主导资源公平DRF:多种资源类型的公平分配
目录
前言
摘要
1.介绍
2.动机
3.分配特性
4.主导资源公平(DRF)
4.1举个栗子
4.2DRF调度算法
4.3加权DRF
5.可选的公平分配策略
5.1资产公平
5.2收入均等的竞争均衡(CEEI)
5.3与DRF比较
6.分析
6.1公平性
6.1.1资产公平不具备的特性
6.1.2CEEI不具备的特性
6.1.3资源单调性VS共享激励和帕累托最优
6.2离散资源分配
7.实验结果
7.1动态资源分配
7.2DRF vs其他分配策略
7.3使用Facebook跟踪数据的模拟
8.相关工作
9.结论和未来工作
9.1未来工作
前言
本文是《Dominant Resource Fairness: Fair Allocation of Multiple Resource Types》的翻译版本,如果需要原文请点击https://people.eecs.berkeley.edu/~alig/papers/drf.pdf连接下载。
摘要
我们思考拥有多种资源类型的系统中的资源公平分配问题,其中每个用户可能对每个资源都有不同的需求。为了解决这个问题,我们提出了主导资源公平(DRF),它是最大-最小公平(max-min fariness)在多种资源类型上的推广。本文证明了DRF与其他可能的策略不同,它满足几个非常理想的特性。首先,DRF通过确保在资源之间平均分配的情况下,没有比较富裕的用户,鼓励用户共享资源。第二,DRF是策略防范(防操纵的),因为用户不能通过谎报需求来增加她的分配。第三,DRF是无嫉妒的,因为没有用户认为其他用户分配的资源比自己的更有价值。最后,DRF分配是帕累托最优的,因为不可能在不减少其他用户的份额的情况下改进某个用户的份额。Mesos集群资源管理器中实现了DRF,并表明它比当前集群调度器中基于槽的公平分配方案具有更好的吞吐量和公平性。
1.介绍
资源分配是任何共享计算机系统的关键组成部分。迄今为止提出的最流行的分配策略之一是最大-最小公平(max-min fairness),它最大化系统中用户接收的最小分配。假设每个用户都有足够的需求,此策略为每个用户提供平等的资源共享。最大-最小公平被推广到包括权重的概念,其中每个用户收到的资源份额与其权重成比例。
加权最大-最小公平吸引人源于其通用性和性能隔离的能力。加权最大-最小公平模型可以支持多种其他的资源分配策略,包括优先级、预留和基于截止期限(base deadline)的分配。此外,加权最大-最小公平确保隔离,在这一点上,无论其他用户的要求如何,用户都能得到她的份额。
鉴于这些特点,提出了大量算法来实现(加权)最大-最小公平并具有不同的精度也就不足为奇,如循环、比例资源分配和加权公平队列。这些算法已应用于多种资源,包括链路带宽,CPU、内存和存储。
尽管在公平分配方面进行了大量的工作,但到目前为止,重点主要集中在单一资源类型上。即使在用户具有异构资源需求的多资源环境中,分配通常也是使用单个资源抽象完成的。例如,Hadoop和Dryad这两个广泛使用的集群计算框架,把节点资源分割成固定大小的槽(slot),在槽这个级别分配资源。尽管这些集群中的不同工作可能对CPU、内存和I/O资源需求存在很大差异。
本文研究了用户对多种资源异构需求的公平分配问题。特别地,我们提出了主导资源公平(DRF),它是多种资源最大-最小公平的推广。DRF背后的思想是,在多种资源环境中,用户的分配应该由用户的主导份额决定,这是用户分配到全部资源的最大份额。简而言之,DRF最大限度地寻求在所有用户之间最小主导份额。例如,如果用户A运行重CPU型任务,而用户B运行重内存型任务,DRF将尝试使用户A的CPU份额与用户B的内存份额相等。在单资源情况下,DRF会将该资源的公平性换算到最大-最小公平。
DRF的优势在于其所满足了很多特性。对于单个资源,最大-最小公平可以轻易满足这些特性,但对于多种资源并不轻松。四个这样的特性是鼓励共享、策略防范、帕累托最优和无嫉妒。DRF静态和均等的把系统中的资源分配給用户,确保没有一个用户过得更好,为用户提供资源均分。此外,DRF是策略防范的,因为用户不能通过谎报其资源需求来获得更好的分配。DRF是帕累托最优的,因为它在满足其他特性的前提下分配所有可用资源,而不抢占已经分配的资源。最后,DRF是无嫉妒的,因为没有用户喜欢另一个用户分配的资源。其他解决方案至少违反了上述特性之一。例如,微观经济学理论中的公平分工机制,即平等竞争均衡不是策略防范的。
Mesos中实现并评估了DRF,Mesos是一个资源管理器,可以运行多个集群计算框架,如Hadoop和MPI。我们将DRF与Hadoop和Dryad中使用的基于槽的公平分配方案进行了比较,结果表明,基于槽的公平分配会导致性能下降,不公平地惩罚某些工作负载,同时提供较弱的隔离保证。
本文着重研究数据中心的资源分配问题,我们认为,DRF通常适用于用户具有异构需求的多资源环境,例如多核机器。
2.动机
虽然之前关于加权最大-最小公平的工作集中在单个资源上,但云计算和多核处理器的出现增加了对具有多个资源和异构用户需求的环境的分配策略的需求。对于多个资源,我们指的是不同类型的资源,而不是同一个可互换资源的多个实例。
为了激发对多资源分配的需求,我们在图1中绘制了一个月(2010年10月)内Facebook Hadoop 2000个节点集群中任务的资源使用概况。图1中圆的位置表示任务消耗的内存和CPU资源。圆的大小与圆区域内的任务数量成对数关系。虽然大多数任务都是重CPU的,但也存在重内存的任务,特别是为了减少操作。
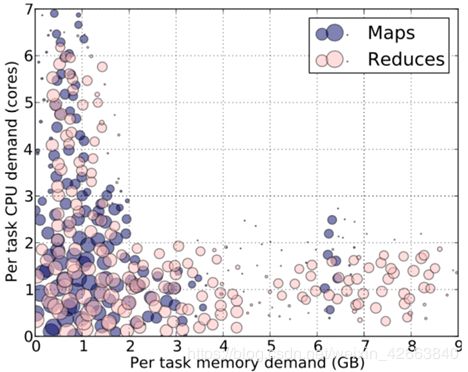
图1:Facebook2000节点Hadoop集群中超过一个月(2010年10月)任务的CPU和内存需求。每个气泡的大小是其区域中任务数的对数。
现有的集群公平调度程序,如Quincy和Hadoop公平调度程序,忽略了用户需求的异质性,并在槽的粒度上分配资源,其中槽是节点的固定分片。这导致效率低下的分配,因为槽常常与任务需求匹配不良。
图2量化了Hadoop MapReduce公平调度程序提供的公平性和隔离性级别。该图显示了任务CPU需求与槽CPU分配之间的比率以及任务内存需求与槽内存分配之间的比率的累计分布函数CDF。我们通过简单地将内存和CPU总量除以插槽数来计算槽内存和CPU占有率。比率1对应于任务需求与槽资源之间的完美匹配,比率低于1对应于未充分利用槽资源的任务,而比率高于1对应于过度利用槽资源的任务,这可能导致任务波动。图2显示了大部分任务要么未充分利用要么过度利用它们的一些槽资源。修改每台机器的槽数并不能解决问题,因为这可能导致较低的总体利用率,或者由于过度使用而导致更多任务性能不佳。
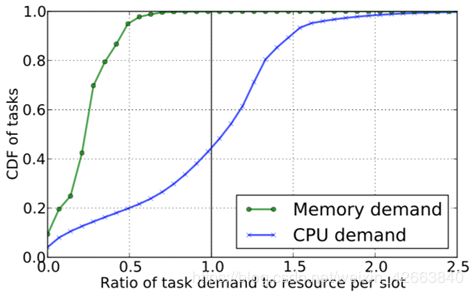
图2:Facebook2000个节点集群在一个月内(2010年10月)的需求/槽CDF。需求/槽为2.0表示需要的CPU(或内存)是槽CPU(或内存)大小的两倍的任务。
3.分配特性
现在,我们将注意力转向为多种资源和异构请求设计一个最大-最小公平分配策略。为了说明这个问题,考虑一个由9个CPU和18 GB内存组成的系统,以及两个用户:用户A运行需要1个CPU 、4 GB内存的任务,而用户B运行需要3个CPU核、1 GB内存的任务。什么是公平分配政策?
一种可能是为每个用户分配每个资源的一半。另一种可能是使每个用户的聚合(即CPU加内存)分配相等。虽然提出各种可能的“公平”分配相对容易,但是如何评估和比较这些分配尚不清楚。
为了应对这一挑战,我们从一组不受欢迎的特性开始,我们相信任何针对多种资源和异构需求的资源分配策略都应该满足这些特性。然后,我们让这些特性指导开发公平的分配策略。我们发现以下四个特性很重要:
- 鼓励共享:每个用户应该更好地共享集群,而不是独享用她自己的集群分区。考虑具有相同节点和n个用户的集群。那么,用户应该不能够在由1/n所有资源组成的集群分区中运行更多的任务。
- 策略防范:用户不应该通过谎报他们的资源需求而获益。这也具备通用性,因为用户无法通过撒谎来改善其分配。
- 无嫉妒:用户不应该喜欢其他用户分配的资源。这一性质体现了公平的概念。
- 帕累托最优:如果增加某个用户的份额只能减少其他至少一个用户的份额。这一特性非常重要,因为它可以在满足其他特性的前提下最大限度地提高系统利用率。
我们简要地评述了策略防范和鼓励共享特性,我们认为这些特性在数据中心环境中特别重要。我们已经讨论过的来自云运营商的有意思的迹象表明,策略防范很重要,因为用户试图操纵调度程序是很常见的。例如,Yahoo的Hadoop MapReduce数据中心有不同数量的槽用于map和reduce任务。一位用户发现map槽是竞争对手,因此只要在reduce阶段他就启动他的所有作业,MapReduce将手动完成map阶段的工作。另一家大型搜索公司只在用户能够保证高利用率的情况下才为工作提供专用机器。该公司很快发现,用户会在代码中加入有限循环,人为地提高利用率。
此外,满足鼓励共享特性的任何策略也提供性能隔离,因为它保证对每个用户最小分配(即,无论其他用户的需求如何,用户不能做得比拥有集群的1/n更糟)。
显而易见,在单个资源的情况下,最大-最小公平满足上述所有特性。然而,在多个资源和异构用户需求的情况下实现这些特性并非易事。例如,微观经济学理论中的公平分工机制,即平等收入的竞争均衡,并不是策略防范的。
除了上述特性外,我们还考虑了其他四个很好的特性:
- 单资源公平性:对于单资源,解决方案应该蜕变到最大-最小公平。
- 瓶颈公平性:如果有一个资源是每个用户都最需要的,那么解决方案应该蜕变到该资源的最大-最小公平。
- 总体单调性:当用户离开系统并放弃其资源时,剩余用户的分配不应减少。
- 资源单调性:如果系统增加了更多的资源,则现有用户的分配不应减少。
4.主导资源公平(DRF)
我们提出了主导资源公平性(DRF),这是一种针对多种资源的新分配策略,满足上一节中所有四个必需特性的要求。对于每个用户,DRF计算分配给该用户的每个资源的份额。用户所有份额中的最大值称为该用户的主导份额,与主导份额相对应的资源称为主导资源。不同的用户可能拥有不同的主导资源。例如,运行计算密集型作业的用户的主导资源是CPU,而运行I/O密集型作业的用户的主导资源是带宽。DRF简单地将最大-最小公平应用于用户的主导占比的资源上。也就是说,DRF寻求最大化系统中最小的主导份额,然后是第二个最小的份额,依此类推。
在本节中,我们考虑一个具有n个用户和m种资源的计算模型。每个用户运行单独的任务,每个任务都有一个需求向量,它指定了任务所需的资源量,例如1 个CPU核、4 GB内存。一般来说,任务(甚至是属于同一用户的任务)可能有不同的需求。
4.1举个栗子
考虑一个具有9个CPU核、18 GB内存和两个用户的系统,其中用户A使用需求向量1个CPU核、4 GB内存运行任务,而用户B使用需求向量3个CPU核、1G内存运行任务。
在上面的场景中,来自用户A的每个任务消耗了总CPU的1/9和总内存的2/9,因此用户A的主导资源是内存。用户B的每个任务消耗了总CPU的1/3和总内存的1/18,因此用户B的主导资源是CPU。DRF将均衡用户的主要份额,给出图3中的分配:用户A的三个任务,总共3个CPU核,12GB内存,用户B的两个任务,总共6个CPU核,2GB内存。通过这种分配,每个用户最终得到相同的主导份额,即用户A得到2/3的RAM,而用户B得到2/3的CPU。
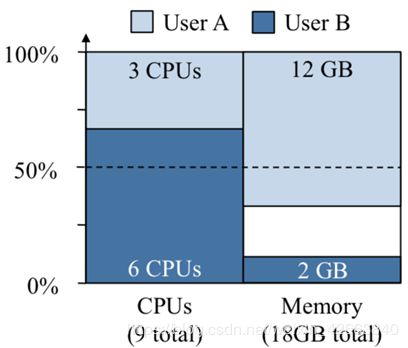
图3: DRF分配的示例
这种分配可以用数学方法计算,如下所示。设x和y分别是DRF分配给用户A和B的任务数。用户A获得

解决这个问题会得到x=3和y=2。因此,用户A得到<3CPU,12GB>,而B得到<6CPU,2GB>。
请注意,DRF并不总是需要平衡用户的主导份额。当一个用户的总需求得到满足时,该用户将不需要更多的任务,因此多余的资源将在其他用户之间进行分配,就像在最大-最小公平中一样。此外,如果一种资源耗尽,不需要该资源的用户仍然可以继续获得其他资源的更高份额。我们在下一节中提出了一种DRF分配算法。
4.2DRF调度算法
算法1显示了DRF调度的伪代码。该算法跟踪分配给每个用户的总资源以及用户的主导份额, si 。在每一步中,DRF都会在那些准备运行任务的用户中选择占主导份额最低的用户。如果该用户的任务需求可以满足,即系统中有足够的可用资源,则会启动其中一个任务。我们考虑一个一般情况,在这种情况下,用户可以拥有具有不同需求向量的任务,并且我们使用变量Di来表示我想要启动的下一个任务用户的需求向量。为了简单起见,并没有在伪代码捕获任务退出事件。在这种情况下,用户释放任务的资源,DRF再次选择具有最小主导份额的用户来运行他的任务。

考虑第4.1节中的两个用户示例。表1说明了这个示例的DRF分配过程。DRF首先选择B来运行一个任务。因此,B的份额变成3/9,1/18,占主导的份额最大(3/9,1/18)=1/3。接下来,DRF选择A,因为她的主导份额是0。此过程将继续,直到无法再运行新任务为止。在这种情况下,一旦CPU饱和,就会发生这种情况。
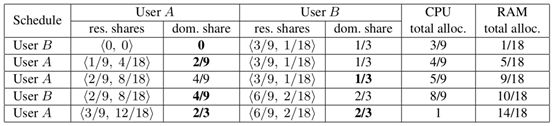
在上述分配结束时,用户A得到<3 CPU,12 GB>,而用户B得到<6 CPU,2 GB>,即每个用户得到其主资源的2/3。
注意,在这个例子中,一旦任何资源饱和,分配就会停止。但是,在一般情况下,即使某些资源已饱和,也可能继续分配任务,因为某些任务可能对饱和的资源没有任何需求。
上述算法可以使用存储每个用户的主导份额的二叉堆来实现。然后,对于n个用户,每个调度决策都需要O(log n)时间。
4.3加权DRF
实际上,在许多情况下,在用户之间平均分配资源并不是理想的策略。相反,我们可能希望将更多的资源分配给运行更重要作业的用户,或者分配给向集群提供更多资源的用户。为了实现这一目标,我们提出了加权DRF,这是DRF和加权最大-最小公平的一个推广。
对于加权DRF,每个用户i都关联一个权重向量Wi = 〈wi,1 , . . . , wi,m 〉, 其中wi,j表示用户i的资源j的权重。用户i的主导份额的定义变为s i=maxj{ui,j/wi,j},其中ui,j表示用户i对资源j的份额。特定情况下,当用户i的所有权重都相等时,即wi,j=wi,(1≤j≤m)。在这种情况下,i和j用户的主导份额之间的比率将简单地为wi/wj。如果将所有用户的权重设置为1,则加权的DRF会退化到DRF。
5.可选的公平分配策略
在多资源系统中定义公平分配不是一个简单的问题,因为“公平”的概念本身是可以讨论的。我们努力调查了许多分配政策,最后确定DRF作为唯一一项满足第3节中所有四项要求的特性的:鼓励共享、策略防范、帕累托最优和无嫉妒。在本节中,我们考虑了我们调查的两个可选方案:资产公平,一种简单而直观的策略,旨在使分配给每个用户的总资源均等,以及微观经济领域公平配置资源选择的平等收入竞争均衡(CEEI)策略。我们将这些策略与DRF进行比较。
5.1资产公平
资产公平性背后的思想是:不同资源的相同份额价值相同,即,所有CPU价值的1%与内存的1%和I/O带宽的1%相同。然后,资产公平试图均衡分配给每个用户的总资源值。特别是,资产公平为每个用户计算总的份额xi =∑jsi,j,其中Si,j是给用户i的资源j的份额,然后在用户的总份额上应用最大-最小公平,即它以最小的总份额重复地为用户启动任务。
考虑4.1节中的例子。因为内存的GB数量是CPU核数的两倍(即9个CPU核和18GB 内存),所以一个CPU核的价值是1GB 内存的两倍。假设1GB值1块钱,一个CPU核值2块钱,那么用户A每个任务花费6块钱,而用户B花费7块钱。设x和y分别是由资产公平分配给用户A和B的任务数量。然后,通过求解下列优化问题给出的资产公平分配是:

解决上述问题得出x=2.52,y=2.16。因此,用户A得到2.5个CPU,10.1 GB,而用户B得到6.5个CPU,2.2 GB。
虽然这种分配政策在其简单性上似乎引人注目,但它有一个显著的缺点:它违反了鼓励共享特性。6.1.1章节会证明资产公平可能导致一个用户获得资源少于总资源的1/n,其中n是用户总数。
5.2收入均等的竞争均衡(CEEI)
在微观经济学理论中,公平分配资源的首选方法是CEEI。对于CEEI,每个用户最初每个资源拥有的1个,随后,n个用户在完全竞争的市场中与其他用户交换其资源。CEEI的出局因为只有无嫉妒和帕累托最优。
更准确地说,CEEI分配由纳什讨价还价解给出。纳什讨价还价解选择可行的分配,以最大化∏i ui(ai),其中ui(ai)是用户i从她的分配ai中获得的实用价值。为了简化比较,我们假设用户从其分配中获得的效用与她占主导份额si相同。
再次考虑前面节中的两个用户示例。回想一下,用户A的主导份额是4x/18=2x/9,而用户B的主导份额是3y/9=y/3,其中x是给a的任务数,y是给b的任务数,最大化主导份额的结果等于最大化x·y的结果,因此,CEEI旨在解决以下优化问题:

解决上述问题得到x=45/11和y=18/11。因此,用户A得到4.1个CPU,16.4 GB,而用户B得到4.9个CPU,1.6 GB。
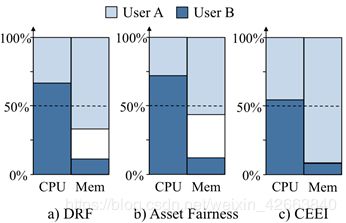
图4:DRF、资产公平性和CEEI在第4.1节的示例场景中给出的分配。
不幸的是,尽管CEEI是无嫉妒和帕累托最优的,但事实证明它并不是战略防范的,正如我们将在第6.1.2节中展示的那样。因此,用户可以通过谎报资源需求来增加分配。
5.3与DRF比较
为了让读者直观地理解资产公平性和CEEI,我们将它们在4.1节中的示例中的分配与图4中的DRF中的分配进行比较。
我们看到DRF均衡了用户的主导份额,即用户A的内存份额和用户B的CPU份额。相比之下,资产公平性均衡分配给每个用户的资源的总份额,即图中每个用户的矩形区域。最后,由于CEEI假设一个完全竞争的市场,它找到了一个满足市场准入要求的解决方案,其中每个资源都被分配。不幸的是,这一事实使得欺骗CEEI成为可能:即使用户不用也可以声称她需要更多未充分利用的资源,导致CEEI给这个用户更多的任务,以获得市场许可。
6.分析
在本节中,我们将讨论资产公平性、CEEI和DRF满足第3节中介绍的哪些特性。当任务大小与可用资源不完全匹配时,我们还评估DRF的准确性。
6.1公平性
表2总结了资产公平、CEEI和DRF满足的公平特性。在本节的其余部分中,我们将讨论表中一些有趣的丢失项,即每个算法违反的特性。特别地,我们通过实例说明了为什么资产公平和CEEI缺乏这些特性,并且我们证明任何策略都不能在不违背鼓励共享或帕累托最优的情况下提供资源单调性,从而解释了DRF缺乏资源单调性的原因。
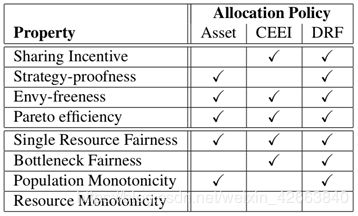
表2:资产公平性、CEEI和DRF的属性。
6.1.1资产公平不具备的特性
资产公平虽然是最简单的策略,但却违背了几个重要的属性:鼓励共享、瓶颈公平性和资源单调性。接下来,我们使用示例来展示这些特性的冲突。
定理1:资产公平违反了鼓励共享特性。
证明:考虑以下示例,如图5所示:在一个资源总量为<30,30>的系统中,两个用户具有需求向量d1=<1,3>和d2=<1,1>。资产公平性将分配第一个用户6个任务,第二个用户12个任务。第一个用户将收到<6,18>资源,而第二个将收到<12,12>资源。
当每个用户获得24个相等的总份额时,第二个用户得到的资源少于两个资源的一半(15)。这违反了鼓励共享特性,因为第二个用户静态分集群并独享一半的节点会更好。
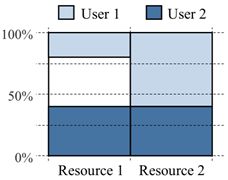
图5:资产公平可能无法满足鼓励共享特性的示例。资产公平为用户2提供的资源少于两种资源的一半。
定理2:资产公平违背了瓶颈公平性。
证明:考虑一个总资源向量为<21,21>和两个需求向量为d1=<3,2>和d2=< 4,1>的场景,使第一个资源成为瓶颈资源。资产公平性将为每个用户提供3个任务,将其总使用量平均为15。但是,这只给第一个用户3/7的第一个资源(争用的瓶颈资源),违反了瓶颈公平性。
定理3:资产公平不满足资源单调性。
证明:考虑两个用户A和B,其需求分别为<4,2>和<1,1>以及资源总量为<77,77>。资产公平分配了A<44,22>和B <33,33>的份额,使其份额总数平均为66/77。如果第2个资源总量翻倍,则两个用户在第2个资源中的份额将减半,而第一种资源是饱和的。资产公平在将A的分配减少到42、21,将B的分配增加到35、35,使其份额均衡到42/77+21/154=35/77+35/154=105/154,从而违背了资源的单调性。
6.1.2CEEI不具备的特性
虽然CEEI是无嫉妒和帕累托最优的,但事实证明它不是策略防范。直观地说,这是因为CEEI假设一个完全具有竞争力的市场,从而实现市场准入,即供需匹配和所有可用资源的分配。这可能导致用户无需竞争就可以从CEEI获得更高的份额,以便充分利用该资源。因此,用户可以声称,她需要更多未充分利用的资源来增加她的整体资源份额。我们将在下面对此进行说明。
定理4:CEEI不是策略防范的。
证明:考虑下面的例子,如图6所示。假设总资源向量为<100,100>,两个用户的需求分别为<16,1>和<1,2>。在这种情况下,CEEI分别为每个用户分配100/31和1500/31任务(大约3.2和48.8个任务)。如果用户1将其需求向量更改为<16,8>,要求比实际需要更多的第2个资源,CEEI将分别向用户提供25/6和100/3任务(大约4.2和33.3 3个任务)。因此,用户1通过谎报需求向量,她的任务数量从3.2增加到4.2。由于任务分配减少,用户2因此受到影响。
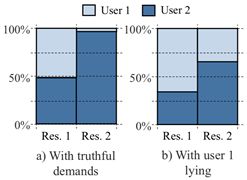
图6:展示CEEI如何违反策略防范的示例。用户1可以通过声称她比实际需要更多的资源2来增加她的份额。
定理5:CEEI违反了集群单调性
证明:考虑总资源向量<100,100>和三个具有以下需求向量的用户:d1=<4,1>、d2=<1,16>、d3=<16,1>(见图7)。CEEI将生成分配A1=<11.3,5.4,3.1>,其中括号中的数字表示分配给每个用户的任务数。如果用户3离开系统并放弃其资源,CEEI将给出新的分配A2=<23.8,4.8>,这使得用户2分配的资源比A1更糟。

图7:显示CEEI违反集群单调性的示例。当用户3离开时,CEEI将分配从a)更改为b),从而降低用户2的份额。
6.1.3资源单调性VS共享激励和帕累托最优
如表2所示,DRF实现了除资源单调性外的所有特性。这不是DRF的限制,而是鼓励共享、帕累托最优和资源单调性不能同时实现的结果。由于我们认为前两个属性更重要(见第3节),而且向系统添加新资源是一个相对罕见的事件,因此我们选择满足鼓励共享和帕累托最优,并放弃资源单调性。特别是,我们有以下结果。
定理6:满足鼓励共享和帕累托最优特性的分配策略不能同时满足资源单调性。
证明:我们使用一个简单的例子来证明这个性质。分别考虑两个具有对称需求<2,1>和<1,2>的用户A和B,并假设两个资源的总量相等。鼓励共享要求用户A获得至少一半的资源1,而用户B获得一半的资源2。根据帕累托最优,我们知道两个用户中至少有一个必须分配更多的资源。在不丧失通用性的情况下,假设用户A被赋予超过资源1的一半(如果用户B被赋予超过资源2的一半,则对称参数成立)。如果资源2的总量现在增加了4倍,那么用户B将不再获得其对资源2一半的保证份额。现在,满足鼓励共享的唯一可行分配是给两个用户一半的资源1,这就需要减少用户1对资源1的份额,从而破坏资源的单调性。
这个定理解释了DRF和CEEI都违反资源单调性的原因。
6.2离散资源分配
到目前为止,我们已经隐式地假设了一个大资源池,它的资源可以任意地小规模分配。当然,在实践中,情况往往不是这样。例如,集群由许多小型机器组成,其中资源以离散的数量分配给任务。在本节中,我们将这两个场景分别称为连续场景和离散场景。现在我们将注意力转向在离散场景中公平是如何受到影响的。
假设一个由k台机器组成的集群。让max-task表示所有需求向量的最大需求向量,即max-task=
定理7:与连续场景不同,在离散场景中,任意两个用户分配资源之间的差异的上限是一个max-task。
证明:假设我们开始一次在一台机器上分配资源,并且我们总是将任务分配给具有最低主导份额的用户。只要第一台机器上至少有一个最大任务的资源可用,我们就继续将一个任务分配给下一个份额最少的用户。一旦第一台机器上的可用资源小于最大任务,我们将移动到下一台机器并重复该过程。当分配完成时,两个用户对其主导资源的分配与连续场景的分配之差最多为max-task。如果不是这样的话,那么某个用户A与另一个用户B之间的差异将超过max-task的量。但是,这种情况不可能出现,因为最后一次A被分配任务时,B应该也被分配一个任务。
7.实验结果
本节通过微观和宏观的基准评估DRF。前者是通过在Mesos集群资源管理器中运行DRF实现的实验来实现的。后者是使用跟踪数据驱动的模拟完成的。
7.1动态资源分配
在我们的第一个实验中,我们展示了DRF如何在具有不同需求的作业之间动态地共享资源。我们在一个48节点的Mesos集群上运行了两个作业,使用4个CPU核和15GB内存的服务器。我们将Mesos配置为在每个节点上分配最多4个CPU核和14 GB的内存,为操作系统保留1 GB。我们提交了两个作业,在6分钟的时间间隔内,在不同的时间启动具有不同资源需求的任务。
图8(a)和8(b)显示了作为时间函数给每个作业的CPU和内存分配,而图8(c)显示了它们的主导份额。在前2分钟内,作业1每个任务使用<1 CPU,10 GB RAM>,作业2每个任务使用<1 CPU,1 GB RAM>。作业1的主导资源是内存,而作业2的主导资源是CPU。请注意,DRF平衡了主导资源的份额。此外,由于作业具有不同的主导资源,它们的主导份额超过50%,即作业1使用大约70%的RAM,而作业2使用大约75%的CPU。因此,与每个作业独享一半的节点相比,集群共享作业从中获益。这体现了鼓励共享的本质。
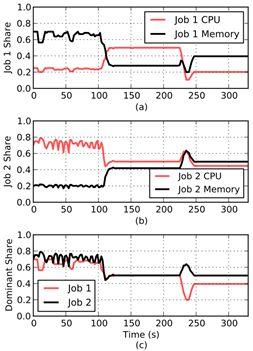
图8:两个作业的CPU、内存和主导份额。
2分钟后,两个作业的任务大小将更改,作业1变为<2CPUs,4GB>,作业2变为<1CPU,3GB>。现在,两个作业的主导资源都是CPU,所以DRF均衡它们的CPU份额。请注意,当任务完成时,DRF通过Mesos为最小主导份额的作业提供资源。
最后,再过2分钟,两个作业的任务大小再次发生变化:作业1变为<1 CPU,7 GB>和作业2变为<1 CPU,4 GB>。两个作业的主导资源现在都是内存,所以DRF试图平衡它们的内存份额。份额不完全相等的原因是由于资源碎片(见第6.2节)。
7.2DRF vs其他分配策略
接下来,我们将针对两种代替方案评估DRF:基于槽的公平调度(当前系统中的一种常见策略,如Hadoop公平调度器和Quincy)和(max-min)仅应用于单个资源(CPU)的公平分配。在实验中,我们在运行了一个48节点的Mesos集群,每个实例有8个CPU核和7 GB RAM。我们将Mesos配置为在每个节点上分配最多8个CPU和6 GB RAM,为操作系统提供1 GB的空闲空间。我们将这三个调度策略作为Mesos分配模块来实现。
我们使用两类用户运行的工作负载,表示两个具有不同工作负载的组织实体。其中一个实体有四个用户提交任务需求为<1 CPU,0.5 GB>的小作业。另一个实体有四个用户提交任务需求为<2CPU,2 GB>的大型作业。每项作业包括80项任务。一旦一个作业完成,用户就会启动另一个具有类似需求的作业。每个实验都进行了十分钟。最后,我们计算了每种类型的完成作业的数量以及它们的响应时间。
对于基于槽的分配方案,我们将每台机器的槽数从3个更改为6个,以了解它如何影响性能。图9到12显示了我们的结果。在图9和图10中,我们比较了每种类型的作业在10分钟内为每个调度方案完成的数量。在图11和12中,我们比较了平均响应时间。
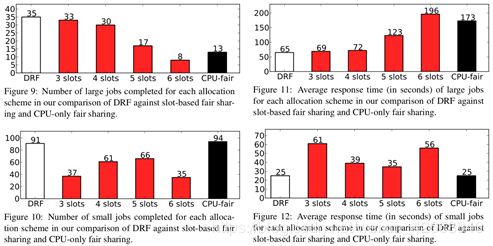
从数据来看,有几个趋势是明显的。首先,对于基于槽的调度,不管槽的数量如何,吞吐量和作业响应时间都比DRF差。这是因为使用较少的槽,调度程序让节点使用率不足(例如,在一个节点上只启动3个小任务),而使用较多的槽,调度程序让节点过度使用(例如,在一个节点上启动4个大任务并导致交换,因为每个任务需要2 GB,而节点只有6 GB)。第二,由于CPU级别的公平分配,执行的小作业数量与DRF类似,但执行的大作业数量要少得多,因为某些计算机上的内存过度使用,导致运行在那里的所有高内存任务的性能都很差。总的来说,这两种资源基于DRF的调度程序具有最低的响应时间和最高的总吞吐量。
7.3使用Facebook跟踪数据的模拟
接下来,我们将使用Facebook 2000节点集群的跟踪日志,其中包含为期一周的数据(2010年10月)。数据由Hadoop MapReduce作业组成。我们假设任务持续时间、CPU使用率和内存消耗与原始跟踪中相同。在400个节点的较小集群上模拟跟踪,以达到更高的利用率级别,从而使二者公平性可以对比。群集中的每个节点由12个槽、16个核和32 GB内存组成。图13显示了一个简短的300秒的子示例,用可视化方式展示与Hadoop的公平调度程序(槽)相比,使用DRF时CPU和内存的利用率。如图所示,DRF提供了更高的利用率,因为它能够更好地将资源分配与任务需求相匹配。
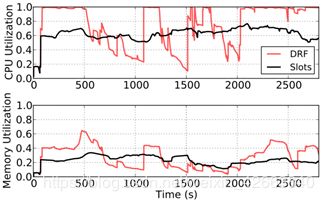
图13:DRF和Facebook Hadoop槽公平集群跟踪的CPU和内存利用率。
图14显示了与Hadoop 公平调度程序相比,DRF的平均作业完成时间减少。小型工作的工作负载相当大,没有改善(即-3%)。这是因为小作业通常只有一个执行阶段,完成时间由最长的任务决定。因此,对于这样的小工作来说,完成时间很难提高。相比之下,大工作的完成时间减少了66%。这是因为这些工作由许多阶段组成,因此它们可以从DRF实现的更高利用率中获益。
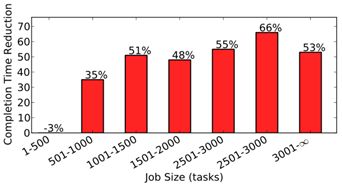
图14:Facebook Hadoop集群中跟踪的不同作业大小的平均减少完成时间。
8.相关工作
我们简要回顾计算机科学和经济学的相关工作。
虽然计算机科学的许多论文都关注多资源公平性,但它们只考虑同一可互换资源的多个实例,如CPU和带宽。与这些方法不同,我们关注的是不同类型的资源分配。
Quincy是一个在Dryad集群计算框架环境中开发的调度程序。Quincy通过将公平调度问题建模为low-cost flow问题来实现公平性。Quincy目前不支持多资源公平性。事实上,正如本文讨论部分所提到的,将多资源需求纳入low-cost flow公式似乎很困难。
Hadoop目前提供两个公平分配调度程序。这两个调度程序都以槽粒度分配资源,其中槽是计算机上资源的固定部分。因此,这些调度程序不能总是将资源分配与任务的需求相匹配,特别是当这些需求非常异构时。如第7节所示,这种不匹配可能导致集群利用率低,或者由于资源过度使用而导致性能低下。
在微观经济学文献中,公平问题是在博弈论框架内外进行研究的。Young和Moulin的书完全致力于这些主题,并提供了很好的介绍。正如Varian 所介绍的,微观经济学中公平划分的首选方法是CEEI。因此,我们在第5.2节中对此给予了相当大的关注。与DRF相比,CEEI的主要缺点是它不是战略防范。因此,用户可以通过撒谎来操纵调度程序。
微观经济学文献中提出的许多公平划策略都是基于效用的概念,因此侧重于效用的单一指标。在经济学文献中,最大-最小公平被称为效用的字典序(leximin)。
问题是多资源集合中的用户效用是什么,以及如何比较这些效用。一种自然的方法是将效用定义为分配给用户的任务数。但是这样的建模工具和leximin一起违反了我们提出的许多公平性属性。从这个角度来看,DRF有两个贡献。首先,它建议使用主导份额作为效用的代理,这是使用标准的leximin排序来均衡的。其次,我们证明了低于此类效用函数该方案是策略防范的。请注意,leximin排序是kalai-smordinsky(ks)解决方案的词典版本。因此,我们的结果表明,对于此类效用KS是策略防范的。
9.结论和未来工作
我们引入了主导资源公平(DRF),一种将最大-最小公平推广为多种资源类型的公平分配模型。DRF允许集群调度程序考虑到数据中心应用程序的异构需求,这使得资源分配比现有这些将相同的资源片(槽)分配给所有任务的解决方案更加公平,利用率也更高。DRF满足许多理想的特性。特别是,DRF是一种策略防范,因此可以鼓励用户准确地报告他们的需求。DRF还通过确保用户在共享集群中的性能至少与在较小的、独立的集群中的性能相同来鼓励用户共享资源。我们研究的其他调度程序,以及微观经济学文献中关于公平的其他概念,都不能满足所有这些特性。
我们通过在Mesos资源管理器中实现DRF对其进行了评估,结果表明,与目前普遍使用的基于槽的公平调度程序相比,它可以带来更好的总体性能。
9.1未来工作
未来的研究有几个有趣的方向。首先,在具有离散任务的集群环境中,一个有趣的问题是在不损害公平性的情况下最小化资源碎片。这个问题类似于装箱,但一个人必须满足DRF并打包尽可能多的物品(任务)。第二个方向涉及到在任务具有位置约束(如机器首选项)时定义公平性。鉴于当前多核机器的发展趋势,第三个有趣的研究方向是探索将DRF用作操作系统调度程序。最后,从微观经济学的角度来看,考虑到帕累托最优等其他可取的特性,一个自然的方向是研究DRF是否是多资