Hive部署安装
Hive部署安装:
前置条件:
Requirements
Java 1.7
Note: Hive versions 1.2 onward require Java 1.7 or newer. Hive versions 0.14 to 1.1 work with Java 1.6 as well. Users are strongly advised to start moving to Java 1.8 (see HIVE-8607).
Hadoop 2.x (preferred), 1.x (not supported by Hive 2.0.0 onward).
Hive versions up to 0.13 also supported Hadoop 0.20.x, 0.23.x.
Hive is commonly used in production Linux and Windows environment. Mac is a commonly used development environment. The instructions in this document are applicable to Linux and Mac. Using it on Windows would require slightly different steps.
这里用的hive版本是:hive-1.1.0-cdh5.7.0
hadoop版本下载:wget http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.7.0.tar.gz
hive版本下载: wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
下载
[hadoop@10-9-15-140 soft]$ wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
--2019-07-24 00:39:48-- http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz
Resolving archive.cloudera.com... 151.101.108.167
Connecting to archive.cloudera.com|151.101.108.167|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 116082695 (111M) [application/x-tar]
Saving to: “hive-1.1.0-cdh5.7.0.tar.gz”
100%[====================================================================================>] 116,082,695 27.4K/s in 90m 47s
2019-07-24 02:10:38 (20.8 KB/s) - “hive-1.1.0-cdh5.7.0.tar.gz” saved [116082695/116082695]
[hadoop@10-9-15-140 soft]$
解压
[hadoop@10-9-15-140 soft]$ tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app
[hadoop@10-9-15-140 hive-1.1.0-cdh5.7.0]$ ll
total 440
drwxr-xr-x 3 hadoop hadoop 4096 Mar 24 2016 bin
drwxr-xr-x 2 hadoop hadoop 4096 Mar 24 2016 conf
drwxr-xr-x 3 hadoop hadoop 4096 Mar 24 2016 data
drwxr-xr-x 6 hadoop hadoop 4096 Mar 24 2016 docs
drwxr-xr-x 4 hadoop hadoop 4096 Mar 24 2016 examples
drwxr-xr-x 7 hadoop hadoop 4096 Mar 24 2016 hcatalog
drwxr-xr-x 4 hadoop hadoop 12288 Mar 24 2016 lib
-rw-r--r-- 1 hadoop hadoop 23169 Mar 24 2016 LICENSE
-rw-r--r-- 1 hadoop hadoop 397 Mar 24 2016 NOTICE
-rw-r--r-- 1 hadoop hadoop 4048 Mar 24 2016 README.txt
-rw-r--r-- 1 hadoop hadoop 376416 Mar 24 2016 RELEASE_NOTES.txt
drwxr-xr-x 3 hadoop hadoop 4096 Mar 24 2016 scripts
[hadoop@10-9-15-140 hive-1.1.0-cdh5.7.0]$
设置环境变量
把bin加入到环境变量里面去,这样可以在任意窗口使用任意命令
vi ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
source ~/.bash_profile
备注:hive的数据data是存放在HDFS上的,那么ruozeinput.txt 就是一个普通的不能再普通的文本文件,它是没有schema信息的。hive的数据是在hdfs上的,但是描述这些数据的元数据信息是存放在mysql(市场上90%以上都是用mysql)里面的,所以安装好hive之后还需要配置元数据信息,告诉hive如何能访问到mysql数据库。
schema信息是 table/database/column(name/type/index)。
元数据信息 metadata:是描述数据的数据。
访问mysql需要哪些条件?URL、用户user、密码password、mysql驱动driver(每个软件都有驱动)。
拷贝mysql的驱动到lib下
[hadoop@10-9-15-140 soft]$ cp mysql-connector-java-5.1.46.jar ~/app/hive-1.1.0-cdh5.7.0/lib/
[hadoop@10-9-15-140 soft]$ pwd
/home/hadoop/soft
[hadoop@10-9-15-140 soft]$
hive-site.xml配置mysql相关信息
/home/hadoop/app/hive-1.1.0-cdh5.7.0/conf/hive-site.xml
[hadoop@10-9-15-140 conf]$ vi hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/ruoze_d7?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.cli.print.current.db
true
打印当前hive库名
hive.cli.print.header
true
打印当前hive表字段名
[hadoop@10-9-15-140 conf]$ hive
which: no hbase in (/home/hadoop/app/hive-1.1.0-cdh5.15.1/bin:/home/hadoop/app/protobuf-2.5.0/bin:/home/hadoop/app/apache-maven-3.3.9/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin:/usr/java/jdk1.7.0_80/bin:/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/hadoop/bin)
Logging initialized using configuration in jar:file:/home/hadoop/app/hive-1.1.0-cdh5.15.1/lib/hive-common-1.1.0-cdh5.15.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> show databases;
OK
default
Time taken: 0.984 seconds, Fetched: 1 row(s)
hive>
用mysqladmin用户进mysql,看一下:出现了ruoze_d6这个数据库
10-9-15-140:mysqladmin:/usr/local/mysql:>mysql -uroot -p123456
Warning: Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1051
Server version: 5.6.23-log MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| db_temp |
| mysql |
| performance_schema |
| ruoze_d6 |
| ruozedata |
| test |
+--------------------+
7 rows in set (0.01 sec)
mysql> use ruoze_d6
Database changed
mysql> show tables
-> ;
+---------------------------+
| Tables_in_ruoze_d6 |
+---------------------------+
| bucketing_cols |
| cds |
| columns_v2 |
hive补充了解:
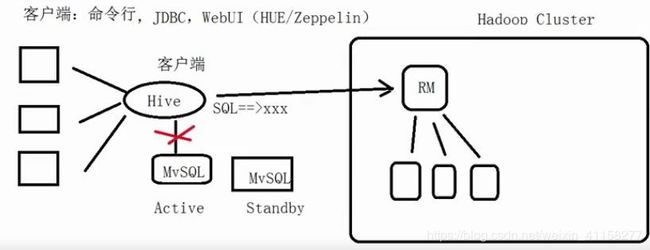
mysql会出现单点故障问题
怎么解决?主备(相当于会同时存在两个mysql,如果有一个出现问题,另一个备用的立马切换过来使用)
hive是一个客户端,不存在集群的概念。虽然它没有集群的概念,但是在生产上面,它也要部署多个。
Hive提供了一种类SQL的语法 Hive QL,它里面的SQL和关系型数据库的SQL是没有关系的,只是语法上很相似而已。
查看表结构
hive> desc hello;
OK
id int
name string
Time taken: 0.27 seconds, Fetched: 2 row(s)
hive>
hive> desc extended hello;
OK
id int
name string
Detailed Table Information Table(tableName:hello, dbName:default, owner:hadoop, createTime:1563977589, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:id, type:int, comment:null), FieldSchema(name:name, type:string, comment:null)], location:hdfs://hadoop001:9000/user/hive/warehouse/hello, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{numFiles=1, COLUMN_STATS_ACCURATE=true, transient_lastDdlTime=1563977684, numRows=0, totalSize=28, rawDataSize=0}, viewOriginalText:null, viewExpandedText:null, tableType:MANAGED_TABLE)
Time taken: 0.234 seconds, Fetched: 4 row(s)
hive>
hive> desc formatted hello;
OK
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
Owner: hadoop
CreateTime: Wed Jul 24 22:13:09 CST 2019
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop001:9000/user/hive/warehouse/hello
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
numFiles 1
numRows 0
rawDataSize 0
totalSize 28
transient_lastDdlTime 1563977684
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.259 seconds, Fetched: 33 row(s)
hive>
Hive vs RDBMS 对比(面试):
SQL:都可以用SQL
事物:RDBMS是事物,hive也可以但是最好不用
insert/update:hive高版本支持,但是性能特别差;RDBMS当然支持。
底层分布式:hive底层的执行引擎(MapReduce)是分布式的,节点可以有很多很多;RDBMS也可以支持,但是对节点是有限制的,多了之后就不行了。
机器:hive、hadoop一般构建在廉价的机器上面,但是RDBMS是部署在专用的机器上面。
数据量:大数据可以到P以及更多,但是RDBMS到G。
速度:hive底层是MapReduce,快不哪里去,它都是跑离线任务的。hive的延时性非常高,关系型数据库延时性非常低。
hive:离线批处理,延时性很高。
大数据不怕数据量大,就怕数据倾斜!!!