深度学习 --- 受限玻尔兹曼机RBM(直接采样、接受-拒绝采样、重要性采样详解)
在讲解MCMC和Gibbs采样之前,大家需要理解统计学中的采样,什么是采样?为什么要采样?采样有什么用?大家需要深入理解采样的原理,深入理解的好处不仅容易理解下面的MCMC和Gibbs采样,也更容易掌握统计学中的一种重要的统计手段,这个技术在现代统计学中很重要,因此掌握它以后在遇到采样也不用怕了,因为一旦深入理解了,无非是更好的采样方法吧了,其本质不会变,我在刚学的时候,就被这些搞得云里雾里,这次总结总算搞清楚了,因此写下了,废话不多说,下面开始:
在实际生活中,大量问题包含随机性因素。有些问题很难用数学模型来表示,也有些问题虽建立了数学模型,但其中的随机性因素较难处理,很难得到解析解,这时使用计算机进行随机模拟是一种比较有效的方法。
随机模拟方法是一种应用随机数来进行模拟实验的方法,也称为蒙特卡罗法。这种方法名称来源于世界著名的赌城——摩纳哥的蒙特卡罗,通过对研究问题或系统进行随机抽样,然后对样本值进行统计分析,进而得到所研究问题或系统的某些具体参数、统计量等。
蒙特卡洛基本思想:
1.求面积
假设我们要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如,积分)的复杂程度是成正比的。蒙特卡罗方法基于这样的思想:假想你有一袋豆子,把豆子均匀地朝这个图形上撒,然后数这个图形之中有多少颗豆子,这个豆子的数目就是图形的面积。当你的豆子越小,撒的越多的时候,结果就越精确。借助计算机程序可以生成大量均匀分布坐标点,然后统计出图形内的点数,通过它们占总点数的比例和坐标点生成范围的面积就可以求出图形面积。如下图:
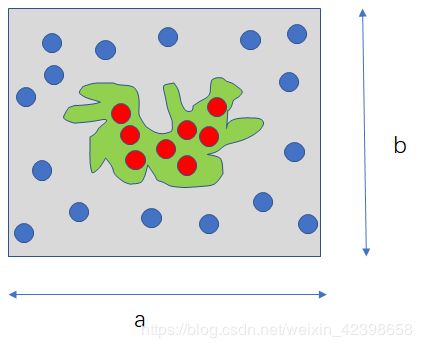
现在要求浅绿色的面积,我们看到这是个很不规则的图形,无法得到一个闭合的数学表达式或者即使得到数学表达式也很复杂无法求面积,此时就可以使用蒙特卡洛方法进行求解,我使用一个规则的图形包围他,然后向这个规则的图形中随机的撒芝麻(黄豆一样),那么我先数总共的芝麻数为N,那么落在不规则的图形中的芝麻(上图红色点)为n,此时即使规则图形的面积为:![]() ,此时的不规则的图形的面积就为:
,此时的不规则的图形的面积就为:![]() ,很简单吧。
,很简单吧。
2.求积分
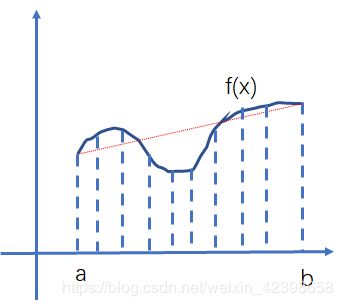
有函数f(x),它在区间[a, b]的积分就是x=a, x=b以及f(x)和x轴围成区域的面积,我们将[a, b]划分n份,那么积分可以写成:
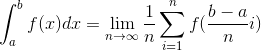
如果n取一个具体的值,那么等式右边的意思就是这n个值对应的函数的和然后求均值就是面积 ,所以,对于f(x)在[a, b]的积分,我们可以通过求f(x)的均值来模拟。
3.求
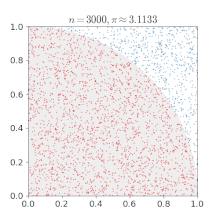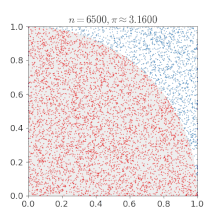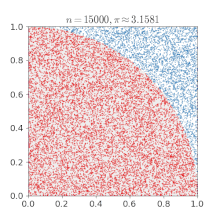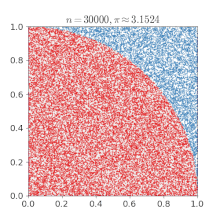
使用蒙特卡罗方法估算π值. 放置30000个随机点后,π的估算值与真实值相差0.07%.这个就不给公式了,也是通过面积进行求解的
直接采样
直接采样其实很简单,但是需要你理解以后才觉得简单,不理解感觉还是挺难的,直接采样的思想是,通过对均匀分布采样,实现对任意分布的采样。首先大家需要理解什么是概率密度,什么是累积函数 ,不理解的请自寻查阅。还有就是我们通常说的均匀分布、高斯分布、指数分等都是概率密度。如果概率密度为 ,那么对应的累积函数就是
,那么对应的累积函数就是![]() ,而累积函数的的取值范围为【0,1】,简单来说累积函数就是概率的累加,如下
,而累积函数的的取值范围为【0,1】,简单来说累积函数就是概率的累加,如下
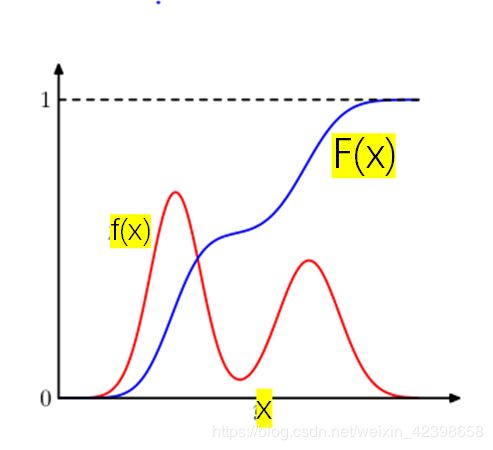
从上图我们可以看到,F(x) 是递增的,且取值范围是[0,1],因此我们可不可以利用这个特性进行设计符合概率密度的采样函数呢?所谓采样就是说我通过某个分布去生成对应该分布的样本。那么我们通过累积函数如何采样才能得到对应该密度函数分布样本呢?我们可以这样,首先我们先通过均匀分布生成随机数,![]() ,此时我们令
,此时我们令![]() ,从这个表达式我们可以看出均匀分布生成的样本z一定在[0,1]区间,那么求出反函数:
,从这个表达式我们可以看出均匀分布生成的样本z一定在[0,1]区间,那么求出反函数:![]() ,此时得到的x就是服从分布的抽样,这里大家需要思考一下,我们知道F(x)是通过密度函数的积分得到的,而密度函数对应的x其实就是样本了,因此求反函数就是求出对应的样本。下面给出算法流程:
,此时得到的x就是服从分布的抽样,这里大家需要思考一下,我们知道F(x)是通过密度函数的积分得到的,而密度函数对应的x其实就是样本了,因此求反函数就是求出对应的样本。下面给出算法流程:
- 从
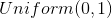 随机产生样本z
随机产生样本z - 令
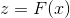 ,其中 F(x) 是待求样本的分布函数 的累积函数
,其中 F(x) 是待求样本的分布函数 的累积函数 - 计算 的反函数
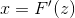
- 结果x即为对应的采样
以上就是直接采样了,这里可能需要大家好好理解一些,为什么需要随机的均匀分布z,其实就为了均匀的在【0.1】采样 ,只有这样采样出来的数据才符合对应的概率密度函数,这里大家需要好好体会一下,然而上面虽然可以实现生成对应分布的样本,但是前提我们需要知道累积函数,有时候这个累积函数并没有那么容易求出来,即使求出来我们可能也求不出他的逆函数,因此就需要引入更强大的采样机制了即接受-拒绝采样。
接受-拒绝采样
假设我们希望从概率分布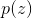 中采样,这个概率分布不是我们目前为止讨论过的简单的标准的概率分布中的一个,从而直接从中采样是很困难的。此外,正如经常出现的情形那样,我们假设我们能够很容易地计算对于任意给定的z值的(不考虑归一化常数Z),即
中采样,这个概率分布不是我们目前为止讨论过的简单的标准的概率分布中的一个,从而直接从中采样是很困难的。此外,正如经常出现的情形那样,我们假设我们能够很容易地计算对于任意给定的z值的(不考虑归一化常数Z),即

其中![]() 可以很容易地计算,但是
可以很容易地计算,但是![]() 未知 .
未知 .
为了应用接受-拒绝采样方法,我们需要一些简单的概率分布![]() ,有时被称为提议分布(proposaldistribution),并且我们已经可以从提议分布中进行采样。接下来,我们引入一个常数k,它的值的选择满足下面的性质.对所有的z值,都有
,有时被称为提议分布(proposaldistribution),并且我们已经可以从提议分布中进行采样。接下来,我们引入一个常数k,它的值的选择满足下面的性质.对所有的z值,都有![]() 。函数
。函数![]() 被称为比较函数,并且下图给出了单变量概率分布的说明。拒绝采样器的每个步骤涉及到生成两个随机数。首先,我们从概率分布
被称为比较函数,并且下图给出了单变量概率分布的说明。拒绝采样器的每个步骤涉及到生成两个随机数。首先,我们从概率分布![]() 中生成一个数
中生成一个数 。接下来,我们在区间
。接下来,我们在区间![]() 上的均匀分布中生成一个数
上的均匀分布中生成一个数![]() 。这对随机数在函数
。这对随机数在函数![]() 的曲线下方是均匀分布。最后,如果
的曲线下方是均匀分布。最后,如果![]() ,那么样本被拒绝,否则被保留。因此,如果它位于下图的灰色阴影部分,它就会被拒绝。这样,剩余的点对在曲线
,那么样本被拒绝,否则被保留。因此,如果它位于下图的灰色阴影部分,它就会被拒绝。这样,剩余的点对在曲线![]() 下方是均匀分布的,因此对应的
下方是均匀分布的,因此对应的 值服从概率分布,正如我们所需的那样。
值服从概率分布,正如我们所需的那样。
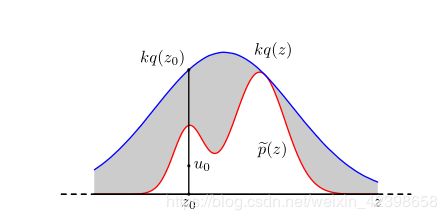
上图在拒绝采样的⽅法中,样本从⼀个简单的概率分布 ![]() 中抽取。如果样本落到了未归⼀化的概率分布
中抽取。如果样本落到了未归⼀化的概率分布![]() 与放缩的概率布
与放缩的概率布 ![]() 之间的灰⾊区域,那么样本会被拒绝。得到的样本服从 的分布,它是
之间的灰⾊区域,那么样本会被拒绝。得到的样本服从 的分布,它是 ![]() 的归⼀化版本。
的归⼀化版本。
的原始值从概率分布![]() 中生成,这些样本之后被接受的概率为
中生成,这些样本之后被接受的概率为![]() ,其实就是无阴影的黑色长度比上整个黑色的长度的值,因此一个样本会被接受的概率为:
,其实就是无阴影的黑色长度比上整个黑色的长度的值,因此一个样本会被接受的概率为:
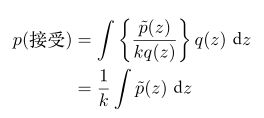
因此,被这种⽅法拒绝的点的⽐例依赖于曲线 kq(z) 下⽅的未归⼀化概率分布 ![]() 的⾯积的⽐例。于是,我们看到,常数 k 应该尽量⼩,同时满⾜下⾯的限制条件:
的⾯积的⽐例。于是,我们看到,常数 k 应该尽量⼩,同时满⾜下⾯的限制条件: ![]() ⼀定处处不⼩于
⼀定处处不⼩于![]() 。
。
好,我在这里在详细的解释一下,首先![]() 是很复杂的概率密度函数,不容易抽样,也不容易归一化,那么针对这样的复杂分布函数我该如何抽样呢?首先我们先引入一个常见的分布函数如高斯分布
是很复杂的概率密度函数,不容易抽样,也不容易归一化,那么针对这样的复杂分布函数我该如何抽样呢?首先我们先引入一个常见的分布函数如高斯分布![]() ,这个时候我们的找出的简单分布需要完全覆盖复杂的分布即
,这个时候我们的找出的简单分布需要完全覆盖复杂的分布即![]() ,因此需要乘上k(k值应该取多少才能保证呢?后面会说),使其
,因此需要乘上k(k值应该取多少才能保证呢?后面会说),使其![]() 恒成立。到这里我们就可以通过简单的
恒成立。到这里我们就可以通过简单的![]() 生成一个样本(通常常见的分布的样本比较容易得到),此时对应的简单的概率为
生成一个样本(通常常见的分布的样本比较容易得到),此时对应的简单的概率为![]() ,那么我们在区间
,那么我们在区间![]() (这个就是上图的纵坐标的范围)按照均匀分布生成一个数
(这个就是上图的纵坐标的范围)按照均匀分布生成一个数![]() ,这个不难吧,就是说对应上图的黑线生成一个均匀随机数
,这个不难吧,就是说对应上图的黑线生成一个均匀随机数![]() ,这个时候我们把
,这个时候我们把![]() 也计算出来,然后和
也计算出来,然后和![]() 比较,如果生成的
比较,如果生成的![]() 大于
大于![]() ,我们就拒绝这个样本,反之
,我们就拒绝这个样本,反之![]() 小于
小于![]() 我们就接受这个样本,因为生成的样本是随机的,而接不接受是通过
我们就接受这个样本,因为生成的样本是随机的,而接不接受是通过![]() 进行决定的,因此接受的样本是符合概率分布的,这就是抽样的方法,大家需要深入理解它,这个思想很重要。下面给出算法流程:
进行决定的,因此接受的样本是符合概率分布的,这就是抽样的方法,大家需要深入理解它,这个思想很重要。下面给出算法流程:
- 寻找一个合适的简单分布
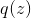
- 确定k值
- 产生样本
 和
和![u_0\sim Uniform[0,1]](http://img.e-com-net.com/image/info8/05b0d2a62d9c4182a2f2f12b114266ab.gif)
- 如果
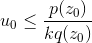 ,则接受
,则接受 - 重复2、3、4过程,直到满足生产样本个数要求
上面接受的样本就是服从分布,到这里大家应该都理解了吧,最重要的一点是接受的样本之所以服从样本,是因为他是根据![]() 进行判断的,或者说根据
进行判断的,或者说根据![]() 进行判断的,即满足的样本都留下,反之舍弃。因此留下的都是符合这个分布要求的,这里需要大家深入理解,
进行判断的,即满足的样本都留下,反之舍弃。因此留下的都是符合这个分布要求的,这里需要大家深入理解,![]() 的选取规则一般尽量外形相近即可,那么如何确定k呢?很简单因为
的选取规则一般尽量外形相近即可,那么如何确定k呢?很简单因为![]() ,所以
,所以![]() ,只需要求出
,只需要求出![]() 的最大值就可以了。其实还有一个可调节的拒绝采样,这里就不介绍了,比这个还要简单,而且效果更好,有兴趣的建议参考PRML这本书。我们下面继续引入另外一个采样即重要性采样
的最大值就可以了。其实还有一个可调节的拒绝采样,这里就不介绍了,比这个还要简单,而且效果更好,有兴趣的建议参考PRML这本书。我们下面继续引入另外一个采样即重要性采样
重要性采样
这个采样算法和前面不一样的,只是目的不一样但是思想和接受-拒绝采样有异曲同工之处,大家好好体会,废话不多说,下面开始:
讲解重要采样之前呢,需要大家知道概率论中的期望是怎么求的,这个定义需要大家知道,这里我简单的叙述一下:
设连续型随机变量 的概率密度为,若积分:
的概率密度为,若积分:
![]()
绝对收敛,则称上面的积分的值为随机变量的数学期望,记为![]() 即:
即:
![]()
可能会有人疑问了,为什么要说这呀,因为重要性采样他就是根据求期望过来的,他本身并不提供采样的样本,而是直接给出近似期望的框架,我们详细来看看;
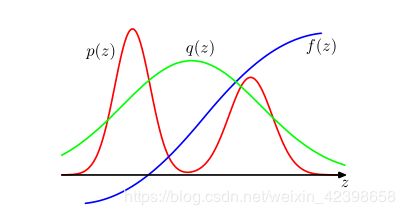
我们知道要想计算符合某个概率分布的期望,首先需要知道概率密度,还要知道样本数据,只有这样按照公式才能计算,现在我们只有概率密度函数,而没有符合的样本数据,上式的代表样本,这时候怎么办呢?我们和接受-拒绝一样引入一个简单的分布![]() ,只是这里我们不在判断是否接受了,而是直接全部接受,但是一旦全部接受样本,所得样本就不会服从,这时候怎么办呢?大家还记得拒绝-接受中的服从的本质原因吗?他是根据满足的样本都留下,不满足的直接舍弃即
,只是这里我们不在判断是否接受了,而是直接全部接受,但是一旦全部接受样本,所得样本就不会服从,这时候怎么办呢?大家还记得拒绝-接受中的服从的本质原因吗?他是根据满足的样本都留下,不满足的直接舍弃即![]() ,我们看上式会发现
,我们看上式会发现![]() 和
和![]() 很像,不同的是这里接受全部样本即上式后面乘的
很像,不同的是这里接受全部样本即上式后面乘的![]() ,只是每个
,只是每个![]() 前面都有一个系数,这个系数就是
前面都有一个系数,这个系数就是![]() ,这个系数有个特点,根据接受-拒绝采样我们知道,当这个值越接近1时说明和
,这个系数有个特点,根据接受-拒绝采样我们知道,当这个值越接近1时说明和![]() 重合,如下图的紫线
重合,如下图的紫线
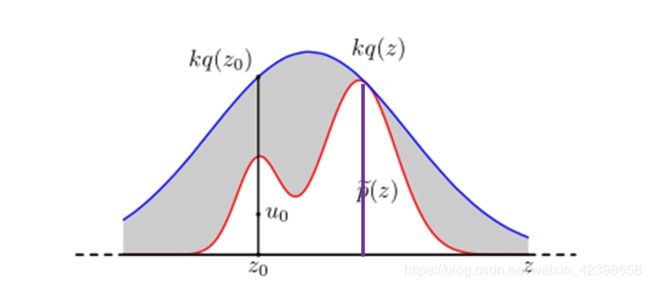
也就是说他们的这个比值是符合 分布的,这里![]() 称为重要性权重,因为有了这个,原本采样全部保留的
称为重要性权重,因为有了这个,原本采样全部保留的![]() ,乘上这个权重以后就符合分布了,然后在和密度函数相乘就是均值了,其实想想这个和接受拒绝差不多,只是不同的是应用不同,一个是求出样本,一个是直接求均值。
,乘上这个权重以后就符合分布了,然后在和密度函数相乘就是均值了,其实想想这个和接受拒绝差不多,只是不同的是应用不同,一个是求出样本,一个是直接求均值。
下面我们系统的梳理一下:
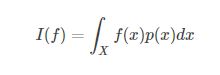
加入重要采样:
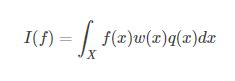

最后的不想码公式了,知道原理后,再看其他人的公式就很简单了,这里大家需要好好理解他们的原理,这次是重点,但是重要采样虽然可以解决某些问题,但是高维的数据就很难处理的,于是机会引入更强大的MCMC算法和Gibbs采样,这在下节我们详细讲,一定会让大家理解这两个牛叉的算法的,但是前提你应该深入理解了这里的接受-拒绝采样和重要性采样的精髓,否则后面就不好理解了。
这里大家好好理解,有什么疑问请留言,本节结束。