决策树(Decision Tree)在机器学习中也是比较常见的一种算法,最早的决策树算法是ID3,改善后得到了C4.5算法,进一步改进后形成了我们现在使用的C5.0算法,综合性能大幅提高。
算法核心:为每一次分裂确定一个分裂属性。ID3采用的是“信息增益”为度量来选择分裂属性的。
本文在Excel中建模进行决策树分析,属于基础的决策树学习,有兴趣的可以在SPSS Modeler和Python中进行操作。
树模型(又称决策树或者树结构模型):基本思想和方差分析中的变异分解极为相似。
目的(基本原则):将总研究样本通过某些牲(自变量取值)分成数个相对同质的子样本。每一子样本因变量的取值高度一致,相应的变异/杂质尽量落在不同子样本间。所有树模型的算法都遵循这一基本原则。
不同树模型差异:差异在于对变异/杂质的定义不同。比如P值、方差、熵、Gini指数(基尼指数)、Deviance等作为测量指标。
决策树图例

现在我们来分析天气、温度、湿度、风这些属性对打球的影响

首先确定样本集信息熵,然后计算各个属性的信息增益进行对比分析。
熵:数据集中的不确定性、突发性或随机性的程度的度量。当一个数据集中的记录全部都属于同一类的时候,则没有不确定性,此时熵为0。
信息增益:按照某个属性A把数据集S分裂,所得到的信息增益等于数据集S的熵减去各个子集的熵的加权和。
计算是否打球的概率:

计算天气对打球的影响:



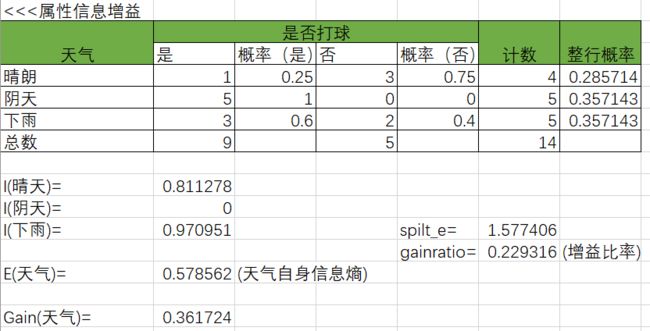
I(晴天)=-0.25*log(0.25,2)-0.75*log(0.75,2)=0.811278
E(天气)=0.285714*0.811278+0.357143*0+0.357143*0.70951=0.578562
Gain(天气)=E(all)-E(天气)=0.940286-0.578562=0.361724
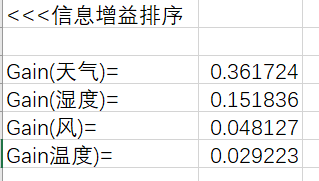
经计算得出天气的信息增益为0.361724,温度、湿度和风计算步骤类似


对各属性的信息增益进行降序排序,选择最大的作为分裂属性