m_nWeight
<< endl ;
}
}
private:
void __getMinHeap (const vector<vector<int> >& graph)
{
for (int i = 0; i < m_nNodeCount; ++ i)
{
for (int j = 0; j < m_nNodeCount; ++ j)
{
if (graph[i][j] != numeric_limits<int>::max())
{
m_minheap.push (TreeNode(i, j, graph[i][j])) ;
}
}
}
}
private:
vector 参考资料
- Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第1卷基本算法》,国防工业出版社,2002年
- Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第2卷半数值算法》,国防工业出版社,2002年
- Donald E.Knuth 著,苏运霖 译,《计算机程序设计艺术,第3卷排序与查找》,国防工业出版社,2002年
- Thomas H. Cormen, Charles E.Leiserson, etc., Introduction to Algorithms(3rd edition), McGraw-Hill Book Company,2009
- Jon Kleinberg, Ėva Tardos, Algorithm Design, Addison Wesley, 2005.
- Sartaj Sahni ,《数据结构算法与应用:C++语言描述》 ,汪诗林等译,机械工业出版社,2000.
- 屈婉玲,刘田,张立昂,王捍贫,算法设计与分析,清华大学出版社,2011年版,2013年重印.
- 张铭,赵海燕,王腾蛟,《数据结构与算法实验教程》,高等教育出版社,2011年 1月