由于 JavaScript 动态渲染的页面不止 Ajax 这一种,有些网站获取数据并不包含Ajax请求,有些网站是对 Ajax 进行加密处理;为了解决这写问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就可见即可抓。
Python提供了许多模拟浏览器运行的库,如 Selenium、Splash、PyV8、Ghost 等;我们接下来以 Selenium为例,那么要使用的话我们就必须要做相应的安装,这里要注意一点的是由于我们操作的是 谷歌浏览器,因此再使用这个库之前必须要先安装好 谷歌浏览器以及操作浏览器的驱动执行文件。
一、操作前准备
- 安装谷歌浏览器
- 通过命令安装库:pip install selenium
- 下载谷歌浏览器驱动并配置环境变量 http://npm.taobao.org/mirrors/chromedriver/
二、基本操作
- 自动打开百度首页并休眠几秒钟后自动关闭
from selenium import webdriver
import time
driver = webdriver.Chrome() # 创建实例
driver.get("http://www.baidu.com") # 请求百度首页
time.sleep(6) # 睡眠六秒
driver.quit() # 退出浏览器
执行代码后即可看到如下效果:

image.png
-
接下来我们以一下网页操作为例子(代码中有详细的注释),先看网页效果:
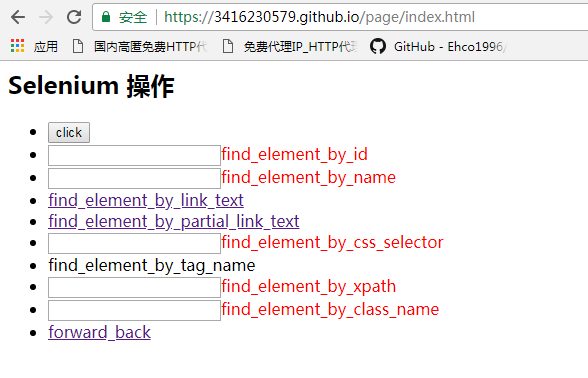 image.png
image.png
操作代码如下(注:操作的组件即属性的话在源码中查看):
from selenium import webdriver
import time
# driver = webdriver.Chrome() # 创建实例
# driver.get("http://www.baidu.com") # 请求百度首页
# time.sleep(6) # 睡眠六秒
# driver.quit() # 退出浏览器
# browser = webdriver.Chrome()
# browser.get("https://3416230579.github.io/page/index.html")
# 操作一
#elemt = browser.find_element_by_id("element_id") #根据 id 获取对象
# elemt = browser.find_element_by_name("element_id") #根据 name 获取对象
# print(elemt.tag_name) #返回标签名
# print(elemt.text) #返回标签的值
# elemt.send_keys("哈哈哈")#给标签输入值
# 操作二
# elemt = browser.find_element_by_link_text("find_element_by_link_text")
# print(elemt.tag_name) #返回标签名
# print(elemt.text) #返回标签的值
# elemt.click()#点击
# 操作三
# 利用 css选择器 获取 class='highlight' 标签对象并自动填值
# elemt = browser.find_element_by_css_selector(".highlight")
# elemt.send_keys("啦啦啦")
# # 利用 xpath 获取 id='xpathname' 标签对象并自动填值
# elemt = browser.find_element_by_xpath(r'//*[@id="xpathname"]')
# elemt.send_keys("我的 xpath")
# 操作四
# 获取跳转后页面的源码
# time.sleep(2)
# elemt = browser.find_element_by_link_text("find_element_by_link_text")
# elemt.click()
# browser.switch_to_window(browser.window_handles[1])
# print(browser.page_source)
# 操作五
# 操作弹出框
# time.sleep(2)
# elem = browser.find_element_by_tag_name("button")
# elem.click()
# time.sleep(2)
# browser.switch_to_alert().accept() # 切换到弹出框操作
# 操作六
# 跳转和回退操作
# time.sleep(2)
# elem = browser.find_element_by_link_text("forward_back")
# elem.click() # 点击跳转
# time.sleep(1)
# browser.back() # 点击回退
# time.sleep(2)
# browser.forward() # 调到上一次点击
# time.sleep(1)
# browser.back() # 回退
# 操作七
# Cookies 的操作
# browser = webdriver.Chrome()
# browser.get("https://www.baidu.com")
# print(browser.get_cookies()) # 输出全部的 cookie 的信息
# 添加一个 cookie
# browser.add_cookie({"name":"luchangyin", "domian":"www.baidu.com","value":"肥牛冲天"})
# print(browser.get_cookies())
# browser.delete_all_cookies() # 全部删除
# print(browser.get_cookies())
# 操作八
# 自动打开百度并根据关键字搜索相关的内容
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
elem = browser.find_element_by_id("kw")
elem.send_keys("python爬虫") # 输入
time.sleep(2) # 休眠
elem.send_keys(Keys.RETURN) # 回车
time.sleep(3)
browser.quit() # 关闭
三、实战 - 登录知乎并爬取信息
1)先看观察登录界面的标签规律:

image.png
2)导入我们所需要的所有包:
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
3)根据效果图编写登录代码:
# 声明浏览器对象
browser = webdriver.Chrome()
browser.get("https://www.zhihu.com/signin")
def login_zhihu(browser):
try:
#获取登录用户名
elem = browser.find_element_by_name("username")
elem.clear() # 清空
elem.send_keys("用户名") # 自动填值
elem.send_keys(Keys.RETURN)#回车
time.sleep(3)
#获取登录密码
elem = browser.find_element_by_name("password")
elem.clear()
elem.send_keys("密码")
elem.send_keys(Keys.RETURN)#回车
time.sleep(2)
print("开始登陆...")
#Button SignFlow-submitButton Button--primary Button--blue
elem = browser.find_element_by_css_selector(".Button.SignFlow-submitButton.Button--primary.Button--blue")
#elem = browser.find_element_by_xpath(r'//button[@class="Button SignFlow-submitButton Button--primary Button--blue"]')
elem.click()
print("开始休眠...")
#显示等待 选择“首页”选项
element = WebDriverWait(browser, 15).until(EC.title_contains(u'首页'))
print("已选择...")
except TimeoutException:
print("Time Out")
except NoSuchElementException:
print("No Element")
-
观察登陆后的页面:
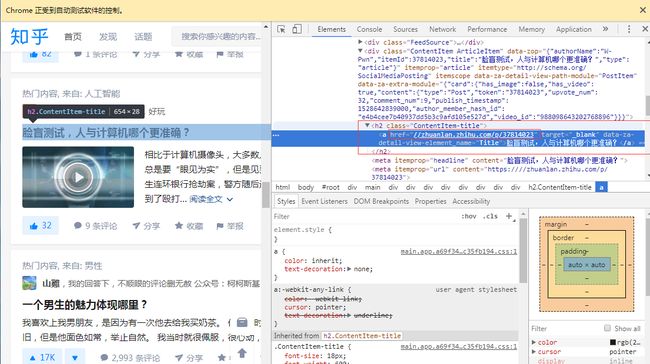 image.png
image.png - 获取代码如下:
# url 去重
urls = set()
def get_information(browser):
print("开始获取信息。。。")
elems = browser.find_elements_by_css_selector(".ContentItem-title")
for elem in elems:
link_elem = elem.find_element_by_tag_name("a")
if link_elem.text in urls:
pass
else:
print(link_elem.text) # 标题
print(link_elem.get_attribute("href")) # 链接
urls.add(link_elem.get_attribute("href"))
6)将进度条自动下拉到最底部实现 js 的加载:
# 滚动加载
def scroll_load(browser):
#利用 execute_script() 方法将进度条下拉到最底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
browser.implicitly_wait(2) # 隐式等待
7)编写主函数并调用:
# 主主函数
def main():
login_zhihu(browser) # 登录函数
for i in range(3): #滚动三次
get_information(browser) # 获取标题与链接
scroll_load(browser) # 滚动
time.sleep(1) # 休眠
# 函数入口调用
if __name__ == '__main__':
main()
input("按任意键退出-> ")
browser.quit()
运行结果如下:
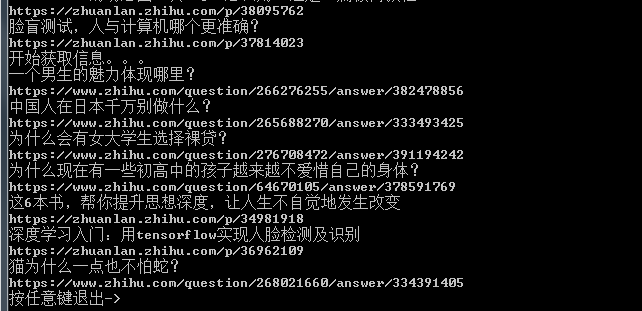
image.png
8)当使用有界面爬取少量页面信息的方式还好,但是爬取很多页面的话那可就不好了-太多弹出窗口页面,值得注意的是: 从 Chrome 59 开始已经开始支持 Headless 模式,即无界面模式,这样爬取的时候就无需弹出浏览器界面了,接下来我们简单的去使用以下:
chrome_options = webdriver.ChromeOptions() # 获取 ChromeOptions 对象
chrome_options.add_argument('--headless') # 添加 headless 参数
browser = webdriver.Chrome(chrome_options=chrome_options) # 初始化 Chrome 对象
browser.get(r"http://www.baidu.com/")
# 截屏
browser.get_screenshot_as_file("C:\\Users\\Administrator\\Desktop\\aaa\\daima\\lcy.jpg")
html = browser.page_source # 这里是源码,接下来就可以使用 正则 或者 xpath 表达式解析了
print("成功提取源码-> ", html)
执行程序之后输出源码的同时在制定的地址中可以看到截取的图片,效果如下:
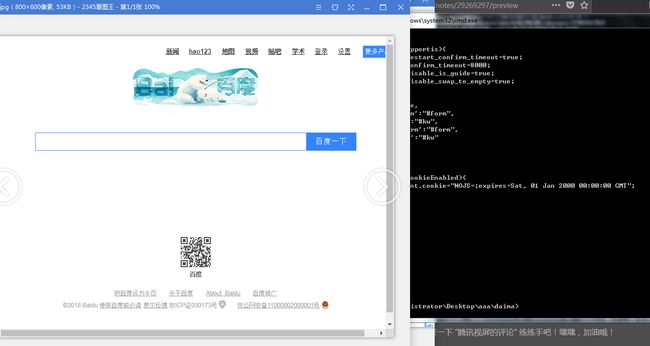
image.png
经过这次实战,我相信同学们对 Selenium 有一定的了解了,接下来不妨去爬取一下 "腾讯视屏的评论" 练练手吧!嘿嘿,加油哦!