DHT分布式哈希表通俗讲解
一、P2P及DHT网络简单介绍
P2P:在思想上可以说是internet思想/精神/哲学非常集中的体现,共同的参与,透明的开放,平等的分享。基于P2P技术的应用有很多,包括文件分享,即时通信,协同处理,流媒体通信等等。通过这些应用的接触,分析和理解,P2P其本质是一种新的网络传播技术,这种新的传播技术打破了传统的C/S架构,逐步地去中心化,扁平化,这或许在一定程度上应证了”世界是平的”趋势。P2P文件分享的应用(BTs/eMules等)是P2P技术最集中的体现,我们这里的研究也是以P2P文件分享网络作为入口,P2P文件分享网络的发展大致有以下几个阶段,包含tracker服务器的网络,无任何服务器的纯DHT网络, 混合型P2P网络。DHT网络发展即有“思想/文化”上的“发展”,也有一定的商业上的需求(版权管理)。
DHT:全称叫分布式哈希表(Distributed Hash Table),是一种分布式存储方法,一类可由键值来唯一标示的信息按照某种约定/协议被分散地存储在多个节点上,这样也可以有效地避免“中央集权式”的服务器(比如:tracker)的单一故障而带来的整个网络瘫痪。实现DHT的技术/算法有很多种,常用的有:Chord, Pastry, Kademlia等。我们这里要研究的是Kademlia算法,因为BT及BT的衍生派(Mainline, Btspilits, Btcomet, uTorrent…),eMule及eMule各类Mods(verycd, easy emules, xtreme…)等P2P文件分享软件都是基于该算法来实现DHT网络的,BT采用Python的Kademlia实现叫作khashmir(科什米尔,印巴冲突地带?),有如下官网。eMule采用C++的Kademlia实现干脆就叫作Kad,当然它们之间有些差别,但基础都是Kademlia。我们这里以BT-DHT为例进行分析介绍,下面说到的DHT都可以默认是BT-Kademlia-DHT。
二、Kademlia实现原理
各种DHT的实现算法,不论是Chord, Pastry还是Kademlia,其最直接的目标就是以最快的速度来定位到期望的节点,在P2P文件分享应用中则是以最快的速度来查找到正在分享某一文件/种子的peers列表信息。因为每个节点都是分布式存在于地球的任何角落,如果用地理距离来衡量两节点间的距离则可能给计算带来极大复杂性甚至不可能进行衡量,因此基本所有的DHT算法都是采用某种逻辑上的距离,在Kademlia则采用简单的异或计算来衡量两节点间的距离,它和地理上的距离没有任何关系,但却具备几何公式的绝大特征:
(1)节点和它本身之间的异或距离是0
(2)异或距离是对称的:即从A到B的异或距离与从B到A的异或距离是等同的
(3)异或距离符合三角形不等式:给定三个顶点A B C,假如AC之间的异或距离最大,那么AC之间的异或距离必小于或等于AB异或距离和BC异或距离之和.
(4)对于给定的一个距离,距离A只存在有唯一的一个节点B,也即单向性,在查找路径上也是单向的,这个和地理距离不同。
Kademlia中规定所有的节点都具有一个节点ID,该节点ID的产生方法和种子文件中的info hash采用相同算法:即sha-1(安全hash算法),因此每个节点的id,以及每个共享文件/种子的info-hash都是唯一的,并且都是20个字符160bits位组成。两个节点间的距离就是两个节点id的异或结果,节点和键值(种子文件)的距离为该节点的id和该种子文件的info-hash的异或结果。Kademlia在异或距离度量的基础上又把整个DHT网络拓扑组织成一个二叉前缀树),所有的节点(所有的正在运行的,并且开取了DHT功能的Bt,Btspilits应用)等作为该二叉前缀树的叶子节点,可以想象这棵二叉树可以容纳多达2128个叶子(节点),这足以组织任何规模的网络了。对于每个节点来说按照离自己的远近区域又可以把这棵树划分为160棵子树,每一个子树和该节点都有一个共同的前缀,共同前缀越少离得越远。如下图所示:
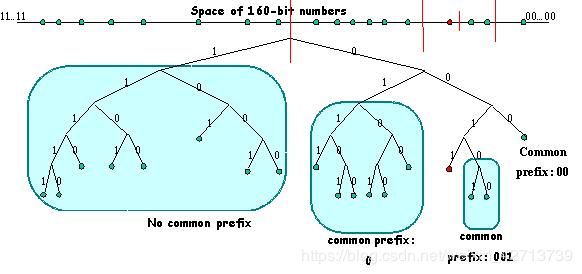
以上图红色节点0011为例,它可以把其他的节点划分位4棵不同子树,离自己越近子树和自己有越长的公共前缀,如果节点是均匀分布则离自己越近的子树含有的叶子节点更少(兄弟只有一个即和自己有159个共同前缀的那个)。因为节点都位于该树最底层的叶子位置,水平看上去则所有的叶子都在一条线上,如果把这条线当作2128空间的每一个点,则更能体现上面的划分特性(折半拆分)。为了能快速到达这160棵子树,处于DHT网络中的每一个节点都记录了每棵子树上的k个节点的信息(ip,port,id),在BT中K固定为8,比如上图中红色节点就可能保存有最左边子树的8个叶子节点信息,当然靠近自己的子树可能没有8个叶子,则把所有当前存在的叶子记录上去,这份记录信息在Kad算法中叫作K桶,也叫作“路由表”,当然这个“路由表”的信息和我们IP路由的含义有点不同,它代表的是为了到达处于距离自己某范围[ 2i — 2i+1 )的节点,可以通过该范围内的选取的k个节点来进一步定位,下图是一个“路由表”结构:


K桶:就是距离本节点最近的k个节点的信息的集合。K桶也称为”路由表“
节点之间的距离:2个节点id之间的异或值。
节点和键值(种子文件)的距离为该节点的id和该种子文件的info-hash(文件id)的异或结果
注意:这里只是一个举例,在实际的“路有表”中可能是没有160份,因为路由表的生成过程是对半分拆的,最初只有一个K桶(范围为:0—2160,且只包括自己,大概k的值为11,一般为8),在插如过程中当该K桶节点大于k(8)时,则分拆成两半,一半包括自身节点,一半不包括自身。循环往复下去,则形成一个动态的大小(1<=len(table)<=160)的“路由表”
每一个新加入到DHT网络的节点最开始这些“路由表”信息都是空的,它有以下几个方式可以来逐步生成和形成自己的“路由表”信息:
1) 如果本节点曾经启动过,则从保存的“路由表”文件中直接读取然后刷新该“路由表“
2) 如果该节点第一次启动(比如新安装BTSpilits然后启动),并且该节点自带有“超级节点“则
通过这些“超级节点“来间接地生成自己的”路由表“(在Kashmir的某个版本中有一个文件保存这些”超级接点的信息“,BTSplits, BTcomet, eMules则内嵌有20多个)
3)如果第一次启动的节点没有这些所谓的“超级节点”(比如Mainline则没有这个功能),则它的路由表生成过程需要推迟到download文件过程。它会从它获取到的种子文件中提取nodes字段,该字段是做种子(支持DHT网络的种子)的时候生成的,一般nodes字段设置为该原始种子的ip和port,或者是做种子的节点离该种子的info-hash最近的k个节点。通过这些nodes字段中的节点来间接地生成自己的路由表。
4)动态建立过程,该过程为节点经过上面的初始化后,在下载或者上传或者无任务过程中有收到任何节点发送的任何消息,都会去检查当前的“路由表”并尝试按照一定的规则去建立/刷新路由表。
我们知道DHT网络最主要的目标是替代Tracker(纯P2P网络,无traker)或者说作为Tracker的一个备份(混合型P2P网络,当前基本所有主流文件分享的应用都是该类型)。而Tracker最主要功能就是对每一个分享文件(种子)维护一个peers列表,然后告诉需要下载的询问者Client。实现的方法就是把Tracker集中维护的所有种子的peers-list信息利用DHT的方法散列并保存到所有的DHT网络中的节点上去,然后在此基础上提供查找的方法。“路有表”作用就是为了加速这个查找的过程的。在DHT实现中包括两种类型的查找,一种是查找nodes(find_nodes),另一种是查找peers(get_peers)。查找nodes的过程主要是为了建立本地的“路由表”,它的最终目的是后面查找peers。
查找节点的过程大概是这样:如果节点x需要查找节点y,则x首先从**xor(x,y)**对应的本地K桶中得到k个比较closer的节点,然后向这些比较close的k个节点继续询问它是否有离y更近的节点,这些k个节点当然也从自己的对应的K桶中返回k个和y更近的节点给x,x然后再从返回结果中选取k个更more closer节点重复上面的动作,直到不能返回更近的节点为止,则最后找到的k个节点即为the most closest nodes,在这个过程中返回的任何k个close的节点都会尝试去插到自己的路由表中去。
查找peers-list的方法和上面查找节点的方法类似,不同的是它是以info-hash作为参数进行查找xor(x,info-hash),并且如果在查找过程中有任何一个节点返回了(info-hash, peers-list)对则提前结束查找。当一个节点通过上面方法得到了peers-list后,则会试图对每个peers主动发起TCP的连接继续后面真实的下载过程(该过程由peer-peer protocol协议规定),同时会把自己的peer信息发送给先前的告诉者和自己K桶中的k个最近的节点存储该peer-list信息。该信息在该k个节点上可以保存24个小时,24小时后如果没有收到x发送的更新消息,则失效。因此,一个活动的节点存储有两部份的信息,一部分是本地的“路由表”,另一部分则是(info-hash, peers-list)列表信息(可有多个)。Info-hash的值当然也属于(0-2160)空间的一部分,但是它和节点id不同,节点ID是可以作为那棵无形的二叉前缀树的叶子(为什么是无形的,因为每个节点其实是没有用数据结构来存储这个棵的树的),而info-hash则只能附着在离它的值最近的node id上面。
三、kademlia消息
1.KRPC操作和查找过程
为了实现上面的“路由表”建立,刷新,获取peers-list,保存peers-list这些功能,kademlia定义四个最基本的KRPC操作:
(1)ping操作,作用是探测一个节点,用以判断该节点是否仍然在线。
(2)store操作,作用是通知一个节点存储一个
(3)find_node操作,作用是从自己的“路由表”对应的K桶中返回k个节点信息(IP address,UDP port,Node ID)给发送者
(4)faind_value 操作,作用是把info-hash作为参数,如果本操作接收者正好存储了info-hash的peers则返回peers list,否则从自己的“路由表“中返回离info-hash更近的k个节点信息(同find_node过程)。
上面只是最基本的操作,一次nodes或者info-hash的查找lookup过程则需要节点进行若干次上面的find操作的,一个递归查找的过程。利用上面的操作更精确的描述一次一个节点x要查找ID值为y 的节点, 过程如下:
1、 计算到y距离:d(x,y) = x⊕y
2、 从x 的第[㏒ d]个K 桶中取出α 个节点的信息(各个实现α值不一样,有些是3有些则等于k值),同时进行FIND_NODE 操作。如果这个K 桶中的信息少于α 个,则从附近多个桶中选择距离最接近d 的总共α个节点。
3、 对接受到查询操作的每个节点,如果发现自己就是y,则回答自己是最接近y的。否则测量自己和y 的距离,并从自己对应的K 桶中选择α 个节点的信息给x。
4、 x对新接受到的每个节点都再次执行FIND_NODE 操作,此过程不断重复执行,直到每一个分支都有节点响应自己是最接近y的,或者说FIND_NODE操作返回的节点都已经被查找过了,即找不到更近的节点了。
5、 通过上述查找操作,x 得到了k 个最接近y的节点信息。
注意:这里用“最接近”这个说法,是因为ID 值为y 的节点不一定存在网络中,也就是说y没有分配给任何一台电脑。
查找peers-list的过程则换成find_value动作,但注意前文提到的区别即可以有类似的描述。
2.操作消息格式
上面的四个操作在BT-DHT的实现上则进行了重命名,定义了如下四类信息,它们叫作KRPC(K代表Khashmila/Kademlia),通过udp进行发送,一个请求一个响应或者错误。
1) Ping(和Kademlia同名同功能)
Beconded(以BitSprits为例)
Ping Request格式:
d1:ad2:id20:xxxxxxxxxxxxxxxxxxxe1:q4:ping1:t4:tttt1:y1:qe
表示的含义:此操作为ping操作请求,参数为发送者的id是:xxxxxxxxxxxxxxxxxx
Ping Reponse格式:
d1:rd2:id20:yyyyyyyyyyyyyyyyyy e1:t4:1:y1:re
返回的数据中只包括有一个响应者的id信息。
(2) find_node(和Kademlia同名同功能)
Beconded(以BitSprits为例)
find_node Request格式:
d1:ad2:id20:xxxxxxxxxxxxxxxxxxxx6:target20:yyyyyyyyyyyyyyyyyyyy1:q9:find_node1:t4:1:y1:qe
表示的含义:此操作为find_node请求,参数为发送者id及目标节点的id
find_node Reponse格式:
d1:rd2:id20:xxxxxxxxxxxxxxxxxxxx5:nodes208:nnnnnnnnnnnnn5:token20:ooooooooooooo1:t4:ttt 1:y1:re
表示的含义是:找到了8个最近的节点,nodes208表示8个node信息(ip,port,id)共208Bytes
(3) get_peers(对应Kademlia中的find_value消息)
Beconded(以BitSprits为例)
Get_peers请求格式:
d1:ad2:id20:xxxxxxxxxxxxxxxxxxxx9:info_hash20:zzzzzzzzzzzzzzzzzzzze1:q9:get_peers1:t4:tttt1:y1:qe
表示的含义:此操作为get_peers操作请求,参数为:发送者的id和要查询种子的info-hash。
Get_peers响应格式有两种,一种是找到了节点含有该info-hash的peers列表信息,如下格式:
d1:rd2:id20:xxxxxxxxxxxxxxxxxxx5:token20:ooooooooooooooooooo6:valuesl6:(ip1,port1)+(ip2,port2)+(ipi,porti)…e1:t4:tttt1:y1:re
(values后面跟上的则是peers列表,ip, port)
另一种是没有找到列表信息,如下格式:
d1:rd2:id20:xxxxxxxxxxxxxxxx5:nodes208:nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn 5:token20:ooooooooooooooo1:t4:tttt1:y1:re
没有找到存有info-hash的节点,但找到了离该info-hash更近的8个节点,nodes208表示8个node信息(ip,port,id)共208bytes
(4) announce_peer(对应Kademlia中的store消息)
Beconded(以BitSprits为例)
announce _peers请求格式:
d1:ad2:id20:xxxxxxxxxxxxxxxxx9:info_hash20:zzzzzzzzzzzzzzzzzz4:porti10756e5:token20:ooooooooooooooooo1:q13:announce_peer1:t4:tttt1:y1:qe
表示的含义是:此操作为announce_peer请求操作,告诉对端我这边对info-hash文件上传和下载,可以成为peers list中的一员,端口号是10756.
Announce_peer Reponse格式
d1:rd2:id20:xxxxxxxxxxxxxxxxxxxx2:ip4:pppp1:t4:tttt1:v4:UTb*1:y1:re
附件为抓取的分别为为一简单下载过程/一初始初始化路由表的数据包:可以对照进行分析
四、Bttorent DHT实现几个重要过程
1.种子制作
1)./maketorrent-console参数use_tracker设置为false,则不会产生announce tracker字段
2) 读取本地“路由表”文件,并从中找出k个离info-hash最近的节点,作为nodes字段
2.启动过程
routing_table文件的格式:
{'id':node.id, 'host':node.host, 'port':node.port, 'age':int(node.age)}
1) 从“路由表”文件中装载之前保存的”路由表”K桶信息,初始化内存“路由表”信息
2) 强制刷新“路由表“中的每一个K桶,刷新过程是随机产生一id进行findNode查找。
3.刷新路由表的过程
1) 启动的时候进行强制刷新
2) 每15分钟如果K桶中的信息没有进行更新的话,则进行刷新一次K桶,即refreshTable
3) 每5分钟进行一次checkpoint操作,以把当前的路由表存放到“路由表“文件中
有些实现是用SQLite数据库来实现这部分功能的。
每一个“路由表”的K桶都有一个“最近更新时间“属性,当收到该桶中任何节点的ping响应,或者有任何节点被加入或者被替换,则该属性都需保持更新,并且重启一个15分钟的定时器,如果定时器超时(15分钟内该K桶节点没有任何更新操作),则会对该K桶进行一次refresh操作,操作的过程是从该K桶范围选出一随机的ID,然后对该ID进行find_node操作。“路由表”中的节点需要保持live状态,即得保证没有离线,如果向路由表中的一节点发出的连续3次请求都没有收到响应,则认为该节点失效。
refreshTable(force=1)过程:
(1) 如果force=1,则对当前每个K桶都进行刷新
(2) 如果K桶当前nodes数小于k(8),则也进行刷新
(3) 如果K桶中存在无效的节点,即连续三个消息没有收到响应的节点
(4) 如果K桶中所有节点没有交互的时间超过15分钟,则也进行刷新
当一个节点收到任何一个RPC消息(请求和响应)后(ping/find/getPeers/announce_peer)都会去检查一下该消息的发送者是否在本地的“路由表“中,如果该发送者已经存在节点的本地“路由表”中,则会把该发送者从其对应的K桶移动到该K桶的末尾。如果该发送者不在节点的“路由表”中则会去尝试插入到本地”路由表“K桶中,这也是“路由表”的动态建立过程的一种,过程如下:
(0) 找到该发送者的对应的K桶
(1) 如果该节点是响应消息中发现的,则更新该节点lastSeen = time()时间
(2) 如果该K桶大小小于k(8)则直接插到该K桶后面
(3) 如果该K桶已经满了,则检查是否有无效的节点,如果有则把这些无效节点删除,并把该节点放入K桶末尾。(但后面会对这些早已经存在的节点进行再一次的ping操作,来进一步确定是否无效了,如果收到响应,则把这些节点重新放如K桶)
(4) 如果该K桶已经满了,并且所有的节点都是有效的,则需要查看自身(本客户短)是否在该K桶中(即该K桶是否是自己所在的K桶),如果不是则直接丢弃该节点
(5) 如果该K桶不是自身所在的K桶,则需要进行K桶分拆。拆分的方法即是一个变为两个等长K桶,一个包括自身,一个不包括。
(6) 对该节点添加到分拆后的一个K桶中去。
4.findNodes(id, invalid=True)的过程
/该过程是内部过程,给下面findNode(
(0) 如果该节点在自己的K桶中,则直接返回,结束该过程
(1) 如果invalid=True,则需要排除当前无效的节点
(2) 如果上面选取该K桶中的所有节点小于K(8),则需要从其他桶中补充,如下:
把左右相邻的两个K桶中的节点补充进去,然后把所有这些节点按照离id距离远近进行排序,选取最近的K(8)个节点,返 回最后得到的最近的K个节点。
5.findNode(id)的过程是
(1) 从自己本地的“路由表“取离id最近的K桶,返回k(8)个nodes信息
(2) 从上面k个信息中选取a个(3)个,然后发送findNode消息给这3个节点
(3) 该3个节点查找自己的“路由表“同时返回k个nodes信息
(4) 从上面得到的3*k个节点在重复
6.Keyexpired过程
1) 节点存放的(info-hash,peers-list)如果24小时没有收到原节点的更新则视作无效
2) 当前仍然活动的peer-lists中的节点需要24小时向其close节点进行刷新info-hash,peers-list。
3)当前仍然活动的peer-lists中的节点如果在自己的路由表中发现有离info-hash更近的节点,则会把自(info-hash,peers-list)announce给它们。
7.getPeersAndAnnounce过程
在BT程序中,对外只有一个过程,那就是下面的getPeersAndAnnounce过程,该过程的作用就是对提供的info-hash找到一个peers list表,并且把自己作为一个peer告诉给别人:
(0) 该过程包括了getPeers和Announce_peer两个过程
(1) getPeers的过程首先是在自己的本地的(info-hash, peers-list)表中进行查找,如果查找到则直接进行连接
(2) 如果本地没有info-hash的key,values,则需要进行远程查找,查找的过程是
-
先从info-hash对应的K桶中找k个节点,然后分别向它们发送getpeers原始RPC消息
-
分析上面k个节点的响应信息,如果响应信息中存在values字段,则说明命中一个节点,该节点保存有info-hash的peers-list信息,保存起来。如果响应消息中只有nodes字段,则该字段后面跟上的是k(8)个更接近于info-hash的节点,判断这些节点是否发送过,如果没有则把这些节点保存起来继续发送getPeers RPC消息,直到收到响应消息中带有values字段,或者响应消息中所有的节点都发送过了(没有更接近info-hash的节点了)
-
当收到节点对get_peers响应包中包括有(info-hash,peers-list)后,则首先向响应者发送announce,然后向自己K桶中离info-hash最近的k个节点发送announce_peer消息
8.Ping消息的发送过程
1) 对于DHT种子文件中nodes逐个节点发送ping消息,有响应者则添加到“路由表”中去
2) 当插入新节点到“路由表”中时,如果该“路由表”K桶已满,则会选择K桶的头部节点进行ping操作,如果该头节点仍然在线,则直接丢弃该节点(这是基于一种越长时间在线则可能以后越长在线的概率统计),否则删除头节点,并把新节点插到K桶尾。
官方网站:http://www.tribler.org/trac/wiki/Khashmir