缘由
近期在写一些字符串函数的优化,兴趣使然。但是写的过程中,想要实现 SSE2 128 bit / 64 bit 的按 bit 逻辑位移。遇到了一个大坑,且听我娓娓道来。
我并不想用什么马航370来博眼球。当我写下这个标题的时候,的确没有马航370这个字眼,但是当我写到一半的时候,突然就冒出了马航370这几个字,假设你认真阅读了我的文章,或许你也应该思考一下。这 128 bit / 64 bit 的位移指令究竟是去哪了?石沉大海了?那不就跟马航370一样吗,是一个谜,一个很很大的谜。。。。
假设你对 MMX, SSE 位移指令不太懂,能够先看看:
http://tommesani.com/index.php/simd/44-mmx-shift.html ,
这个比較easy理解,我当初学习 MMX, SSE 指令都是从这里開始的。
可是这个仅仅写到 MMX 指令集,更新的版本号看后面的。
逻辑位移
对于 MMX, SSE 的位移指令。我们非常自然的想到:
逻辑左移:PSLLW/PSLLD/PSLLQ。Shift Packed Data Left Logical (压缩逻辑左移)
逻辑右移:PSRLW/PSRLD/PSRLQ,Shift Packed Data Right Logical (压缩逻辑右移)
顾名思义,W 指的是Word(字),D 指的 DWORD (双字),Q 指的是 QWORD (四字),PSLLW 实现的是按 Word 的分组逻辑左移,
PSLLD 是按 DWORD 的分组逻辑左移,PSLLQ 是按 QWORD 实现的分组逻辑左移,这一切看起来都非常 OK 。
这里以逻辑左移为例:
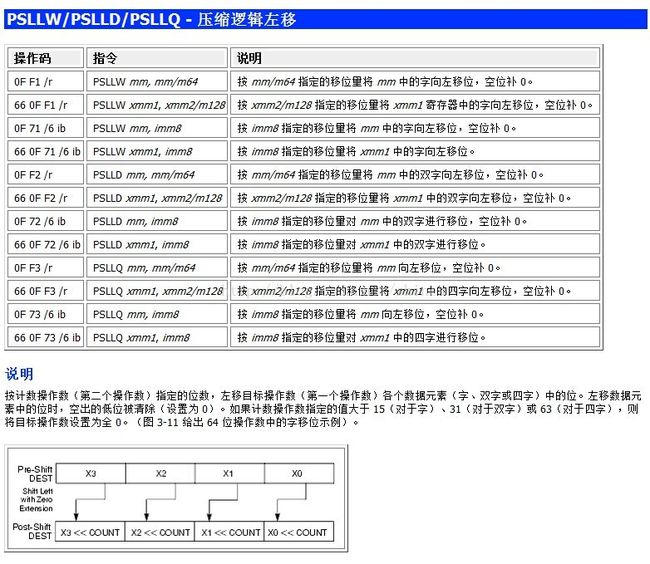
关于详细的逻辑左移指令的说明,可參考:
http://moeto.comoj.com/project/intel/instruct32_hh/vc256.htm
或者 http://x86.renejeschke.de/html/file_module_x86_id_259.html,
右移也是类似的。在此不再螯述。
问题来了
我们要实现的是 128bit 的逻辑位移,SSE2 里面有 PSLLDQ / PSRLDQ 指令,这里 DQ 即是 Double QWORD 的意思。
这不正好是我们须要的 128bit 按 bit 位移吗?No!。别高兴得太早。我们来看看 Intel 的文档:
PSLLDQ--Packed Shift Left Logical Double Quadword
或
http://moeto.comoj.com/project/intel/instruct32_hh/vc255.htm
截图例如以下:
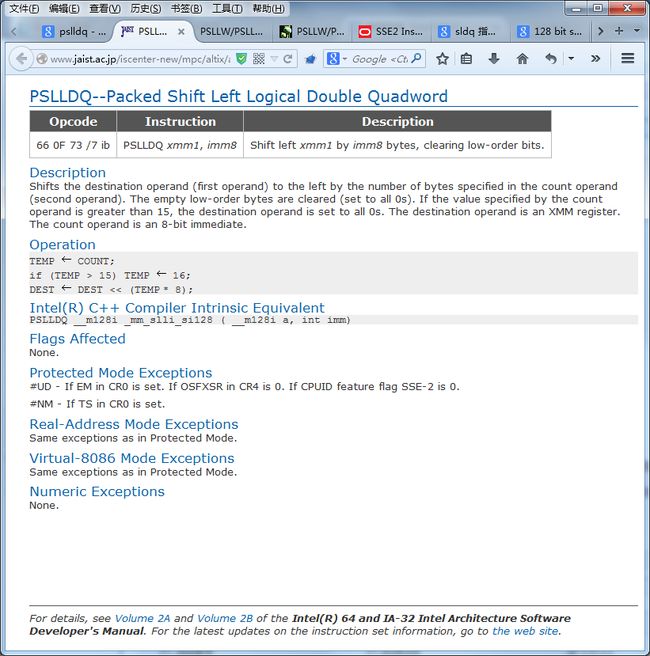
我们看到。非常遗憾。SSE2 并没有实现 128bit 的按 bit 位移,PSLLDQ 仅仅能实现 128bit 的按 byte 位移。即最小位移量必须是一个 byte (即8个bit),这非常不科学,更不科学的是位移量仅仅能是马上数。考虑到 Intel 并未真正实现 128bit 数据处理(SSE 大多数指令都仅仅实现了最多 64bit 粒度的数据处理。比如一个双精度浮点数是 64bit 的)。好吧,我们认了。可是!!可是。!
Intel 你没搞错吧。PSLLDQ 的操作数仅仅支持 imm8,imm8 意味着什么?imm8 是 8 位马上数的意思。那就是说我们仅仅能在汇编里写死(常数)。不能使用不论什么寄存器来做位移量。What the fu*K??
好吧,这我们也认了。。。CPU 是你设计的,我们拿你没办法。说句题外话。假设 PSLLDQ 支持 reg32, reg64 寄存器位移的话, 会方便非常多,由于我们能够先用 PSLLDQ 位移足够位数的按 Byte 位移,然后再用 PSLLQ 位移剩下的剩余量(这是后话,为什么要这么用。到后面你就知道),但是,如今这样的方法都不行。!
这个 imm8 彻底让我蛋碎了。。。PSLLQ 对于128 bit 寄存器一次仅仅能移 16 位(先破埂了)。那么意味这我们假设要用这样的方法,要 if / jump 好几次。
。
。
大坑開始
好吧,我们退而求其次。既然你不能实现 128 bit 的按 bit 位移。那我们分成两个 64 bit 的位移来实现好了,无非是多一次推断,多一次合并。尽管效率没有直接128 bit 位移的高,可是苦于你没实现嘛,仅仅能这么干了。。
。
好吧,我们開始吧。。
。。GO!
。。好了,我们换成 PSLLQ 了,运行PSLLQ xmm0, 32 或 PSLLQ xmm0, ecx (这里ecx的值为32),咦?xmm0怎么全为0了??啊,怎么回事??
我们回过头来又一次看看 intel 的文档:

重点看两个我用红线框起来的。当 PSLLQ 作用于 64 bit 的寄存器时。我们看到是最大支持 COUNT = 64 位的位移(严格意义上讲是 max = 63。这个不纠结了。习惯问题。下同)。
可是当 PSLLQ 作用于 128 bit 寄存器时。奇怪的事情发生了,最大仅仅支持 COUNT = 16 位的位移(严格意义上是15位),如上图所看到的。
假设不是又一次看 Intel 的文档,假设不是调试中发现问题,谁能想到最多仅仅能移15位???Intel 的脑袋是被门夹了吗??Why??MMX 寄存器上都能够实现最多 63 位的位移, SSE 寄存器为什么就不能够?尽管我们知道 MMX 寄存器和 SSE 寄存器是不一样的,分开的,MMX 寄存器是借用 x87 浮点寄存器来实现 MMX 指令的,但是你在 MMX 寄存器上实现了 64 bit 的位移,为什么在 128 bit 的 SSE 寄存器上却仅仅能移最多 15 位??你说难以实现,我认了。我不太懂为什么那么难。我们仅仅能认了。但是你却实现了 128 bit 的按 byte 位移的 PSLLDQ 指令,这又作何解释??本来顾名思义,PSLLDQ 就来就应该是实现 128 bit 的按 bit 位移,限于历史原因,这个没实现我能够理解。但是你没有理由在 PSLLQ 作用于 128 bit 的 SSE 寄存器时却最多仅仅能位移 15 位吧??这真的有那么难吗??真的难吗????真的那么难。你又是怎么实现 PSLLDQ 的 128 bit 按 Byte 位移的??
寻求答案
带着这些疑问,我们问了一下 Google 老先生,搜索“128 bit shift”,发现 N 多小伙伴都遇到过这个问题,比如:
Looking for sse 128 bit shift operation for non-immediate shift value
What is SSE !@#$% good for?
#2: Bit vector operations
最后,Google老先生告诉了我们一个最好的解答,来自 Intel 的论坛,在这里:
Missing instruction in SSE: PSLLDQ with _bit_ shift amount?
是这种,截图例如以下:

首先,Intel 是承认这个 missing instruction(丢失的指令)的,我们也意识到 missing instruction 无处不在。仅仅是这个有点过分。
上面的回复,大意是:(E文不是太好,用 Google 辅助翻译的。见谅)
Hi Geoff,
我们的一个project师提供了下面回应,并做一些澄清。
你这个问题是正确的,对于 SIMD(单指令多数据流) 来说。在当前的指令集里,bit 位移是比按 byte 位移难于实现的(指的是 SSE 寄存器
的 128 bit 按 bit 位移)。不幸的是。这不是一个小改变。实现一个这种按 bit 位移指令。
这里有很多其它的改变比简单的在马上字节里适应位移
距离--硬件实际完毕按 bit 位移是一个被限制的问题。
假设你有一个使用案例关于为什么这个操作是实用的,随着应用程序将受益于这个操作。这是我们有兴趣听到的。普通情况下,我们试图
设计新的指令来满足特定的需求。而不是仅仅是提供 "missing instuctions“ (丢失指令)的支持。从实际情况来看,有非常多这种 "missing instuctions“
——更有趣的问题是。假设在实际的应用中应对这些 "missing instuctions“ 所带来的问题。
博主观点:
对于 128 bit 的按 bit 位移比較难以实现。这我能理解,但是 PSLLQ 对于 SSE 的 128bit 寄存器仅仅能最多位移15位我就不能理解了……
SSE2 的 128bit/64bit 位移你在哪里,为什么是15而不是31,63?亲爱的马航MH370,你究竟在哪里?为什么要选择飞中国的航班?为什么??
解决之道
解决的办法有非常多种,前面也讲过一个。就是:假设你要左移 count 位。先用 PSLLDQ 位移 x * 8 位。 这个是纯 128 bit 的位移,然后再用 PSLLQ 位移剩下的 y = (count - x * 8) 位,这里 y 要小于 16。可是因为 PSLLDQ 仅仅能运行imm8马上数。所以你要先 if / jump 推断一下 count 的值。分别运行 PSLLDQ xmm0, 32; 或 PSLLDQ xmm0, 16; 或 PSLLDQ xmm0, 8; PSLLDQ xmm0, 4; PSLLDQ xmm0, 2; 以后。再运行 PSLLQ 位移剩下的 Y 位。这里PSLLDQ xmm0, 32或许能够用别的 SSE Shuffle 指令取代。可是是一样的,最大的问题是你要先 if 先推断一下再运行对应的指令。这样的方法并不见得高效。
我们再来找一些好一点的办法:
既然,SSE 里我们没办法实现 64 bit 的位移,可是 MMX 寄存器里是能够的,可是我们又要在 SSE 寄存器里实现,那么我们能够先把数据从 SSE 寄存器里转移到 MMX 寄存器。位移好了,再合并到 SSE 寄存器里。尽管这个过程有点繁琐,可是相比上面第一种方法。还是高效了不少,并且有一关键的地方,非常多时候。我们要做这个位移,都是接近终于输出结果的时候,这个时候就不必把数据合并回 SSE 寄存器了,能够直接用 MMX 寄存器的值作为输出就可以,这样又快了一点儿。还不赖。
还有没有解决的办法,应该还有,容我再想一想,或者读者你也想想?有网友贴了 AVX 版的 VPSLLDQ 指令说明,但是相同仅仅支持 imm8 马上数,并且并非全部人的 CPU 都支持 AVX 的,博主本人的 CPU 就不支持。
后记
我们如今遇到的问题做一个比喻,就是:我们前面有三条路,一条是大路,一条是小路,一条是其它未知的路,我们以为大路(PSLLDQ)最快。于是选择先走了大路,结果发现直接走是过不去的;转而选择小路(PSLLQ),走小路,结果发现有个陷阱,这个陷阱让我们到不了目的地,仅仅能达到1/4。然后再回过头来看看大路。大路事实上能够过去的,可是踩下去以后全是泥潭(仅仅支持马上数的128位 byte 位移),要走过去,非常艰难。那么我们仅仅能选择第三条未知的路了(各种其它指令的组合模拟实现)。
Intel 的 MMX, SSE 各种缺失的指令由来已久,指令的设计也是混乱不勘,另一个比較著名的就是仅仅实现了POR, PAND, PANDN(and not),没有实现 PNOT (即对MMX, SSE寄存器取反),尽管 PNOT 的确能够用 PANDN 实现(你至少须要2个寄存器),或者用 PCMPEQB xmm0, xmm0 来实现 全置 1 的操作,可是有可能添加了寄存器的占用,可能会添加指令周期,反正是各种不好。尽管影响不算大,可是有时候寄存器捉襟见肘的时候,还是很蛋疼的。
另一点更可笑的是。我跟你说了,你一定会相信 Intel 是荒唐的,我们的确须要的是无符号的逻辑左/右移,可是假设你要实现的是有符号的右移(算术右移),能够使用 PSRAW/PSRAD 指令 - 压缩算术右移,另外说一下。不存在算术左移。由于算术左移和逻辑左移是一回事。可參考:
http://moeto.comoj.com/project/intel/instruct32_hh/vc257.htm
很可笑的是。在这里。Intel 却实现了对于 128 bit 寄存器最多 31 位的位移,更可笑的。对于 64 bit 寄存器最多的位移数也是 31(见上面的链接)。这你能懂???究竟是我们的智商有问题,还是 Intel 的智商有问题?!
。
看下图:

PS:纠正一下,上面这个举例是错误的(是我看错了),Intel 并没有实现 PSRAQ。上面这个是 PSRAD 的。是针对 DWORD 的。而不是 QWORD,所以他这么实现是正确的,这里并没有问题。
这个问题,在另外一个著名的帖子里也有提到:
千分求汇编优化:UInt96x96To192(...)

到眼下为止,都未实现 PSRAQ 指令。
.