关于golang的channel
go语言中的goroutine通道通信依靠的是channle
下面我们来认识一下channle的语法
func chanDemo(){
var c chan int //定义变量c为chan类型 并且chan接收数据类型是int
c = make(chan int) //初始化变量c 只有初始化后才可以使用
go func(){ //一般来讲channel与goroutine配合使用 channel在没有缓存的情况下数据传入大于1就会panic
for {
n := <- c //将c变量中的数据传入到n 注意箭头方向
fmt.Println(n) //每次接收到数据就打印 否则就阻塞
}
}()
c <- 1 //将数据1传入到c
c <- 2 //将数据2传入到c
time.Sleep(time.Millisecond) //延迟函数结束一毫秒
}在go语言中 channel同样可以作为类型作为返回值
同样可以创建数组 如 var channels[10] chan int
func worker(id int,c chan int){ //chan做类型
for {
fmt.Printf("Worker %d received %c\n",id, <-c) //每次接收到数据就打印 否则就阻塞
}
}
func chanDemo(){
var channels [10]chan int //定义数组变量为chan类型 并且chan接收数据类型是int
for i :=0; i< 10; i++{
channels[i] = make(chan int) //初始化变量 只有初始化后才可以使用
go worker(i,channels[i])
}
for i:=0; i< 10; i++{
channels[i] <- 'a'+i //将指定数组添加信息
}
for i:=0; i< 10; i++{
channels[i] <- 'A'+i //将指定数组添加信息
}
time.Sleep(time.Millisecond) //延迟函数结束一毫秒
}打印结果如下
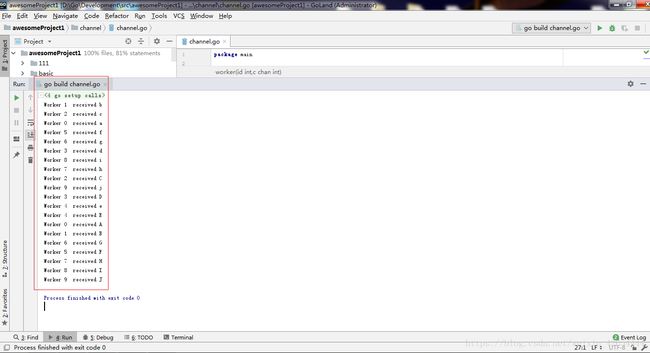
可以看见打印的结果是乱序的
为什么我们代码是有序的输入 而输出会变成乱序呢
这是因为有fmt.printf函数 类似这种I/O函数会调用系统的调度器 系统调度器会进行抢占式控制
下面再来一个返回值是chan的例子
func createworker(id int) chan int{ //chan做类型 同时返回值为chan int
c := make(chan int) //函数内做创建操作
go func() { //go关键字与chan形影不离
for{
fmt.Printf("Worker %d received %c\n",id, <-c) //每次接收到数据就打印 否则就阻塞
}
}()
return c //返回chan 类似与返回指针 外部填充chan时内部同时变化
}
func chanDemo(){
var channels [10]chan int //定义数组变量为chan类型 并且chan接收数据类型是int
for i :=0; i< 10; i++{
channels[i] = createworker(i) //得到返回值
}
for i:=0; i< 10; i++{
channels[i] <- 'a'+i //将指定数组添加信息
}
for i:=0; i< 10; i++{
channels[i] <- 'A'+i //将指定数组添加信息
}
time.Sleep(time.Millisecond) //延迟函数结束一毫秒
}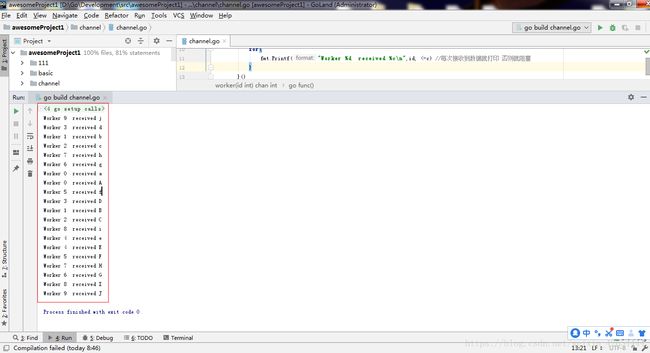
打印顺序不同但结果相同 证明chan int 返回值可用
讲到这我们补充三个语法方面的小知识 一个是箭头的作用
func createworker(id int) chan <-int //函数返回值指定输入输出格式
func createworker(id int) <-chan int
var channels [10]chan <-int //相对应的是chan定义时需要与返回值相同
var channels [10]<-chan int //可以定义多个chan int 接收多个返回值还有一个是缓冲期概念
func worker(id int , c chan int) { //go关键字与chan形影不离
for{
fmt.Printf("Worker %d received %c\n",id, <-c) //每次接收到数据就打印 否则就阻塞
}
}
func bufferedChannel(){
c := make(chan int, 3) //当我们创建时在第二个参数位置填入数字 这个数字就是缓冲期的大小
go worker(0, c)
c <- 'a'
c <- 'b'
c <- 'c'
///////////////////调用到c字符时不会报错 因为在缓冲期范围内
c <- 'd' //到d字符会报错 不过前提是没人接收chan 在上面我们用go wriker接收chan 所以不会报错 作了解即可
time.Sleep(time.Millisecond)
}最后一个就是结尾符
func worker(id int , c chan int) { //go关键字与chan形影不离
for n := range c{ //range自动判断c是否为空 如果为空结束循环 下面注释代码作用相同
//n, ok := <- c
//if!ok{
// break;
//}
fmt.Printf("Worker %d received %c\n",id, n) //每次接收到数据就打印 否则就阻塞
}
}
func channelClose(){
c := make(chan int, 3)
go worker(0, c)
c <- 'a'
c <- 'b'
c <- 'c'
c <- 'd'
close(c) //向变量c中传输空值
time.Sleep(time.Millisecond)
}channel的基本语法说完了
我们接下来看例子1
贴上一位大神说过的话
不要通过共享内存进行通信 而要通过通信共享内存
现在我们试图让并发互相通信
func doworker(id int , c chan int,done chan bool) {
for n := range c{ //range自动判断c是否为空 如果为空结束循环 下面注释代码作用相同
fmt.Printf("Worker %d received %c\n",id, n) //每次接收到数据就打印 否则就阻塞
done <- true //协程之间通信 done一直再向done输入
}
}
type worker struct { //结构体类型方便传输数据
in chan int
done chan bool
}
func createworker(id int) worker{
w := worker{ //结构体初始化并赋值给变量
make(chan int),
make(chan bool),
}
go doworker(id,w.in,w.done) //并发函数
return w //返回结构体 类似指针 函数外面给他赋值里面同时变化 包括并发函数内部!
}
func chanDemo(){
var workers [10]worker //定义数组变量为chan类型 并且chan接收数据类型是int
for i :=0; i< 10; i++{
workers[i] = createworker(i) //得到返回值
}
for i, worker := range workers{
worker.in <- 'a'+i //将指定数组添加信息
}
for _, tt := range workers{
<-tt.done //输出相应chan
}
for i, worker := range workers{
worker.in <- 'A'+i //将指定数组添加信息
}
for _, tt := range workers{
<-tt.done //输出相应chan
}
}可以看到协程直接通信主要依靠 chan赋值的变量 当协程主动交出控制权后 此次循环+1
chan的输入值与对应的输出值组成了协程通信的过程
除此之外 go语言还提供了另一种语法 sync.waitGroup
我们看下面的例子
func doworker(id int , c chan int,wg *sync.WaitGroup) {
for n := range c{ //range自动判断c是否为空 如果为空结束循环 下面注释代码作用相同
fmt.Printf("Worker %d received %c\n",id, n) //每次接收到数据就打印 否则就阻塞
wg.Done() //每次阻塞结束后done一次
}
}
type worker struct { //结构体类型方便传输数据
in chan int
wg *sync.WaitGroup //结构体内部数据更换
}
func createworker(id int,wg * sync.WaitGroup) worker{
w := worker{ //结构体初始化并赋值给变量
make(chan int),
wg,
}
go doworker(id,w.in,wg) //并发函数
return w //返回结构体 类似指针 函数外面给他赋值里面同时变化 包括并发函数内部!
}
func chanDemo(){
var wg sync.WaitGroup //定义系统提供的waitgroup
var workers [10]worker //定义数组变量为chan类型 并且chan接收数据类型是int
for i :=0; i< 10; i++{
workers[i] = createworker(i,&wg) //得到返回值 传参时注意引用地址
}
wg.Add(20) //初始化内容个数 如果不知道可以放在函数内+1
for i, worker := range workers{
worker.in <- 'a'+i //将指定数组添加信息
//wg.Add(1)
}
for i, worker := range workers{
worker.in <- 'A'+i //将指定数组添加信息
}
wg.Wait() //接收done
}waitgrout同样可以使协程之间通讯
但是我们发现使用*sync.waitgrout使得程序显得很乱不整洁 下面我们优化一下代码
func doworker(id int ,c chan int, w worker) {
for n := range c{ //range自动判断c是否为空 如果为空结束循环 下面注释代码作用相同
fmt.Printf("Worker %d received %c\n",id, n) //每次接收到数据就打印 否则就阻塞
w.done() //每次阻塞结束后done一次
}
}
type worker struct { //结构体类型方便传输数据
in chan int
done func() //结构体内部数据更换为函数
}
func createworker(id int, wg *sync.WaitGroup) worker{
w := worker{ //结构体初始化并赋值给变量
make(chan int),
func(){ //函数式编程无处不在 将函数作为参数之一赋值
wg.Done()
},
}
go doworker(id,w.in,w) //并发函数
return w //返回结构体 类似指针 函数外面给他赋值里面同时变化 包括并发函数内部!
}
func chanDemo(){
var wg sync.WaitGroup //定义系统提供的waitgroup
var workers [10]worker //定义数组变量为chan类型 并且chan接收数据类型是int
for i :=0; i< 10; i++{
workers[i] = createworker(i,&wg) //得到返回值 传参时注意引用地址
}
wg.Add(20) //初始化内容个数 如果不知道可以放在函数内+1
for i, worker := range workers{
worker.in <- 'a'+i //将指定数组添加信息
//wg.Add(1)
}
for i, worker := range workers{
worker.in <- 'A'+i //将指定数组添加信息
}
wg.Wait() //接收done
}从代码中可以看出函数式编程无处不在 将函数作为类型 并将函数赋值 这样我们就可以用结构体进行参数传递了
那么第一个例子 我们使用了channel来等待goroutine 还有系统带有的waitGroup
下面我们继续看第二个例子
是用channel进行树的遍历
///////////////////////////////////////////////////////
type treeNode struct {
value int
left, right *treeNode/////////////////这是二叉树内容这里省略不讲 在博客其他文章有详细讲解
}
func (node treeNode) Print() {
fmt.Print(node.value, " ")
}
func (node *treeNode) setTreeNode(value int) {
if node == nil {
fmt.Println("Setting value to nil node. Ignored.")
return
}
node.value = value
}
func (node *treeNode) traverse() {
node.TraverseFunc(func (n *treeNode){
n.Print()
})
fmt.Println()
}
func (node *treeNode) TraverseFunc(f func(node *treeNode)){
if node == nil {
return
}
node.left.TraverseFunc(f)
f(node)
node.right.TraverseFunc(f)
}
///////////////////////////////////////////////////////
//-----------------------------------------------------------
func (node *treeNode)TraverseWithChannel() chan *treeNode{// | 返回值为chan 内部参数为*treeNode 注意不要混淆 返回的是chan类型
out := make(chan *treeNode) // | 初始化并赋值 和前面的例子一样只不过类型为指针 同学们不要犯晕
go func(){ // | 开并发 向out输入内容 注意! 匿名函数内没有for循环 并发不是死循环
node.TraverseFunc(func(node *treeNode){ // |本次内容
out <- node // | 传输一次内容 结束匿名函数
}) // |
close(out) //| 向out传输空值
}() // |
return out //| 返回out 注意 out是函数 只返回一次 下面循环调用的是函数内部参数
} // |
//-----------------------------------------------------------
///////////////////////////////////////////////////////
func createTreeNode(value1 int) *treeNode {/////////////////这是二叉树内容这里省略不讲 在博客其他文章有详细讲解
return &treeNode{value: value1}
}
func main() {
var root treeNode
root = treeNode{value: 3}
root.left = &treeNode{}
root.right = &treeNode{5, nil, nil}
root.right.left = new(treeNode)
root.left.right = createTreeNode(2)///////////////////这是二叉树内容这里省略不讲 在博客其他文章有详细讲解
root.right.left.setTreeNode(4)
root.traverse()
/////////////////////////////////////////////////////////
//---------------------------------
c := root.TraverseWithChannel()// | 赋值变量c为代替函数
max := 0 // |
for node := range c { // | 循环找出函数内的参数进行比较
if max < node.value{ // |
max = node.value // |本次内容
}
}
fmt.Println(max) // | 输出结果
}
//------------------------------------这个小例子让我们发现 原来函数也可以作为channel进行运算
函数作为协程通讯的一种方式 大大提高了go语言并发的灵活性 当然其他语言也有类似语法
最后我们来看第三个例子
使用select进行调度
func GenReceived() chan int{ //函数内初始化
out := make(chan int)
i := 0
go func(){
for {
time.Sleep(time.Duration(rand.Intn(1500)) * time.Millisecond) // 在1-1500毫秒之间循环一次
out <- i //死循环 一直放入数据
i++
}
}()
return out //返回out 类似指针 只要out在这个函数内发生变化 外面都会接收并打印
}
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
for {
select {
case n := <-c1: //将返回值赋值给n
fmt.Printf("Received from c1%d\n", n) //打印成功
case n := <-c2:
fmt.Printf("Received from c2%d\n", n)//通过运行程序 可以看出 打印是无序的 这是因为GenReceived函数时随机循环的
//default:
//fmt.Println("同样可以使用default")
}
}
}通过这个例子来看 select语法方面与switch相同
我们再增加一下难度
当一个函数的返回值是chan 函数里面的chan要依靠返回值才能继续运行时应该怎么处理
func worker(id int , c chan int) { //go关键字与chan形影不离
for n := range c{ //range自动判断c是否为空 如果为空结束循环 下面注释代码作用相同
fmt.Printf("Worker %d received %d\n",id, n) //每次接收到数据就打印 否则就阻塞
}
}
func createworker(id int) chan int{ //chan做类型 同时返回值为chan int
c := make(chan int) //函数内做创建操作
go worker(id,c)
return c //返回chan 类似与返回指针 外部填充chan时内部同时变化
}
func GenReceived() chan int{ //函数内初始化
out := make(chan int)
i := 0
go func(){
for {
time.Sleep(time.Duration(rand.Intn(1500)) * time.Millisecond) // 在1-1500毫秒之间循环一次
out <- i //死循环 一直放入数据
i++
}
}()
return out //返回out 类似指针 只要out在这个函数内发生变化 外面都会接收并打印
}
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
w := createworker(0) // 将函数赋值给w w具有返回指针的作用
for {
select {
case n := <-c1: //将返回值赋值给n
w <- n //将n值赋给w的返回值 w函数接收并打印
case n := <-c2:
w <- n
}
}
}从例子中我们可以发现 原来函数的返回值赋值同样可以使用 <-
那我们继续改造例子 如果想让select同时可以接收或输出应该怎么做呢 (上面的例子是先输出后输入)
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
worker := createworker(0) // 将函数赋值给worker worker具有返回指针的作用
hasValue := false //初始化判断 用于select使用
n := 0 //初始化n值
for {
var activeWorker chan int //创建与worker返回值相同类型 注意创建初始值为nil 如果case碰到nil之间跳过不进行操作
if hasValue{
activeWorker = worker //当判断true时 代表有数据可以接收 此时可以被赋值 case可以操作
}
select {
case n = <-c1: //将返回值赋值给n
hasValue = true //将hasValue打开 此时 activeWorker可以进入
case n = <-c2:
hasValue = true
case activeWorker<- n: //判断成功后进行赋值
hasValue = false //重新关闭通道
}
}
}这里我们采用的方法是让 case判断是否有数据需要传输 这样就可以同时输入及输出了
但是我们我们这个例子有一个问题 如果接收与发送不同步 存在误差怎么办 比如输入速度快 连续 输入1 2 3
那发送方就是连续true了 下发的判断语句只会接收一次 1 2 便不会打印出来了
那我们怎么处理这个问题呢
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
worker := createworker(0) // 将函数赋值给worker worker具有返回指针的作用
n := 0 //初始化n值
var values []int //创建数组缓存n值
for {
var activeWorker chan int //创建与worker返回值相同类型 注意创建初始值为nil 如果case碰到nil之间跳过不进行操作
var activeValue int //接收一次参数
if len(values) > 0{
activeWorker = worker //当判断true时 代表有数据可以接收 此时可以被赋值 case可以操作
activeValue = values[0] //赋值
}
select {
case n = <-c1: //将返回值赋值给n
values = append(values,n) //每一次累加到数组中
case n = <-c2:
values = append(values,n)
case activeWorker<- activeValue: //判断成功后进行赋值
values = values[1:] //将赋值成功后的值删除
}
}
}通过数组进行缓存 每一个数字都进行打印
但是接踵而来的是另一个问题 我们缓存的空间随着时间会越来越大 我们想要看看空间的增长
那我们先把程序时间设定为运行10秒结束 然后再看空间增长问题
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
worker := createworker(0) // 将函数赋值给worker worker具有返回指针的作用
n := 0 //初始化n值
var values []int //创建数组缓存n值
tm := time.After(10 * time.Second) //创建程序结束时间 当到达设定时间后 会向tm变量赋值 case便会执行
for {
var activeWorker chan int //创建与worker返回值相同类型 注意创建初始值为nil 如果case碰到nil之间跳过不进行操作
var activeValue int //接收一次参数
if len(values) > 0{
activeWorker = worker //当判断true时 代表有数据可以接收 此时可以被赋值 case可以操作
activeValue = values[0] //赋值
}
select {
case n = <-c1: //将返回值赋值给n
values = append(values,n) //每一次累加到数组中
case n = <-c2:
values = append(values,n)
case activeWorker<- activeValue: //判断成功后进行赋值
values = values[1:] //将赋值成功后的值删除
case <- time.After(800 * time.Millisecond): // 如果在间隔800毫秒内没人生成新的数据会打印一个timeout提示
fmt.Println("timeout")
case <- tm: //接收成功后 执行下面代码
fmt.Println("Bey bey")
return
}
}
}我们学会了通过时间控制程序的运行 因为要每隔一段时间来看空间的增长 所以先了解一下时间控制的概念
好了我们接着来看 空间增长的问题
func main(){
var c1, c2 = GenReceived(), GenReceived() // c1 c2 代理 函数返回指针
worker := createworker(0) // 将函数赋值给worker worker具有返回指针的作用
n := 0 //初始化n值
var values []int //创建数组缓存n值
tm := time.After(10 * time.Second) //创建程序结束时间 当到达设定时间后 会向tm变量赋值 case便会执行
tick := time.Tick(time.Second) //每隔一秒发送一次chan time.Tick的返回值为chan
for {
var activeWorker chan int //创建与worker返回值相同类型 注意创建初始值为nil 如果case碰到nil之间跳过不进行操作
var activeValue int //接收一次参数
if len(values) > 0{
activeWorker = worker //当判断true时 代表有数据可以接收 此时可以被赋值 case可以操作
activeValue = values[0] //赋值
}
select {
case n = <-c1: //将返回值赋值给n
values = append(values,n) //每一次累加到数组中
case n = <-c2:
values = append(values,n)
case activeWorker<- activeValue: //判断成功后进行赋值
values = values[1:] //将赋值成功后的值删除
case <- time.After(800 * time.Millisecond): // 如果在间隔800毫秒内没人生成新的数据会打印一个timeout提示
fmt.Println("timeout")
case <- tick : //接收一次信号便打印一次长度
fmt.Println("queue len = ", len(values))
case <- tm: //接收成功后 执行下面代码
fmt.Println("Bey bey")
return
}
}
}每隔一秒便会打印一次数组长度
那么在实际的开发过程中 数据不同步我们要用缓存给他接住 接住后在使用
最后一个例子也结束了
我们总结一下select的使用
.非阻塞时使用 当需要协程之间通信并且不希望他们阻塞时 在select中设置非阻塞即可 这样他们可以各忙各的
.定时器使用 我们演示了三种定时器的使用方法
.在Select中使用nil Channel 当case判断时 可以使用nil进行false判别 当然需要在在创建时让channel为nil
例子讲完了 从第三个例子可以看出来 相当复杂的同步机制也只需要channel通信 不过我们只了解channel还不够
我们再来看一下传统同步机制 虽然大部分情况下用不到 但也要了解一些
.WaitGroup 通过封装chan 使得看起来像一个传统机制
.Mutex 互斥量
.cond 这些在go语言中都可以使用
传统同步机制能用归能用 我们在CSP模式下尽量少用(go语言并发处理采用的CSP模式架构)
下面再看一个互斥量的例子
type atomicInt int //简单的例子 测试读写之间的冲突
func (a *atomicInt) increment(){
*a++
}
func (a *atomicInt) Get() int{
return int(*a)
}
func main() {
var a atomicInt
a.increment()
go func(){
a.increment()
}()
time.Sleep(time.Millisecond)
fmt.Println(a)
}
运行结果为2 但是我们需要通过命令行来查看是否冲突
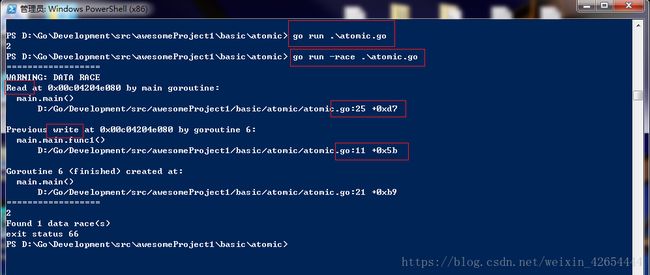
由于我们代码中还没有加锁 所以读写冲突了 下面我们加一下锁
//简单的例子 测试读写之间的冲突
type atomicInt struct{
value int
lock sync.Mutex //给数据添加锁选项
}
func (a *atomicInt) increment(){
a.lock.Lock() //锁住
defer a.lock.Unlock() // 解锁 注意 go语言中我们用defer进行最后的释放
a.value++
}
func (a *atomicInt) Get() int{
a.lock.Lock()
defer a.lock.Unlock()
return a.value
}
func main() {
var a atomicInt
a.increment()
go func(){
a.increment()
}()
time.Sleep(time.Millisecond)
fmt.Println(a.Get()) // 打印结果
}
 加锁之后打印结果很干净了 没有冲突
加锁之后打印结果很干净了 没有冲突
不过我们的锁只是一个示例 真正要用的话还是要用系统提供的原子化操作 不要自己重新做一遍
我们还有一个问题就是想让一个函数内的一块代码区进行保护 需要怎么做呢
func (a *atomicInt) increment(){
func(){ //匿名函数 让defer只在此代码区中作用
a.lock.Lock() //锁住
defer a.lock.Unlock() // 解锁 注意 go语言中我们用defer进行最后的释放
a.value++
}()
}传统机制我们就讲到这
在go语言中尽量使用channel
因为传统同步机制需要共享内存 为了保护内存使用大量复杂的机制 我们尽量避免使用。