1 前言
我在2018年6月份左右,系统性的速学习了一次吴恩达的《深度学习》系列课程。由于当时时间紧,虽然有完成课程中的作业和练习,但没有做详细的课程内容总结,所以导致现在对深度学习的印象零零散散,疑问多多。
在有一定的基础后,详细研究并复现经典的深度学习网络,无疑是最好的自学方法之一。
2 LeNet-5背景知识
(1)发明时间:1998年。
(2)发明人:LeCun 和 Bengio 等人。
(3)功能:识别手写数字0~9。
(4)成功应用:当年美国很多银行把它应用在支票数字识别上。那个年代深度学习就能够落地应用,真的不简单。当然其成功落地的原因,远不止模型设计这么简单,通过浏览46页的论文会发现,里面还做了其他相关工作。
(5)原始论文地址:http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf(英文)
(6)官方模型演示:http://yann.lecun.com/exdb/lenet/
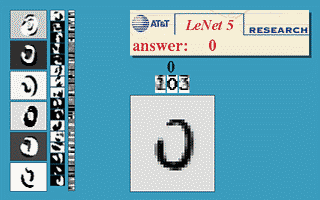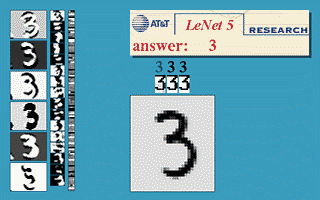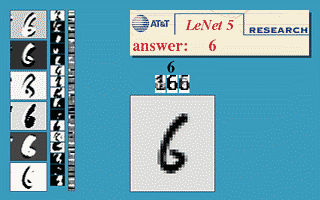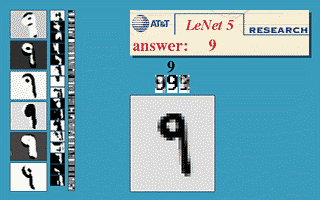
(7)(强烈推荐)模型的3D可视化演示:http://scs.ryerson.ca/~aharley/vis/conv/
3 LeNet-5详解
LeNet-5的整体网络结构图如下:
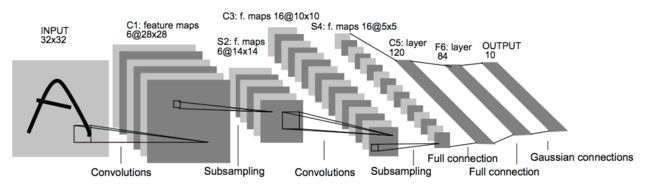
3.1 输入层:INPUT
输入图像大小统一要归一化为32×32,灰度图。

3.2 卷积层:C1
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
输出featuremap大小:28*28 (32-5+1)=28
神经元数量:28*28*6
可训练参数:(5*5+1) * 6
连接数:(5*5+1)*6*28*28=122304
注意:有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
156个参数怎么计算的?






上图就是6个卷积核经过模型训练后,最终被定型的“颜色”(就是一个5*5矩阵的可视化),每一个有5*5个格子,而每个格子的值会在网络训练过程中不断的自动优化,单个5*5的卷积核本身就有25个可训练参数。
此外,每一个卷积核在和图像做卷积计算时,还需加一个bias参数,这个值也是一个可训练参数。
所以,总的可训练参数就是:(5*5 + 1)* 6 = 156
(PS:上述6个卷积核,一一对应下图的卷积结果图,可看出第3、4号卷积核成“十字叉”对称,而3,4号卷积结果图的数字边缘高亮部分也成互补形态。)

3.3 池化层:S2
输入:28*28
采样区域:2*2
步长:2
输出featureMap大小:14*14(28/2)
神经元数量:14*14*6
连接数:(2*2+1)*6*14*14
S2中每个特征图的大小是C1中特征图大小的1/4

3.4 卷积层:C3
输入:S2中6个特征图的组合输入,共有16种输入方式,如下图所示:
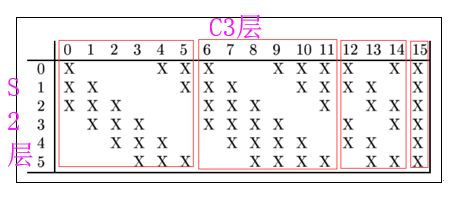
作者使用这种数据输入方式的原因:
(1)可以减少计算量。(1998年计算能力有限)
(2)打破了网络的对称性,不完全连接能够保证C3中不同特征图提取不同特征。(作者认为这个是重点原因)
卷积核大小:5*5
卷积核种类:16
输出featureMap大小:10*10 (14-5+1)=10
可训练参数:6*(3*5*5+1) + 6*(4*5*5+1) + 3*(4*5*5+1) + 1*(6*5*5+1)=1516
解释:上述计算中,第1个“6”指的是C3层第1-6号特征图,他们的输入选择的是S2中任意3个特征图,后面依次类推。
连接数:10*10*1516=151600
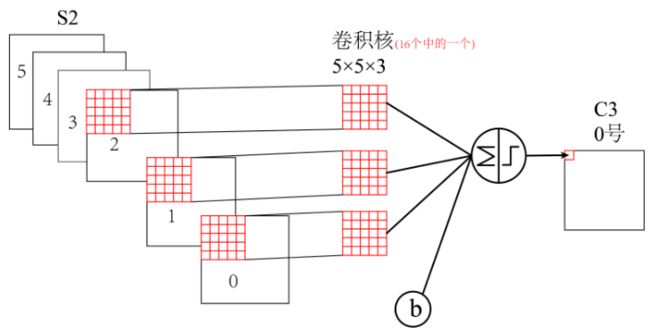
C3与S2中前3个图相连的卷积结构如下图所示:

3.5 池化层:S4
输入:10*10
采样区域:2*2
步长:2
输出featureMap大小:5*5(10/2)
神经元数量:5*5*16=400
连接数:16*(2*2+1)*5*5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
3.6 卷积层:C5(也可以理解成“全连接层”)
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核个数:120
输出featureMap大小:1*1(5-5+1)
可训练参数/连接:120*(16*5*5+1)=48120
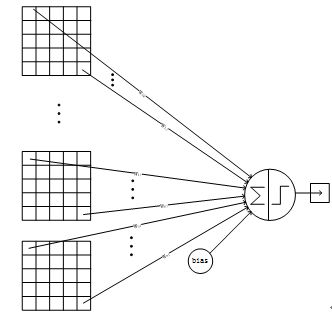
C5层的网络结构如下:

3.7 全连接层:F6
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
详细说明:F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。ASCII编码图如下:

F6层的连接方式如下:
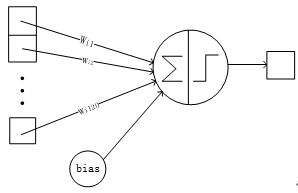

3.8 Output层-全连接层:F7
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:
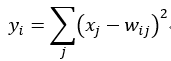
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。
LeNet-5识别数字3的过程如下:
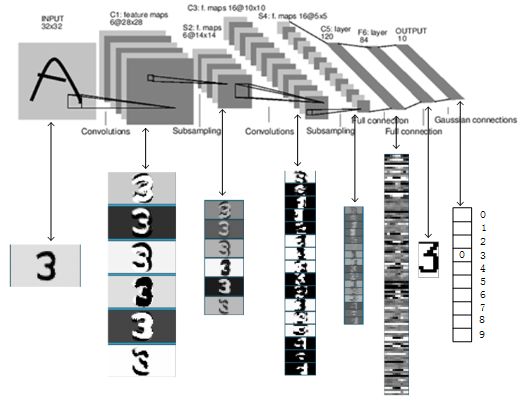

3.9 LeNet-5网络3D全貌图
3.10 LeNet-5网络总结
(1)没有用 padding 技术,对图片边缘的信息处理不够。
(2)池化为了加快收敛,防止过拟合。池化用的是平均池化 average_pooling, 当下主要是最大值池化 max_pooling。
(3)激活函数用的 tanh, 当下主要用 relu,因为 relu 收敛更快。
(4)filters 每一步都在增大,主要是为了避免丢失信息。用多个不同的 kernel 去学习前一层 feature map 中的特征。
(5)训练的时候用到了数据增强 augmentation。
(6)优化器,应该是用的 SGD。
(7)没有 dropout 技术。
(8)模型较小,学的特征不够多,无法处理较大较复杂的数据集。
(9)原始论文中C3与S2并不是全连接而是部分连接,这样能减少部分计算量。而现代CNN模型中,比如AlexNet,ResNet等,都采取全连接的方式了。
(10)按照原文描述,网络最后一层为高斯连接层。而我们为了简单起见还是用了全连接层。
LeNet其实是一个比较“古老”的模型了,我们不必追求完美的复现,理解其中关键的概念即可。
3.11 主要参考资料
(1)https://www.jianshu.com/p/0c6c4c9eee27
(2)https://cuijiahua.com/blog/2018/01/dl_3.html
(3)https://blog.csdn.net/saw009/article/details/80590245
(4)https://blog.csdn.net/luke_sanjayzzzhong/article/details/89641592
3.12 备注
在寻找资料研究LeNet-5网络中,发现在细节方面有不同的版本,特别是在代码复现过程中,我寻找了20篇以上的复现代码,在C3层没有一个是真正按照论文中的方法来组合式输入数据的,全部是将S2层数据简单的作为C3层输入。当然,这种数据输入方式,应该也算是神经网络调参的一种,原始论文中那种方式很难用keras框架实现(如果有谁能用Keras复现论文中那种方式,希望能够留言)。
4 Keras复现
深度学习框架:TensorFlow 2.0.0-alpha0
数据集:mnist
由于mnist数据集中图像大小时28*28,所以LeNet网络将会变成如下形式:
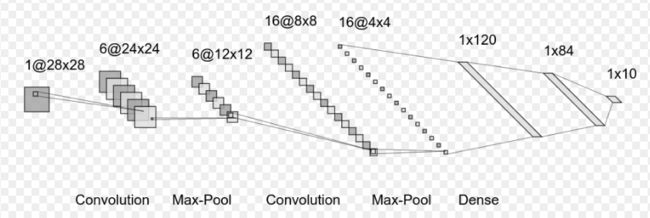
4.1 加载数据
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import numpy as np mnist_data = np.load('mnist.npz')
4.2 制作数据集
import numpy as np mnist_data = np.load('mnist.npz') print(mnist_data.files) x_train = mnist_data['x_train'] y_train = mnist_data['y_train'] x_test = mnist_data['x_test'] y_test = mnist_data['y_test'] print(x_train.shape, ' ', y_train.shape) print(x_test.shape, ' ', y_test.shape)

4.3 可视化数据
import matplotlib.pyplot as plt plt.imshow(x_train[0]) plt.show() print(y_train[0])
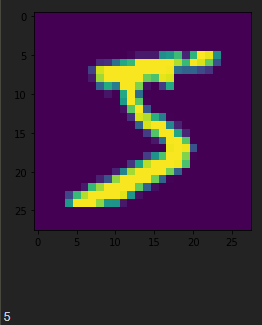
4.4 调整数据结构
x_train = x_train.reshape((-1, 28, 28, 1))
x_test = x_test.reshape((-1, 28, 28, 1))
4.5 LeNet-5网络模型搭建
from tensorflow.keras import layers,Input from tensorflow.keras.layers import Dense,Conv2D,MaxPool2D,Flatten,AveragePooling2D from tensorflow.keras.models import Model # 这部分返回一个张量 inputs = Input(shape=(28, 28, 1), name = 'Input') # C1卷积层 x = Conv2D(input_shape=(28,28,1), filters=6, kernel_size=(5,5), strides=(1,1), activation='tanh', name = 'C1')(inputs) # S2池化层 x = AveragePooling2D(pool_size=(2,2), strides=(2,2), name = 'S2')(x) # C3卷积层 x = Conv2D(filters=16, kernel_size=(5,5), strides=(1,1), activation='tanh', name = 'C3')(x) # S4池化层 x = AveragePooling2D(pool_size=(2,2), strides=(2,2), name = 'S4')(x) # C5卷积层 x = Conv2D(filters=120, kernel_size=(4,4), strides=(1,1), activation='tanh', name = 'C5')(x) # Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。 x = Flatten()(x) # F6全连接层 x = Dense(84, activation='tanh', name = 'F6')(x) # 全连接层 predictions = Dense(10, activation='softmax', name = 'Output')(x) model = Model(inputs=inputs, outputs=predictions)
4.5 显示模型结构
model.compile(optimizer=keras.optimizers.Adam(), loss=keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) model.summary()
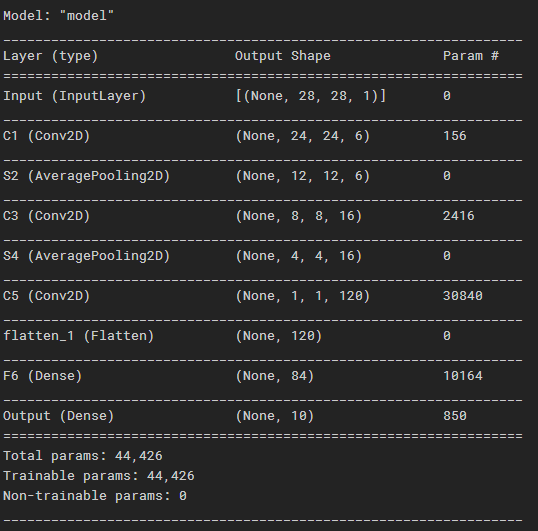
4.6 开始训练!
history = model.fit(x_train, y_train, batch_size=64, epochs=5, validation_split=0.1)

4.7 显示训练结果
plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.legend(['training', 'valivation'], loc='upper left') plt.show()

4.8 用测试集评估模型
res = model.evaluate(x_test, y_test)
![]()
4.9 输出模型中间层的特征图结果
layer_name = 'S2' #S2池化层 intermediate_layer_model = Model(inputs = model.input, outputs = model.get_layer(layer_name).output) intermediate_output = intermediate_layer_model.predict(x_train)
intermediate_output.shape
![]()
intermediate_output[1].shape
![]()
plt.imshow(intermediate_output[0,:,:,0]) #输出6万张训练图中,第1个mnist图像(上图中那个‘5’)经过S2池化层后的第一个特征图结果。(S2池化层,总共会产生6个特征图) plt.show()

4.10 用模型测试单张图片
import cv2 import numpy as np image = cv2.imread('7.jpg',0) image = cv2.resize(image, (28, 28)) image = np.expand_dims(image, axis=0) image = image.reshape((-1, 28, 28, 1)) predict = model.predict(image) print(predict)

疑问:
我输入的图片如下图所示:

但是predict的结果并没有显示出他属于哪个数字,模型预测结果数组中,每个元素代表哪一类如何确认?(手动验证除外)
4.11 将模型结构图保存到本地
#输出模型图 from tensorflow.keras.utils import plot_model plot_model(model, to_file='model.png')
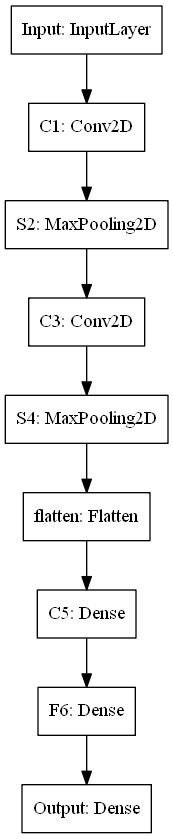
5 Pytorch复现
pytorch版本:1.1
5.1 定义网络的结构和前向传播过程
#定义网络的结构和前向传播过程 import torch.nn as nn from collections import OrderedDict class LeNet5(nn.Module): def __init__(self): super(LeNet5, self).__init__() # (1,6,~~~) # 1:输入数据的通道数 # 6:卷积核个数 # stride步长默认为1 # nn.Sequential,将若干个功能层组合到一起。 self.convnet = nn.Sequential(OrderedDict([ ('c1', nn.Conv2d(1, 6, kernel_size=(5, 5))), ('relu1', nn.ReLU()), ('s2', nn.MaxPool2d(kernel_size=(2, 2), stride=2)), ('c3', nn.Conv2d(6, 16, kernel_size=(5, 5))), ('relu3', nn.ReLU()), ('s4', nn.MaxPool2d(kernel_size=(2, 2), stride=2)), ('c5', nn.Conv2d(16, 120, kernel_size=(5, 5))), ('relu5', nn.ReLU()) ])) # 定义后半部分的全连接层 self.fc = nn.Sequential(OrderedDict([ ('f6', nn.Linear(120, 84)), ('relu6', nn.ReLU()), ('f7', nn.Linear(84, 10)), ('sig7', nn.LogSoftmax(dim=-1)) ])) #定义网络的前向运算 def forward(self, img): output = self.convnet(img) # 在第一个全连接层与卷积层连接的位置 # 需要将特征图拉成一个一维向量 output = output.view(img.size(0),-1) output = self.fc(output) return output
pytorch中另一种构造网络的方式:
self.conv1 = nn.Sequential( #padding=2,将图片由28*28变成32*32 nn.Conv2d(1,6, kernel_size=(5, 5), stride=1, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2) ) self.conv2 = nn.Sequential( nn.Conv2d(6,16,5), nn.ReLU(), nn.MaxPool2d(kernel_size=(2, 2), stride=2) ) self.conv3 = nn.Sequential( nn.Conv2d(16,120,5), nn.ReLU() ) self.fc1 = nn.Sequential( nn.Linear(120, 84), nn.ReLU() ) self.fc2 = nn.Linear(84, 10) #网络前向传播过程 def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) #全连接层均使用的nn.Linear()线性结构,输入输出维度均为一维,所以需要把数据拉为1维 x = x.view(x.size(0), -1) x = self.fc1(x) x = self.fc2(x) # x = self.fc3(x) return x
5.2 定义数据读取,以及网络的优化过程,并开始训练
# 定义数据读取,以及网络的优化过程。 # 实现网络模型的训练。 from LeNet import LeNet5 import torch import torch.nn as nn import torch.optim as optim from torchvision.datasets.mnist import MNIST import torchvision.transforms as transforms from torch.utils.data import DataLoader # 读取数据 data_train = MNIST('../data/mnist', download=True, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor()])) data_test = MNIST('../data/mnist', train=False, download=True, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor()])) # num_workers=8 使用多进程加载数据 data_train_loader = DataLoader(data_train, batch_size=256, shuffle=True, num_workers=8) data_test_loader = DataLoader(data_test, batch_size=1024, num_workers=8) # 初始化网络 net = LeNet5() # 定义损失函数 criterion = nn.CrossEntropyLoss() # 定义网络优化方法 optimizer = optim.Adam(net.parameters(), lr=2e-3) # 定义训练阶段 def train(epoch): net.train() loss_list, batch_list = [], [] for i, (image, labels) in enumerate(data_train_loader): # 初始0梯度 optimizer.zero_grad() # 网络前向运行 output = net(image) # 计算网络的损失函数 loss = criterion(output, labels) #存储每一次的梯度与迭代次数 loss_list.append(loss.detach().cpu().item()) batch_list.append(i+1) if 1 % 10 == 0: print('Train - Epoch %d, Batch: %d, Loss: %f' % (epoch, i, loss.detach().cpu().item())) # 反向传播梯度 loss.backward() # 优化更新权重 optimizer.step() # 保存网络模型结构 torch.save(net.state_dict(), 'model//' + str(epoch) + 'LeNet5_model.pkl') # 定义验证阶段 def test(): net.eval() total_correct = 0 avg_loss = 0.0 # 取消梯度,避免测试阶段out of memory with torch.no_grad(): for i, (images, labels) in enumerate(data_test_loader): output = net(images) avg_loss += criterion(output, labels).sum() # 计算准确率 pred = output.detach().max(1)[1] total_correct += pred.eq(labels.view_as(pred)).sum() avg_loss /= len(data_test) print('Test Avg. Loss: %f, Accuracy: %f' % (avg_loss.detach().cpu().item(), float(total_correct) / len(data_test))) def train_and_test(epoch): train(epoch) test() def main(): for e in range(1, 16): train_and_test(e) if __name__ == '__main__': main()
训练结果如下:
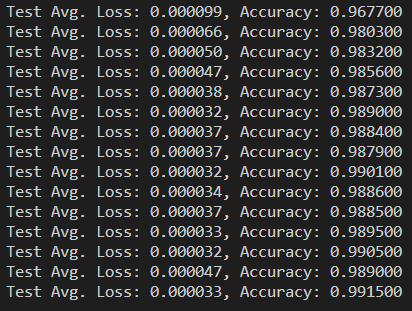
5.2 如有训练好的模型,直接加载模型,并测试模型效果:
# 利用训练好的网络权重来重现网络模型 from LeNet import LeNet5 import torch from torchvision.datasets.mnist import MNIST import torchvision.transforms as transforms from torch.utils.data import DataLoader # 读取数据 data_test = MNIST('./data/mnist', train=False, download=True, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor()])) # num_workers = 8 使用多进程加载数据 data_test_loader = DataLoader(data_test, batch_size=1024, num_workers=8) # 初始化网络 net = LeNet5() net.load_state_dict(torch.load(r'model\15LeNet5_model.pkl')) def deploy(): # 验证阶段 # net.eval() total_correct = 0 for i, (image, labels) in enumerate(data_test_loader): output = net(image) # 计算准确率 pred = output.detach().max(1)[1] total_correct += pred.eq(labels.view_as(pred)).sum() print('Accuracy: %f' % (float(total_correct) / len(data_test))) def main(): deploy() if __name__ == '__main__': main()
结果如下:
