Python sklearn 中的TfidfVectorizer参数解析
Python中的TfidfVectorizer参数解析
- 源码阅读 阅读源码真香的呢,感觉虽然目前还不是很懂,但是很清晰
- 知乎大牛文章
- 函数原型
- 函数参数 smooth_idf
- 函数属性 df_
- 函数方法 fit fit_transform inverse_transform(
- use_idf 不加的话等同于CountVectorizer
- norm 归一化处理,每一维度除以向量的模
- 关于参数:
- 参考链接
t f ∗ ( 1 + l o g ( 文 档 总 数 / 出 现 单 词 的 文 档 个 数 ) ) tf*(1+log(文档总数/出现单词的文档个数)) tf∗(1+log(文档总数/出现单词的文档个数))
源码阅读 阅读源码真香的呢,感觉虽然目前还不是很懂,但是很清晰
Sklearn中的Tf-idf原理(source code):
https://github.com/scikit-learn/scikit-learn/blob/f0ab589f1541b1ca4570177d93fd7979613497e3/sklearn/feature_extraction/text.py

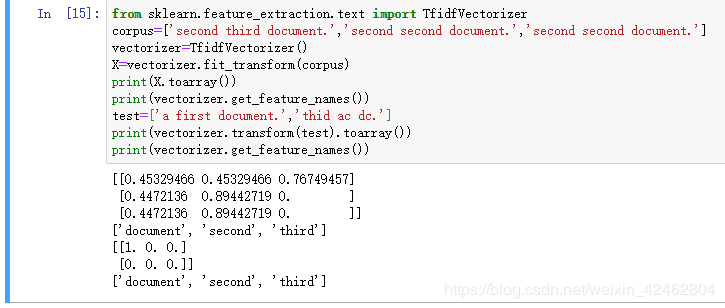
from sklearn.feature_extraction.text import TfidfVectorizer #原始文本转化为tf-idf的特征矩阵
corpus=['second third document.','second second document.'] #语料库 ,每一行一个文档
vectorizer=TfidfVectorizer() #定义了一个类的实例
X=vectorizer.fit_transform(corpus)
print(X.toarray())
print(vectorizer.get_feature_names())
test=['a first second document.','thid ac dc.']
print(vectorizer.transform(test).toarray())
print(vectorizer.inverse_transform(vectorizer.transform(test)))
# Fit步骤学习idf vector,一个全局的词权重_idf_diag。输入的X是一个稀疏矩阵,行是样本数,列是特征数。
# X : array, [n_samples, n_features] Document-term matrix.
#Transform步骤是把X这个计数矩阵转换成tf-idf表示, X = X * self._idf_diag,然后进行归一化
# TfidfVectorizer从训练数据集中学习到词典vocab=['document', 'second', 'third']包含三个词,
# 并且学习到_idf的全局idf vector
#来了新的测试样本,会生成document-term矩阵,矩阵中的数是该文档中该词出现的次数,即tf;然后tf*idf(从idf vector中查找),
# 最后归一化。因此第二个测试样本都为0
知乎大牛文章
今天开始整理了以前做的“的”、“地”、“得”误用识别,发现还是有可改进的地方。也意识到完全基于规则词表的方法,实际上完全可以达到96%的准确性,但是另外的4%需要或许就需要借助于统计方法来做了。至此,是否可以说涉及到语言学相关的应用时,统计和规则是互为补充的,各有优势。看来不管从事什么行业,你做过的业务,几年后回想起来,还是会有很多遗憾。比如当年“的”、“地”、“得”这个实践中,单纯为了准确性所采用的规则,现在看起来,对于不能匹配规则词表的情况,以及在统计生成规则时有冲突的情况,是否可以考虑使用词语词性特征+分类算法来加以解决。这个小实践打算在介绍了基本sklearn库之后在专栏中详细地介绍一下,当然使用的语料肯定只能是能收集到的,当年的语料没有留下来,即使留下来公开出来也是不太好的。之所以要写一下这个小实践的原因是,它有一点统计语言学的味道,并且在现在我的改进思路里有了一些应用机器学习方法的念头,所以我正在整理。其他的实践都比较大,有些甚至没有办法用个人的计算机实现。说到这儿,真是忍不住要说一下现在的自己的工作,之所以开了这个专栏有一个原因是工作时间实在没有什么能做的,没有可用的开发机,每天只能看运维的脸色,借用人家的终端登录服务器看数据,人家只要一用机器,就只能一边站了,哎,作为一个NLP算法工程师,像我这样的境遇估计也是没谁了,所以才会在开专栏前写了一篇文章名称是“不得意就开始写文章”,呵呵。问题不是没有反映,是反映了也没人解决,所以最近还是准备换个地方了,在这里提醒小伙伴们,入职事业单位可要小心呀。
好了,进入今天的主题。今天我们介绍另外一种词袋模型的sklearn实现,今天介绍的词袋模型特征还是由词组成,但是每篇文本的各维度向量值跟昨天介绍的baiziyu:sklearn——CountVectorizer 不一样,在CountVectorizer中,每个文本的各维度值是特征词在文本中的出现次数,今天介绍的TfidfVectorizer,每个文本的各维度值是特征词的Tfidf值。区别很明显,除了考虑特征词在文本中的出现次数外,还考虑了词语在文档集中的分布情况(也就是idf值)。TfidfVectorizer我们已经在baiziyu:文本分类示例1——英文新闻文本分类 这篇文章中应用过了,大家可以查看示例代码。从上边的介绍不难看出,TfidfVectorizer和CountVectorizer的区别不是很大,两个类的参数、属性以及方法都是差不多的,因此我们只介绍TfidfVectorizer中独有的特性,其他的请参考昨天的文章baiziyu:sklearn——CountVectorizer 。
函数原型
class sklearn.feature_extraction.text.TfidfVectorizer(input=’content’, encoding=’utf-8’, decode_error=’strict’, strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer=’word’, stop_words=None, token_pattern=’(?u)\b\w\w+\b’, ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=
函数参数 smooth_idf
binary:布尔值,默认为False。如果为True,则所有非0词特征都被置为1。这不意味着输出只有0,1两种值,只有tf_idf中的tf是二值的
norm:规范化数据的范数,’l1’,’l2’或None
use_idf:布尔值,默认为True。使用逆文档频率重新加权
smooth_idf:布尔值,默认为True。通过对文档频率加1来平滑idf权值,好像有一篇包含有训练集中所有词种各1次的文档被加到了训练集中
sublinear_tf:布尔值,默认为False。应用sublinear tf值尺度变化,例如用1+log(tf)取代tf
函数属性 df_
df_:数组,长度为特征数量
函数方法 fit fit_transform inverse_transform(
fit(raw_documents[,y]):从训练集学习词汇表和idf
fit_transform(raw_documents[,y]):学习词汇表和idf,返回文档词矩
inverse_transform(X):返回某篇训练文档向量中的非0特征值所对应的特征词列表
这里着重说明一下以下几个参数
use_idf 不加的话等同于CountVectorizer
该参数默认值为True。如果我们将它设置为False,类实例就变为CountVectorizer实例。还需要注意sklearn中idf的计算公式与一般书中介绍的不一样。它的计算公式为idf(t)=log(训练集文本总数/包含词t的文本数)+1。例如:
文本集
texts = ["Chinese Beijing Chinese",
"Chinese Chinese Shanghai",
"Chinese Macao",
"Tokyo Japan Chinese"]
特征向量
['beijing', 'chinese', 'japan', 'macao', 'shanghai', 'tokyo']
TF文档-词矩阵
[[1., 2., 0., 0., 0., 0.],
[0., 2., 0., 0., 1., 0.],
[0., 1., 0., 1., 0., 0.],
[0., 1., 1., 0., 0., 1.]]
TF-IDF文档-词矩阵
[[2.38629436, 2. , 0. , 0. , 0. ,0. ],
[0. , 2. , 0. , 0. , 2.38629436,0. ],
[0. , 1. , 0. , 2.38629436, 0. ,0. ],
[0. , 1. , 2.38629436, 0. , 0. ,2.38629436]]
第1篇文本中各维度值的计算如下:
第1维: tf*(1+log(文档总数/出现单词的文档个数))
In [18]: 1.0*(1+log(4/1))
Out[18]: 2.386294361119891
第2维:
In [19]: 2.0*(1+log(4/4))
Out[19]: 2.0
其他维只能是0
norm 归一化处理,每一维度除以向量的模
norm='l2’范数时,就是对文本向量进行归一化。也就是对文档-词矩阵的每行进行归一化处理。归一化公式已经在前边的文章中介绍了baiziyu:数据归一化 。这里我们再用文字叙述一下,过程是:对文档-词矩阵的每行进行归一化,这里用1行举例,如果该行文本的向量为[1.0,2.0,0,0,0,0]则归一化就是将对该向量进行单位化,即对每一维度除以向量的模。
In [3]: text1 = np.array([1.0, 2.0, 0,0,0,0])
In [8]: (1.0/np.sqrt(math.pow(1.0,2)+math.pow(2.0,2)))*text1
Out[8]:
array([0.4472136 , 0.89442719, 0. , 0. , 0. ,
0. ])
smooth_idf
它计算idf值的公式为idf(t)=log( (1+训练集文本总数) / (1+包含词t的文本数) )+1
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = CountVectorizer() #构建一个计算词频(TF)的玩意儿,当然这里面不足是可以做这些
transformer = TfidfTransformer() #构建一个计算TF-IDF的玩意儿
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
vectorizer.fit_transform(corpus)将文本corpus输入,得到词频矩阵
#将这个矩阵作为输入,用transformer.fit_transform(词频矩阵)得到TF-IDF权重矩阵
TfidfTransformer + CountVectorizer = TfidfVectorizer

值得注意的是,CountVectorizer()和TfidfVectorizer()里面都有一个成员叫做vocabulary_(后面带一个下划线)
这个成员的意义是词典索引,对应的是TF-IDF权重矩阵的列,只不过一个是私有成员,一个是外部输入,原则上应该保持一致。
vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf = True, max_df = 0.5)
关于参数:
input:string{‘filename’, ‘file’, ‘content’}
如果是'filename',序列作为参数传递给拟合器,预计为文件名列表,这需要读取原始内容进行分析
如果是'file',序列项目必须有一个”read“的方法(类似文件的对象),被调用作为获取内存中的字节数
否则,输入预计为序列串,或字节数据项都预计可直接进行分析。
encoding:string, ‘utf-8’by default
如果给出要解析的字节或文件,此编码将用于解码
decode_error: {‘strict’, ‘ignore’, ‘replace’}
如果一个给出的字节序列包含的字符不是给定的编码,指示应该如何去做。默认情况下,它是'strict',这意味着的UnicodeDecodeError将提高,其他值是'ignore'和'replace'
strip_accents: {‘ascii’, ‘unicode’, None}
在预处理步骤中去除编码规则(accents),”ASCII码“是一种快速的方法,仅适用于有一个直接的ASCII字符映射,"unicode"是一个稍慢一些的方法,None(默认)什么都不做
analyzer:string,{‘word’, ‘char’} or callable
定义特征为词(word)或n-gram字符,如果传递给它的调用被用于抽取未处理输入源文件的特征序列
preprocessor:callable or None(default)
当保留令牌和”n-gram“生成步骤时,覆盖预处理(字符串变换)的阶段
tokenizer:callable or None(default)
当保留预处理和n-gram生成步骤时,覆盖字符串令牌步骤
ngram_range: tuple(min_n, max_n)
要提取的n-gram的n-values的下限和上限范围,在min_n <= n <= max_n区间的n的全部值
stop_words:string {‘english’}, list, or None(default)
如果未english,用于英语内建的停用词列表
如果未list,该列表被假定为包含停用词,列表中的所有词都将从令牌中删除
如果None,不使用停用词。max_df可以被设置为范围[0.7, 1.0)的值,基于内部预料词频来自动检测和过滤停用词
lowercase:boolean, default True
在令牌标记前转换所有的字符为小写
token_pattern:string
正则表达式显示了”token“的构成,仅当analyzer == ‘word’时才被使用。两个或多个字母数字字符的正则表达式(标点符号完全被忽略,始终被视为一个标记分隔符)。
max_df: float in range [0.0, 1.0] or int, optional, 1.0 by default
当构建词汇表时,严格忽略高于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
min_df:float in range [0.0, 1.0] or int, optional, 1.0 by default
当构建词汇表时,严格忽略低于给出阈值的文档频率的词条,语料指定的停用词。如果是浮点值,该参数代表文档的比例,整型绝对计数值,如果词汇表不为None,此参数被忽略。
max_features: optional, None by default
如果不为None,构建一个词汇表,仅考虑max_features--按语料词频排序,如果词汇表不为None,这个参数被忽略
vocabulary:Mapping or iterable, optional
也是一个映射(Map)(例如,字典),其中键是词条而值是在特征矩阵中索引,或词条中的迭代器。如果没有给出,词汇表被确定来自输入文件。在映射中索引不能有重复,并且不能在0到最大索引值之间有间断。
binary:boolean, False by default
如果未True,所有非零计数被设置为1,这对于离散概率模型是有用的,建立二元事件模型,而不是整型计数
dtype:type, optional
通过fit_transform()或transform()返回矩阵的类型
norm:‘l1’, ‘l2’, or None,optional
范数用于标准化词条向量。None为不归一化
use_idf:boolean, optional
启动inverse-document-frequency重新计算权重
smooth_idf:boolean,optional
通过加1到文档频率平滑idf权重,为防止除零,加入一个额外的文档
sublinear_tf:boolean, optional
应用线性缩放TF,例如,使用1+log(tf)覆盖tf

参考链接
【1】https://zhuanlan.zhihu.com/p/59473719
【2】https://blog.csdn.net/u010981582/article/details/82014965