python数据挖掘实战笔记——文本挖掘(10):自动摘要
概念:
摘要: 全面准确地反映某一文献中心内容的简单连贯的短文。
自动摘要: 利用计算机自动地从原始文件中提取摘要。
算法原理: 余弦相似定理
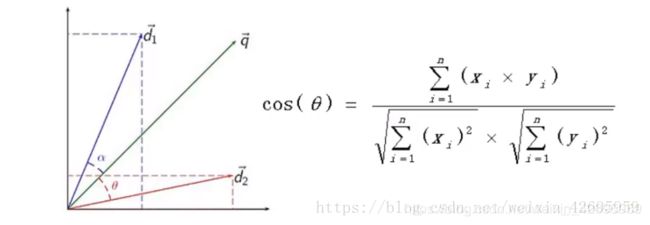
算法步骤:
- 获取需要摘要的文章
- 对该文章进行词频统计
- 对该文章进行分句,一般采用“,"、"."、?"进行分句。
- 计算分句与文章之间的余弦相似度。
- 取相似度最高的分句,作为文章的摘要。
下面是具体代码实现:
首先导入包:
#导入需要的包
import re
import os
import jieba
import codecs
import numpy
import pandas
import os.path
from sklearn.metrics import pairwise_distances
from sklearn.feature_extraction.text import CountVectorizer
然后和之前操作一样,构建语料库:
#构建语料库
#读取文件
filePaths = [];
fileContents = [];
for root, dirs, files in os.walk(
r"C:\Users\www12\Desktop\DA\pythonDM\2.10\\SogouC.mini\\Sample"
):
for name in files:
filePath = os.path.join(root, name);
filePaths.append(filePath);
f = codecs.open(filePath, 'r', 'utf-8')
fileContent = f.read()
f.close()
fileContents.append(fileContent)
#提取文件内容,文件路径到数据框
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
});
去掉停用词:
#读取停用词
stopwords = pandas.read_csv(
r'C:\Users\www12\Desktop\DA\pythonDM\2.10\StopwordsCN.txt',
encoding='utf8',
index_col=False,
quoting=3,
sep="\t"
)
#移除停用词
countVectorizer = CountVectorizer(
stop_words=list(stopwords['stopword'].values),
min_df=0, token_pattern=r"\b\w+\b"
)
到这里和之前的操作都是一样的,我们储存了每一篇文章的内容的数据框:

接着就是关键的部分,首先对每篇文章进行分句操作:
#分句
contents = [] #文章内容
summarys = [] #摘要
filePaths = [] #文件路径
for index, row in corpos.iterrows(): #读取每一行的数据,即每篇文章内容
filePath = row['filePath'] #将每一行的filepath储存到为filePath变量中
fileContent = row['fileContent'] #读取每一篇文章内容,并储存在fileContent中
#建立子语料库,以该文章和该文章的分句组成
subCorpos = [fileContent] + re.split( #re.split()将每文章根据标点符号分割成一个一个句子
r'[。?!\n]\s*',
fileContent
)
注意:在子语料库中,第一行为文章内容,接着是分句

点击,可以看到第一行是文章内容,将文章内容放到分句的第一行的目的是为了后续计算文章和句子之间的余弦相似度。
(注意不是计算分句之间的余弦相似度,这个坑我已经踩过了( ̄▽ ̄)")
然后对分句进行分词处理,然后构建词频矩阵:(这些都是熟悉的操作啦)
#分词
segments = []
suitCorpos = []
for content in subCorpos: #对所有文章中的句子进行分词
segs = jieba.cut(content) #分词结果储存到segs中
segment = " ".join(segs) #分词之间添加空格
if len(segment.strip())>10: #过滤掉少于10个长度的分词词组
segments.append(segment)
suitCorpos.append(content)
textVector = countVectorizer.fit_transform(segments) #将所有分词结果转换为词频矩阵
最后计算余弦相似度,得到下表,结果只看第一行,也就是每篇文章和该文章所有分句的余弦相似度,我们只关注这部分数据。
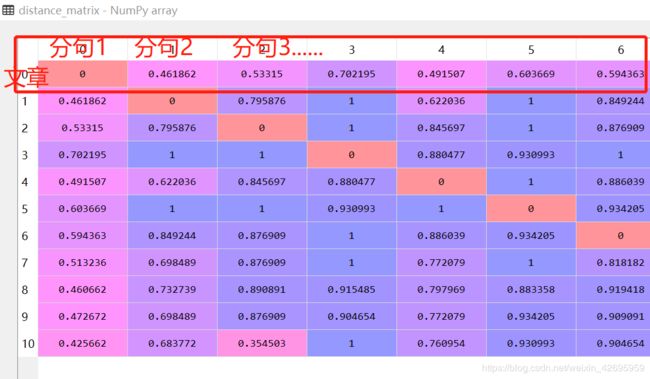
然后提取和文章最相似的句子,也就是值最小的那个
distance_matrix = pairwise_distances(
textVector,
metric="cosine"
) #计算文章和分句之间的余弦距离
sort = numpy.argsort(distance_matrix, axis=1) #对结果的第一行进行排序
summary = pandas.Index(suitCorpos)[sort[0]].values[1] #提取排序后的最小值的句子作为摘要
最后将生成的摘要和文章,文章路径都存放到数据框summaryDF中:
summarys.append(summary) #储存摘要
filePaths.append(filePath) #文件路径
contents.append(fileContent) #文章内容
#将所有文章及对于摘要存放到数据框中
summaryDF = pandas.DataFrame({
'filePath': filePaths,
'content': contents,
'summary': summarys
})
以最后一篇文章为例,查看结果:
a=summaryDF[99:]
print(a)

可以看出,摘要提取的还是挺合适的,到这里所有操作就完成了。
另外,之前的几篇都有用到numpy数组间接排序numpy.argsort()函数,关于生成的索引器,之后另开一篇文章写吧,在《利用python数据分析》这本书的Numpy高级数组应用中也有说明,索引器这个小东西还挺别致的 。
找不到说的是哪里,看刚才的代码:
sort = numpy.argsort(distance_matrix, axis=1) #对结果的第一行数组进行排序
summary = pandas.Index(suitCorpos)[sort[0]].values[1] #根据索引器返回排序后的数组,
并提取排序后的最小值的句子作为摘要
完事,睡觉。