Adversarial Machine Learning 经典算法解读(FGSM, DeepFool)
最近关注Adversarial Machine Learning(AML),觉得这个方向挺有意思,看了几个AML中的经典算法,有点小的理解写下来加深记忆。由于第一次写CSDN博客,有错误的地方欢迎指出,共同讨论,而且比较懒,有些解释的图是画得不好,要耐心看。
在我看来,AML(Adversarial Machine Learning)最终的研究目的和传统的安全领域一样,还是提高整个系统的稳定性。文献【1】中较早的指出Neural Netwroks(NN) 对刻意设计的攻击样本很敏感,并提出了一种攻击方法L-BFGS,并且文章指出针对NN的adversarial sample (AS)之所以存在归因于NN的结构复杂性。不过,我觉得FGSM,DeepFool中的角度可能更make sense。
之所以把这两个方法放在一起分析是因为在我看来它们都是基于同一种假设条件下进行的,即分类器的决策函数都是局部可线性逼近线性的,或者说分类都是很平滑的。也就是说,如果在决策函数的某一个点做taylor展开的话,该点的切平面和与决策函数在该点的某一邻域内是大致相似的,如图1,在二维sigmoid函数在红点处的切平面在该点处的附近与函数本身是很相似的。事实上文献【3】中也指出了现有的Deep Networks 为了训练的方便,都会选择比较线性的激活函数,或者说局部曲率很低的激活函数,如Sigmoid,Rulu等。而FGSM(Fast Gradient Sign Method)和 DeepFool 正是在这样的先验假设下展开的。下面分别分析一下两种方法。
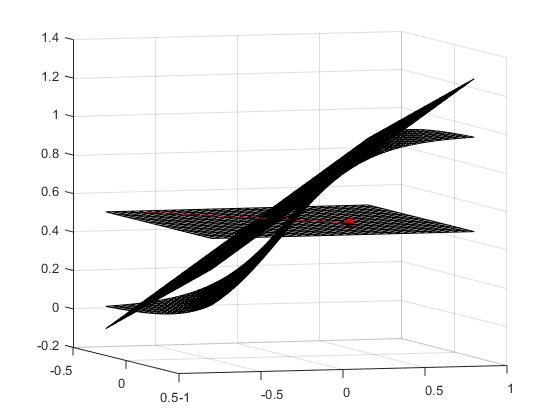
图1
FGSM
在最开始对传统的分类器做攻击时候,大家的motivation都是差不多的。借用文献【2】中提出的Taxonomy概念,攻击场景(Attack Scenario)中的一个重要组成部分就是攻击策略(Attack strategy)。说白了,就是要怎样去model这个攻击场景。由于大多数分类器都是通过最大化分类器在训练集上的预测概率,或者最小化预测值与标签的loss来构建优化模型的目标函数,所以一个自然的想法就是通过对一个clean样本 x(legal sample)加上一个扰动 η 来使得分类器的预测概率发生改变,或者让loss的值尽可能的大,即f(x)≠f(x+r),或 max_{η} loss(x+η),同时扰动本身要限制在一个人眼无法察觉,或者说对legal sample不产生较大破坏。因此通常会对r 施加范数的限制 (不同的范数有不同的效果),即 ||η||<ε. FGSM【3】采用最大化损失函数的方式生产扰动。显然,扰动发生在梯度方向是最有效的,而FGSM中的一个合理的假设在于,现有的图像数据的存储方式都是离散的,因此对于一个在同一方向的ε扰动是不会对视觉产生较大影响的。因此,FGSM通过在legal sample x 的梯度方向平移ε的量级来得到扰动η。于是, 最终的攻击样本(AS) attack_x=x+η,这刚好等价于对扰动施加无穷范数限制,文章中通过线下模型说明了这一点。综上,可以理解FGSM中的如下公式了,

其中,sign(▽J) 刚好描述了x 点处loss函数的梯度方向,ε为在该方向上的偏移量级。直观地,我们从图1可以看出,当x (红点)朝着梯度方向(红线)移动时,此时sigmoid为激活函数的分类器的损失函数会增大,x 会朝相反的预测结果移动。 那么问题来了,FGSM之所以对决策函数做出线性假设或近似线性假设的原因在于必须保证x处的梯度方向始终指向损失函数增大的方向,显然,当激活函数(或决策函数)是线性的时候,梯度是恒定的,因此FGSM总是有效的。不过,这一个假设视乎很合理,因为现在为了网络训练的方便,大家都会选择sigmod, rulu这种线性的或者近似线性的激活函数。值得指出的是,FGSM中最大的问题就是量级ε是人工选择的。所以,当决策函数不是线性的时候,FGSM就不好使了。原因如下图(白板画的,麻烦耐心看):

选择ε1会产生成果的攻击,但是较大ε2则不会。
DeepFool
针对FGSM,DeepFool系统的解决了FGSM中的问题,并且得出了适应性更强的攻击方法。首先,DeepFool【4】解决了FGSM中扰动系数ε的选择问题,并且通过多次线性逼近实现了对一般非线性决策函数的攻击。首先对于扰动系数的选择问题,DeepFool考虑线性决策函数的情形,通过求解如下优化问题得出满足条件的最优扰动r (即FGSM中的η)

上述优化问题是可以得到解析形式的解的,即(3)中的最后一项。实际上,在线性决策函数的情形下,w恰好是决策函数的梯度方向,而前面的标量f(x0)/||w||正好对应了最优的扰动系数ε,由于DeepFool的攻击策略为最大化分类器的置信度,因此,legal sample x0 朝着梯度的反方向偏移,从而最小化分类器置信度。值得注意的是,(3)中的最优解r是满足f(x0+r)=0,因此,最后的adversarial sample为attack_x=x0+r+σ,其中σ是r方向上的微小偏移使得f(x0+r+σ)<0.
上述情形同样是针对线性决策函数的攻击方法,对于非线性函数,DeepPool采用多次线性逼近的形式完成,其具体算法如下

通过下图可以比较好的理解上述算法(画的有点糙,论文(4)中有二维情形的例子,可能没有一维的好理解)针对上述非线性的决策函数,DeepFool通过在每一次迭代,在迭代点处对决策函数做线性逼近,将问题简化为线性决策函数攻击的问题,最后叠加每次攻击的扰动方向r得到最终的结果。值得注意的是,该迭代的收敛性没有在文中证明,但是给出了一个reference可能可以证明DeepFool的收敛性。
对于多分类的情况实际上是类似的,实现针对线性多分类情形,可以通过求解如下优化问题得到最优扰动

这个问题的求解可以对每一个k分别求解(直接转化为等式不等式约束的优化问题,拉格朗日函数求解)得出最优的r_k,然后对所有k找出最小的扰动r_{l{x0}}

如下图,最优的扰动即x0到决策面F3的垂直移动

这样,对于非线性的情形,每一次迭代都采用一个由多个决策面F1,F2,...,Fn组成的凸多面体去逼近(即在该点处对每一个决策函数做一阶taylor展开),即每一次迭代都转化为一个对多个线性决策函数攻击的问题,最后求出最优扰动。
REFERENCE
【1】Szegedy C, Zaremba W, Sutskever I, et al. Intriguing properties of neural networks[J]. arXiv preprint arXiv:1312.6199, 2013.
【2】Huang L, Joseph A D, Nelson B, et al. Adversarial machine learning[C]//Proceedings of the 4th ACM workshop on Security and artificial intelligence. ACM, 2011: 43-58.
【3】Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples[J]. arXiv preprint arXiv:1412.6572, 2014.
【4】Moosavi-Dezfooli S M, Fawzi A, Frossard P. Deepfool: a simple and accurate method to fool deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 2574-2582.