倒排索引、正排索引,以及ElasticSearch对倒排索引的优化方法
正排索引与倒排索引
首先,我们需要这两种索引方式是要干啥?其实任何一种索引模式,都对应的是不同的信息存储方式。这样不同的存储方式,主要是为了不同的查询要求而定的。正排索引和倒排索引就是如此,正排易维护,但搜索代价很大(耗时间);倒排搜索快,但建立倒排索引时间久、文档库的每次更新都意味着倒排索引的重建,故维护较麻烦。但由于倒排索引的建立可以放在线下,所以这一般来说不是太大的问题。
正排索引
正排索引就是最普通的索引排序方式。正排索引也是采取key-value pair的方式对数据进行保存,key是doc-id,value则可以存储多种内容,如doc的分词词表、doc所在网页的属性信息等。由此可见,正排索引可以随意添加数据,但如果你要查询某个单词在哪些文档中出现,那么你就不得不将全部文档都遍历一遍,若文档库极大,则时间消耗是不可接受的。
倒排索引
倒排索引是Lucene和ElasticSearch用来做全文检索的标配。倒排索引类似将正排索引反过来,以全部文档中出现的所有words建立一个term dictionary ,然后对于term dictionary 中的每个词,它后面都会跟随一个链表,该链表就是 倒排表 ,倒排表内存储着如下信息:
- 该词出现的doc-id
- 该词在某doc中的出现次数和出现位置
如此一来,倒排索引就可以在用户输入查询query时,将query分词成一个个token,然后将一个个token带到term dictionary 去“查字典”,然后获得出现该词的doc-id集合,最终在这若干个token对应的若干doc-id集合上做交集,得到最符合用户query查询的结果。
由此可见,倒排索引大大加快了查询速度,然而一旦有新的文档加入文档库,你就要重新做一次"入库操作",即建立倒排索引的操作。因为此时各个token在不同文档中的出现次数、以及每个token对应的 倒排表 都可能发生变化。
倒排索引的进阶——倒排索引如何进一步加速?
从上面的介绍可知,倒排索引的建立这么麻烦,其主要目的就是加速。所以除了索引建立策略上,我们在数据结构和查找策略方面也要最大程度节省时间。那么倒排索引还做了哪些速度性能优化呢?
在 term dictionary 基础上再建 term index
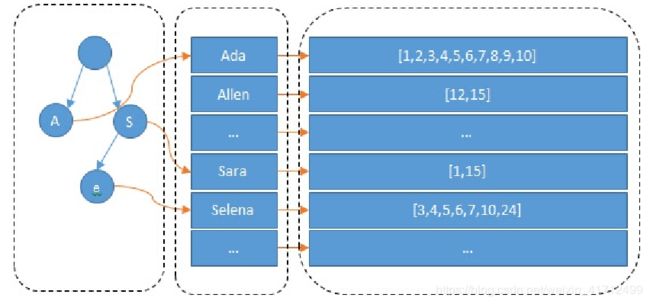
从左到右,分别是term-index、term-dictionary、posting list(倒排表)
我们可以将整个ElasticSearch的查找过程当做“查字典”过程。对于大型ES库而言,当你的文档数目很多的时候,你的目录必然也会很长(毕竟字典里的term变多了嘛)。所以,此时你就只能将term dictionary 放在磁盘上。即便我们对term dictionary 中term的顺序进行有规则排序,从而在查询时可以执行 二分查找,我们也还是会在搜索时多次访问磁盘,从而因磁盘IO限制降低了查询速度。
为了解决这个问题,ES/Lucene引入了 term index,其本质就是个字典树。至于字典树是个啥(https://zh.wikipedia.org/wiki/Trie)。字典树记录了term的前缀信息,例如以下words组成的字典:
sand, sad, say, said, seed, search, sorry, sore, shabby, sherry, , score, scholar…
我们可以建立字典树,分别记录由前缀 sa、 se 、so、 sh、sc 组成的词在 term dictionary 中开始的位置,从而一下子大幅降低我们查词典时的搜索空间、减少访问磁盘的次数(其实新华字典不也是这么干的么~)。与此同时,我们还可以将字典树term index 存在内存上。所以说,ElasticSearch的优化,有时候就是字典树term index 占内存大小和搜索速度这两方面的权衡——字典树越大,你可以定位到的前缀信息越多(比如从只定位 sa -> sad 、san 、 sai…),你在磁盘的term dictionary中做二分查找的次数肯定也会更少,速度就越快;但内存空间是有限的,你不可能无限扩张你的字典树。
倒排表求交集的加速
设想一个用户输入这样一个query:Boston Celtics Calendar ,即波士顿凯尔特人队赛程表。我们将query分成三个term -> Boston , Celtics , Calendar . 我们对这三个词到倒排索引中进行查询,最终得到三个倒排表。假设倒排表是这样的(极简版,实际上倒排表内容会更多)
Boston -> [12, 13, 24, 28, 40, 42, 46, 51, 56, 59]
Celtics -> [2, 12, 13, 40, 43, 44, 46, 58, 59]
Calendar -> [0, 1, 12, 15, 20, 40, 46, 51, 55, 59, 60, 62, 65]以上交集结果:[12, 40, 46, 59]
首先,对于此类有序数组,做交集有个很强大的数据结构——跳表(skip list)。这个数据结构很简单也很精巧,在这儿不再详述。
其次,假设全部文档真的都是这种integer格式的id,那么对内存的考验极大。一个int类型至少需要2 byte,50M个doc-id就是100M的内存占用,所以说显然在doc数量较大的情况下integer类型的doc-id有其局限性。
那么如果不用 integer+跳表 的方式来做交集,还可以用啥方法呢?使用Bitmap的方法:
对于一个doc-id list [1,2,5,7],我们可以转为[1, 1, 0, 0, 1, 0, 1, 0],另一个list[1,2,8] -> [1, 1, 0, 0, 0, 0, 0, 1],显而易见,这其实就是做了个类似“one-hot”的操作,将doc-id对应的位置置为0,若存在于倒排表里,就设为1。这样做更节省内存占用,因为每个doc-id是非0即1的,只占1 bit,即1/8 byte. 50M的doc-id,这样只需要 50M*1/8 byte = 6.25M的内存占用,是不是节省了一大笔开销?而且位运算速度可是计算机做的最快的运算方式!
但有个小问题——bitmap方法对应的每个倒排表实际上内存占用都是一致的,都是长度为全部doc-id这么长的list。在面对doc-id数量较少的求交集运算时,这样做就显得有点冗余。举个例子,假设Boston, Celtics , Calendar 分别对应doc-id的集合为[1,2]、[1,3]、[1,4],但doc-id一共有50M篇,那么虽然参与交集运算的每个list最多只有2 * 2 byte = 4 byte,但我还是得对每个倒排表开6.25M的内存空间,这是不是有点杀鸡用牛刀呢?所以,依据doc-id总量的不同,到底是 integer+跳表 还是 bitmap 也是可权衡的。
这就是ElasticSearch/Lucene在交集运算时的优化。