HDFS架构图
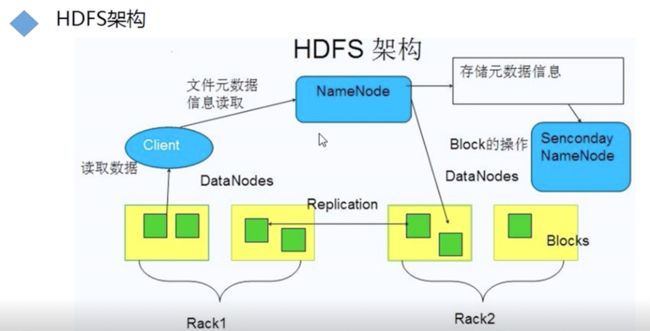
HDFS原理
1) 三大组件
NameNode、 DataNode 、SecondaryNameNode
2)NameNode
存储元数据(文件名、创建时间、大小、权限、文件与block块映射关系)
3)DataNode
存储真实的数据信息
4)SecondaryNameNode
合并edits日志文件和fsimage镜像文件进行合并

详细信息如下:
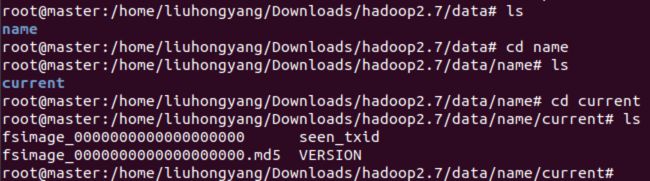
其中fsimage_0000000000000000000000属于镜像文件
see_txid操作事务id
其中fsimage_0000000000000000000000.md5属于校验和
VERSION属于版本号,详细信息如下:

(1)dfs.namenode.name.dir file://{$hadoop.tmp.dir}/dfs/name
hadoop.tmp.dir /tmp/hadoop-${user.name}
多次格式化的问题:
hdfs格式化会改变VERSION文件中的clusterID, 首次格式化时datanode和namenode会产生相同的clusterID;
如果重新执行格式化,namenode的clusterID改变,就会愈datanode的cluseterID不一致,如果重启或者读写hdfs,就会挂掉
(2)dfs.datanode.data.dir file://${hadoop.tmp.dir}/dfs/data
hadoop.tmp.dir /tmp/hadoop-${user.name}
例:/tmp/hadoop-root/dfs目录下:
name、data、namesecondary
(3)dfs.namenode.checkpoint.dir file://{hadoop.tmp.dir}/dfs/namesecondary
tmp/hadoop-${user.name}/dfs/name或者 tmp/hadoop-${user.name}/dfs/data下的datanode和namenode信息在系统
在重启时,会被清空处理。为了防止数据丢失,接下来我们更改路径存储,以namenode为例:
配置hdfs信息如下:将namenode数据存储在data/name下面

在执行格式化之前,查询data下的目录信息:

进行格式化:
hdfs namenode -format -force
格式化之后,在data/name/current下查看name信息